AI算法基础 [8]:MNN中的ConvolutionTiled实现
前言
一般卷积,主要针对CPU后端,基于/source/backend/cpu/compute/ConvolutionTiledExecutor.cpp源码展开。
以下面的数据输入为例,由于
kernelX != kernelY,因此Strassen和Winograd均不适用。input:
1 x 8 x 224 x 224,C4 Pack格式为:1 x 2 x 224 x 224 (x 4)weight:
16 x 8 x 3 x 5output:
1 x 16 x 222 x 220,C4 Pack格式为:1 x 4 x 222 x 220 (x 4)没有特殊说明,代码版本均为MNN release_1.1.7版本,release_1.2.3版本已经将ConvolutionTiledExecutor的部分实现融合到了DenseConvolutionTiledExecutor.cpp中
权重重排
static void _initWeight(float *dest, const float *source, float* cache, int depth, int outputCount, int kernelSize, const CoreFunctions* function) { |
权重重排分两个步骤:
-
MNNTranspose32Bit:逐个卷积核遍历,执行转置操作,转置后尺寸为16 x 15 x 8。
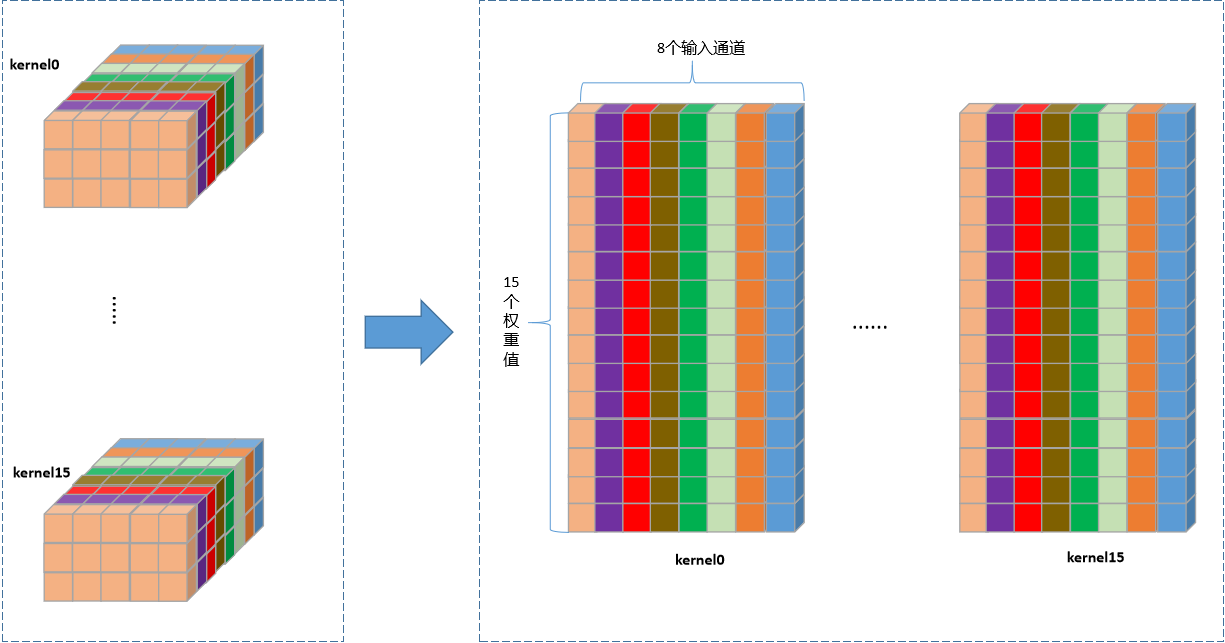
-
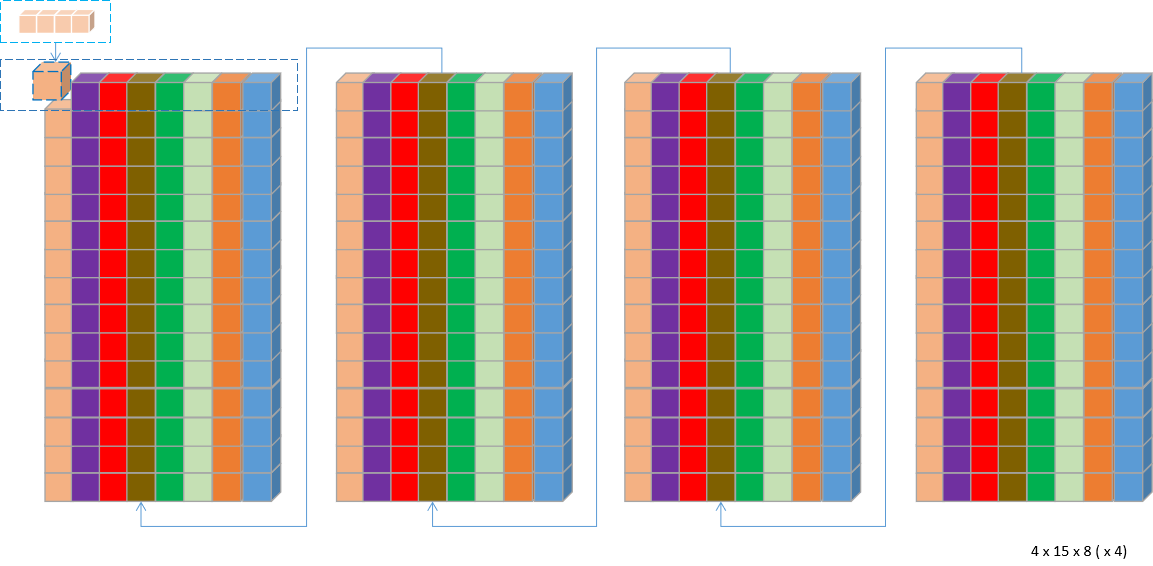
MNNPackForMatMul_B:对转置后的卷积核进行C4 Pack,16 x 8 x 3 x 5重排为4 x 15 x 8 (x 4)。
OnResize
数据分块
假设ePack= 24,对于输出而言,单个FeatureMap的24个输出数据作为一个tile,映射回输入FeatureMap中,按照卷积的运算流程,实际需要的输入数据量为ePack * IC * kernelX * kernelY 。每个tile是独立的,分块后可以进行多线程并行计算。
下图是单个通道的输入和输出FeatureMap计算中数据依赖关系:
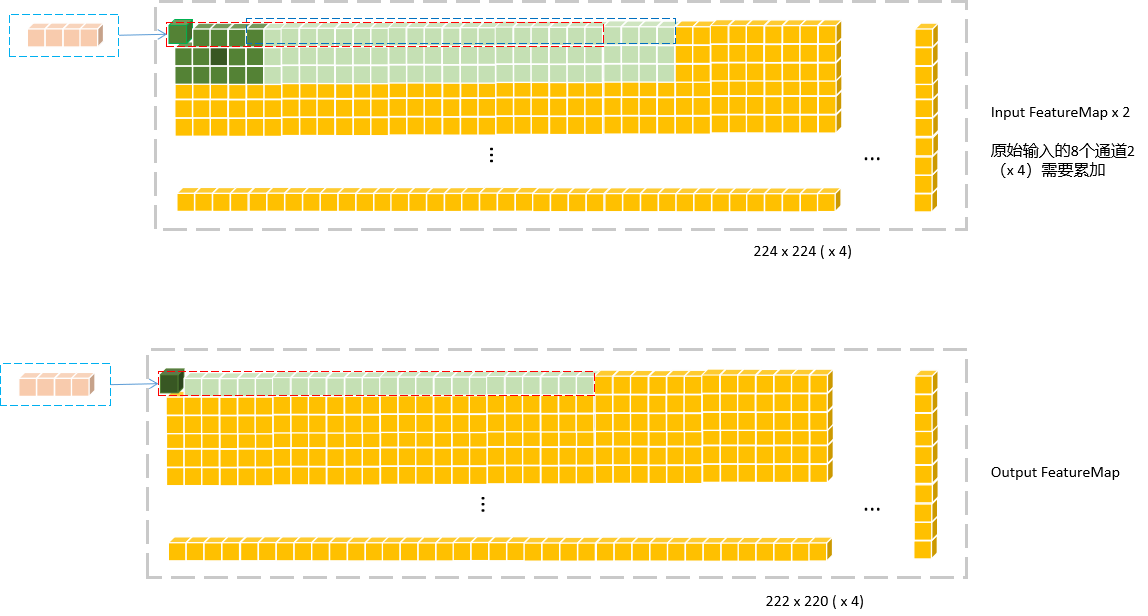
为了获得完整对应到一个tile的输入数据,要对输入数据进行重排,这个在后面展开。
对于跨两行的
tile,MNN将其分为两部分处理,比如示例中第一行最后一个tile分为(4 + 20),这一部分处理没有使用指令集load和save,见_AVX_MNNPackC4ForMatMul_A()中else部分代码,这或许是一个可优化的点。
buffer分配
有上图可知,要计算24个C4 Pack的输出数据,参与MatMul + Add 的输入数据量为ePack * IC * kernelX * kernelY。这一部分内存对每一个tile而言是可以复用,因此可以事先分配好。源码如下:
mTempBufferTranspose.buffer().type = halide_type_of<uint8_t>(); |
以约定尺寸为例,对于单线程,数据元素长度为1(uint8)的情况,gemmBuffer的尺寸为1 x (15 x 8 x 24) x 4 Bytes。其中1代表线程数,24代表一个tile的大小,4代表C4 Pack,15代表卷积核尺寸3 x 5,8代表输入通道数,15 x 8个数值需要累加到一起作为单个卷积核的卷积输出。
另外一个临时buffer tempPtr用来保存15个权重坐标的位置指针及一些位置参数,方便后面重排时加载数据。
auto tempPtr = bufferAlloc->alloc(kernelSize * maxLine * threadNumber * (4 * sizeof(int32_t) + sizeof(float*))); |
输入重排
将单个tile的输入重排后存入gemmBuffer中,供后续MatMul使用。重排实现代码详见_AVX_MNNPackC4ForMatMul_A。这部分的原理与Winograd和Strassen中使用的输入变换是一样的。这里不再展开。重排后数据内存排布如下图:

MatMul+Add
权重和输入根据上面重排后,乘加运算只需按行做MatMul,最后逐行累加即可。示意图如下:
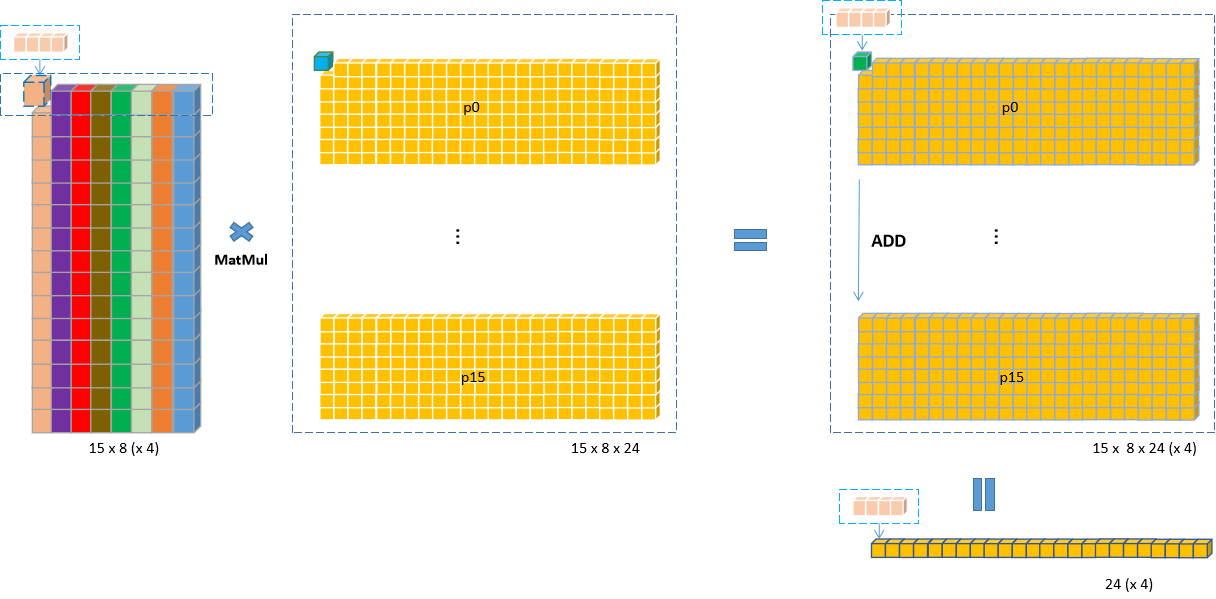
-
- 输入图中的每一行(一个通道的24个值)对应权重图中的一个
C4 Pack,一行中的每个元素都跟C4 pack中的4个值相乘,得到24个C4 Pack。
- 输入图中的每一行(一个通道的24个值)对应权重图中的一个
-
- 8个通道,15个卷积权重全部循环完得到
15 x 8 x 24 (x 4)的乘法输出;
- 8个通道,15个卷积权重全部循环完得到
-
- 所有行累加得到4个卷积核相对于1个输出
tile的最终输出24 (x 4);
- 所有行累加得到4个卷积核相对于1个输出
-
- 外层再循环遍历完所有的卷积核,便可得到1个
tile都卷积输出4 x 24 (x 4)。
- 外层再循环遍历完所有的卷积核,便可得到1个
实现代码详见_AVX_MNNPackedMatMulFMA以及_AVX_MNNPackedMatMul_Main,原理与Winograd和Strassen中的乘加操作一样。不再展开。
后处理
AVX2GemmPostTreat原理与Winograd和Strassen中的后处理操作一样。不再展开。
onExecute
执行时调用onResize中的回调函数。
ErrorCode ConvolutionTiledExecutorBasic::onExecute(const std::vector<Tensor*>& inputs, |
致谢
文章主体框架参考自东哥的MNN源码解读的内部分享,加上了自己的一些看法。有幸被看到的话,希望能给点个赞~~
 wechat
wechat alipay
alipay






![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)