AI算法基础 [2]:NC4HW4数据排布
前言
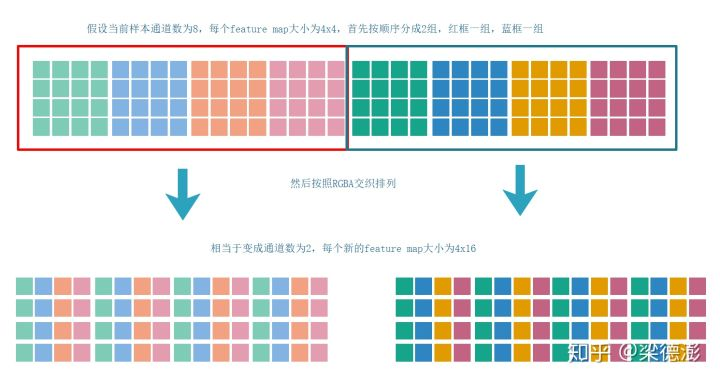
- NC4HW4的数据排布其实就是和RGBA这种交织的数据排布类似
NCHW->NC4HW4
- 首先batch维度就是N不变
- 然后把每个样本所有feature map按每四个通道为一组分成C/4个组,如果通道数不能整除4则补齐到4的倍数,补上的feature map全填0
- 然后把每组内的4个feature map按照RGBA交织的形式重新排列一下就得到NC4HW4的数据了。
优点
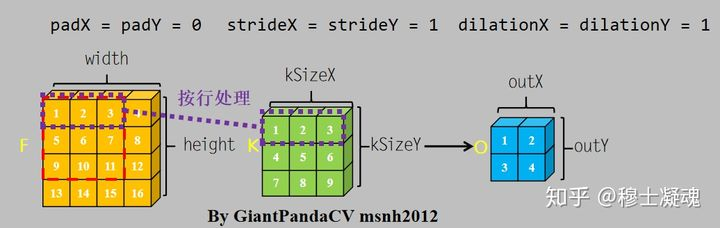
- 以卷积操作举例,此处只讨论暴力方法,不涉及im2col,gemm, winograd等方法。
- 对于卷积操作, 根据计算机内存排布特点,按行进行处理,处理完一个通道的数据,转入下一个通道继续按行处理。下图是一个通道内卷积的操作:
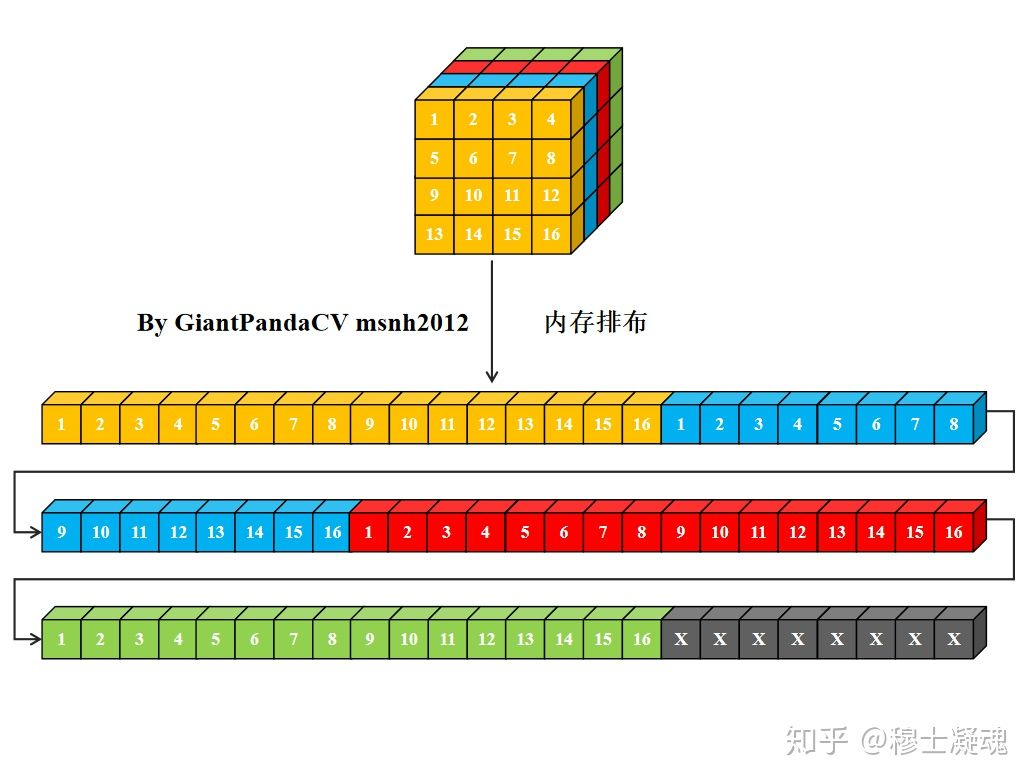
- 对于一个nchw格式的Tensor来说,其在计算机中的内存排布是这样的:
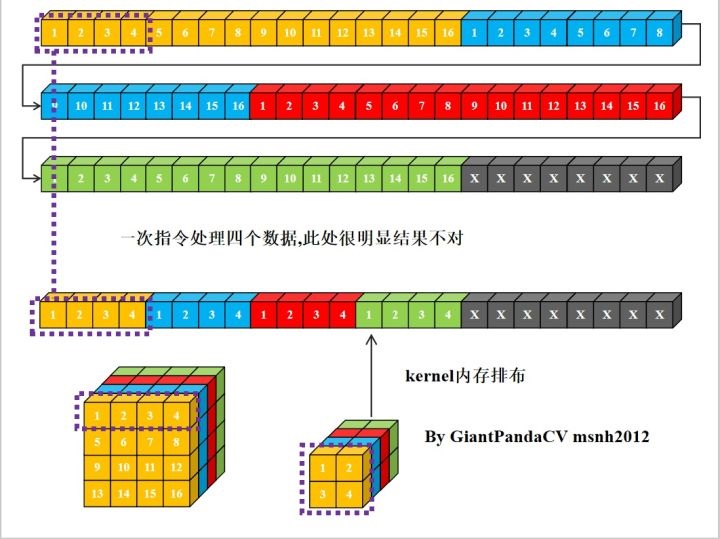
- 当一条指令处理一个数据时,卷积操作需要做循环乘累加,如下图所示,与kernel对应的featuremap中的数据不是连续分布的。如果feature map空间size很大的话,这样跳通道取数据,就会造成cache miss严重影响运行性能。
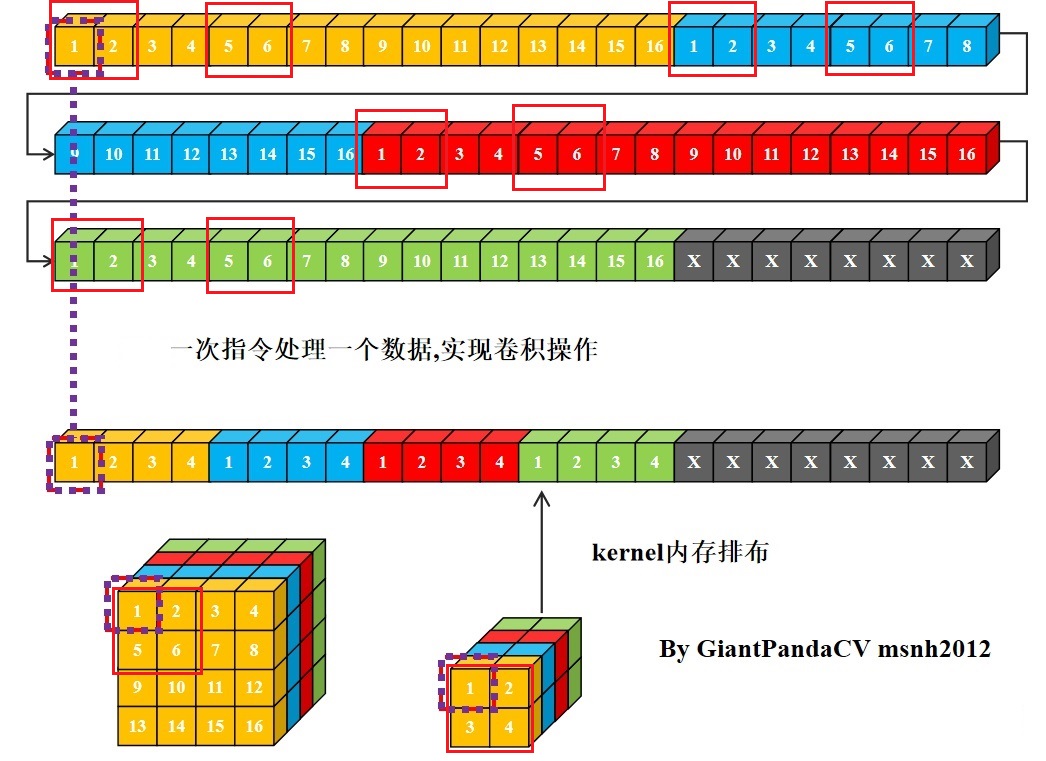
- 除此之外,当kernel size 不为4的倍数时,想使用诸如x86结构的sse指令,arm的neon指令.以及GPU的OpenGL和OpenCL等可以单指令处理4组数据的指令集时,使用nchw内存排布同样不方便:
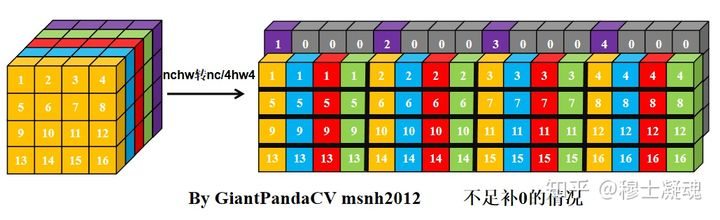
- 而NC/4HW4则可以解决上面的问题,4个通道合并成一个通道,通道数不足4的情况下进行补0:

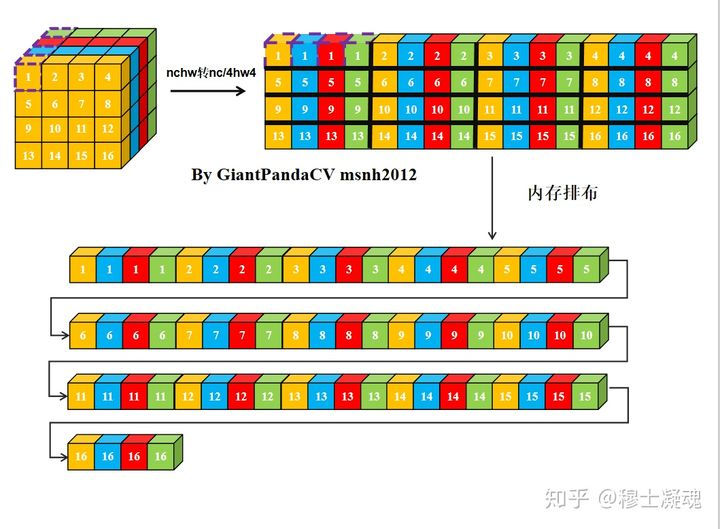
- 经过NC4HW4重排后在内存中的排布情况如下:
- 此时进行单指令处理4组数据(SIMD)操作就没有问题了
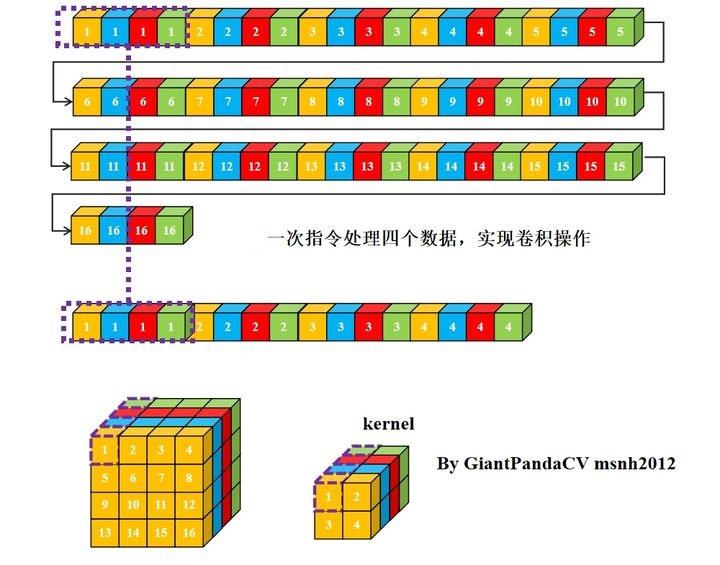
- 注意此时如果想让输出也为NC/4HW4排布,则需要在以4组kernel为单位循环操作featuremap数据,以实现输出channel的pack。
总结
优点
- 进行NC4HW4重排后,可以充分利用cpu指令集的特性,实现对卷积等操作进行加速。同时可以较少cache miss.
缺点
对于较大的feature,如果其channel不是4的倍数,则会导致补充0过多,导致内存占用过高,同时也相应的增加些许计算量。
参考
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 旭穹の陋室!
 wechat
wechat alipay
alipay
相关推荐



评论
![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)