海思AI开发 [4]:NNIE Mapper 模型转换问题记录
问题1 pooling层尺寸不一致
pooling层输出尺寸的计算公式如下:
当不能整除(输入或卷积核为奇数)时,pytorch默认是floor,而caffe默认是ceil,因此会出现onnx2caffe转换后输出尺寸比pytorch大1的情况。
解决办法:Slice层切割pooling层的输出
-
如果训练端发现该问题,可以pytorch的pooling设置为
ceil_mode=True -
如果部署端发现该问题,不想重新修改模型retrain,则需要手动修改prototxt
- 首先,不能采用将padding置为0的方式,虽然能获得相同的size,但计算方式会发生变化,实测也是会出现掉点的。具体可以看下图;

- 从上图可以看到,可以将caffe ceil模式输出的结果的最后一行和最后一列切掉,从而获得与pytorch相同的输出;
- 最后,其实也可以修改caffe端pooling层为
floor模式,但在当前情景下,caffe只是作为中转,还要转换到nnie模型,可能还会出现不匹配的情况,故这里不适用。
代价:无效输出增多
由于slice分割了pooling层的输出,故每次slice都会产生一个无用的tensor输出(最后一行/列),nnie每个模型seg的最大输出个数为16(hi_nnie.h中定义了#define SVP_NNIE_MAX_OUTPUT_NUM 16),故如果有些模型slice加的多,还得将这些无用输出合并成一个。
问题2 不支持relu6
解决办法:多个op组合进行替代
relu6即在relu的基础上,将最大值钳制到6,图像如下:
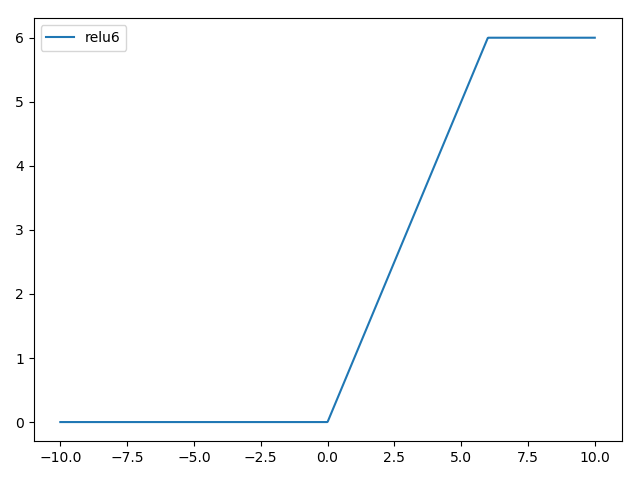
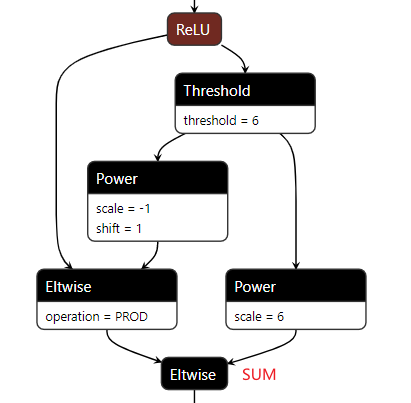
caffe和nnie没有现成的op支持,如非用relu6不可,可以用几个caffe支持的op组合进行代替,公式如下:
- 阈值判断用
threshold,乘和偏置作可以用power,tensor相加的操作可以用eltwise,具体组合方式见下图
衍生问题:Power 层shift=1.0无法正常加1
上述转换验证onnx->caffe模型是可以正常转换的,但再转换到nnie模型时出了问题;
测试发现nnie的power op 无法正常执行shift=1.0的偏置操作,上图左边的power算子的输出应当是0和1的mask,结果却输出的是-1和0,遂做了以下测试:
- 当
shift=2.0时,可以正常加2; - 当
shift=1.1时,可以正常加1.1; - 当
shift=1.0001(或更小)时,可以正常加1;
故可以通过将shift设置为带上一个很小的余量规避上述问题(估计是精度舍入的问题),完成正常加1的操作;
与HISI的FAE沟通后得到的最终答案是,GPU版本的mapper工具确实存在bug,可以暂时使用CPU版本进行规避。
代价:由此带来的性能损失
测试自用人脸检测模型:
- 用上述op替换的方式实现relu6,量化方式设置为16bit,测试上板推理时间为162ms
- 不考虑精度变化的情况下,将relu6直接替换为relu,其他配置不变,测试上板推理时间为54ms
即增加的power、threshold 、eltwise等op带来了3倍的时间消耗
替代解决方案:训练端修正
训练端调整,不使用relu6
nnie op调试方法
(optional)自己构建单op模型
- 通过pytorch构建一个自己所要验证的单op模型,输出为onnx;
- 好处就是可以构建更纯粹的测试环境,摒除无关因素的干扰,可以自定义输入尺寸和值,更容易观察现象,模型转换,向量比较等操作也会更快;
- 通过
onnx2caffe脚本工程将onnx转换到caffe模型;- 实测python3.5 + onnx 1.6.0 + protobuf 3.16.0 + hisi caffe 环境 可以正常运行
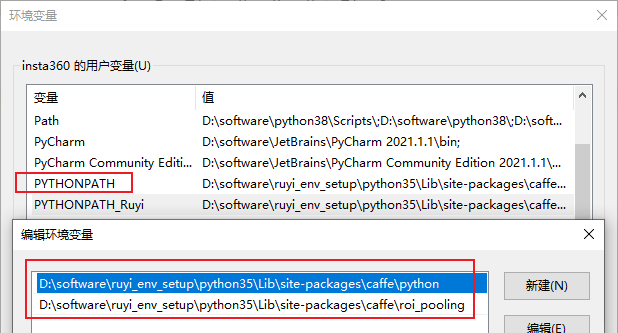
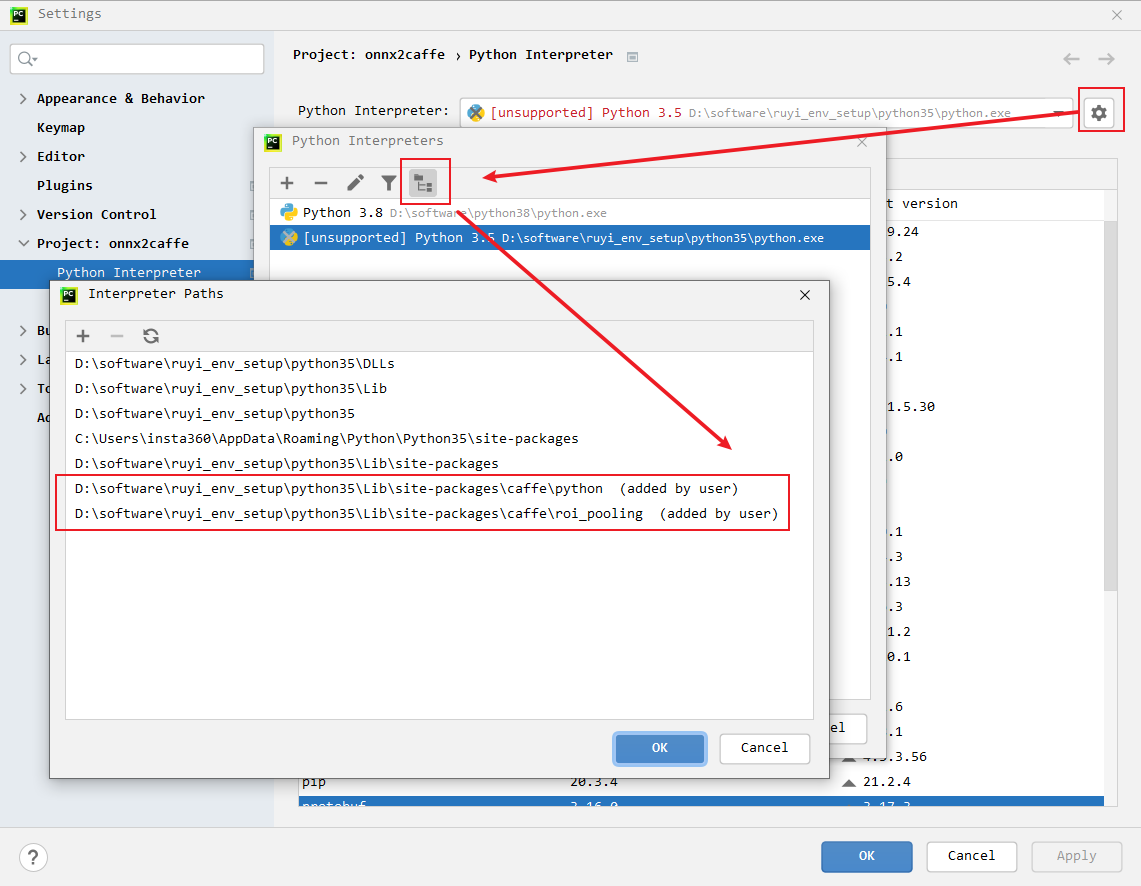
- 如果程序找不到caffe库,可以在环境变量中设置PYTHONPATH,或者在IDE(Pycharm为例)中设置搜索路径
获得nnie模型的推理结果
nnie mapper的设置如下图所示
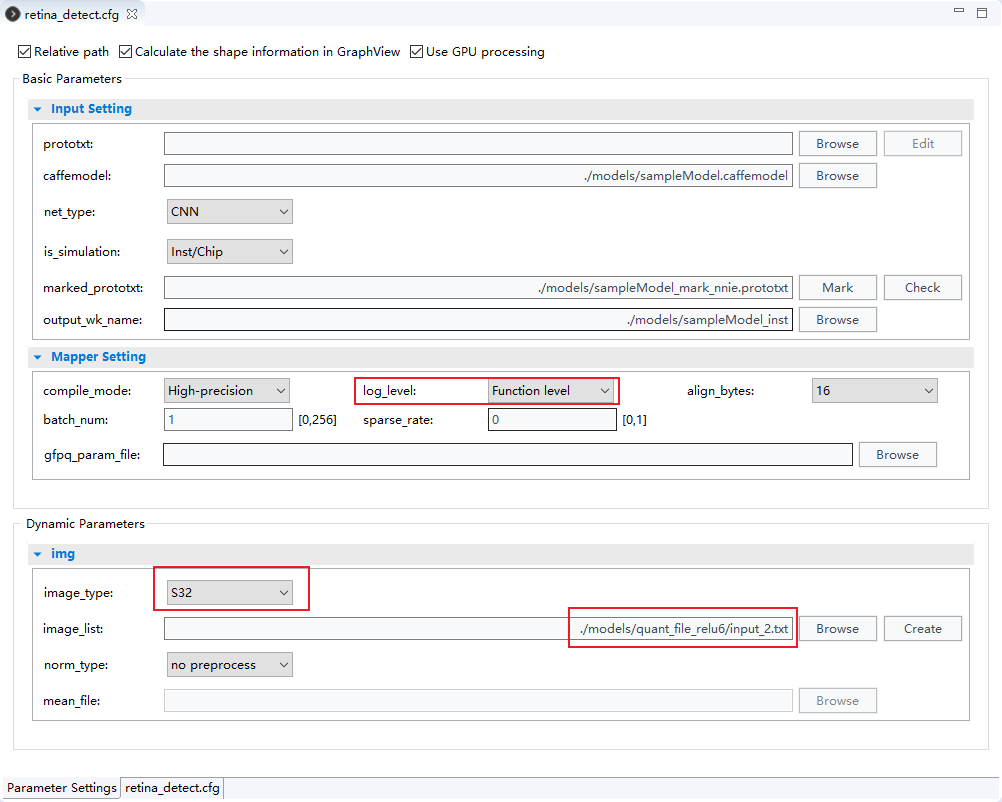
- 将
log_level设置为Function level,量化转换模型结束后会跑一遍推理,将推理的各层中间结果保存到工程目录的mapper_quant文件夹下; - 那么推理的输入是什么呢?是
image_list,如果list中只有一个图,那就是这个图,如果有多张图,会跑list中最后一张图; - 中间结果会保存为
*.hex格式的文件,每行一个元素,共该层的输出尺寸n*c*h*w行,元素用32bit定点数(20.12)的16进制补码表示,即高20位为整数部分,低12位为小数部分,至于补码到float数的转换,可以自行计算,也可以用vector comparison工具的转换功能; - 量化校正数据
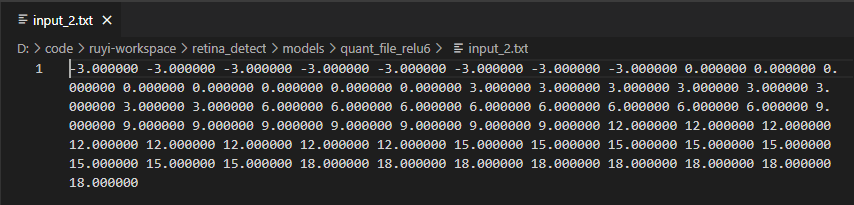
image_list可以是图片,也可以是自定义的tensor,即如图中所示,将image_type设置为S32,image_list为张量文件,张量文件中一个完整的张量(c*h*w个点)为一行,以浮点文本表示,点与点之间以空格或逗号分割。如下图所示(查看开了自动换行,实际为1行)
获得caffe模型的推理结果
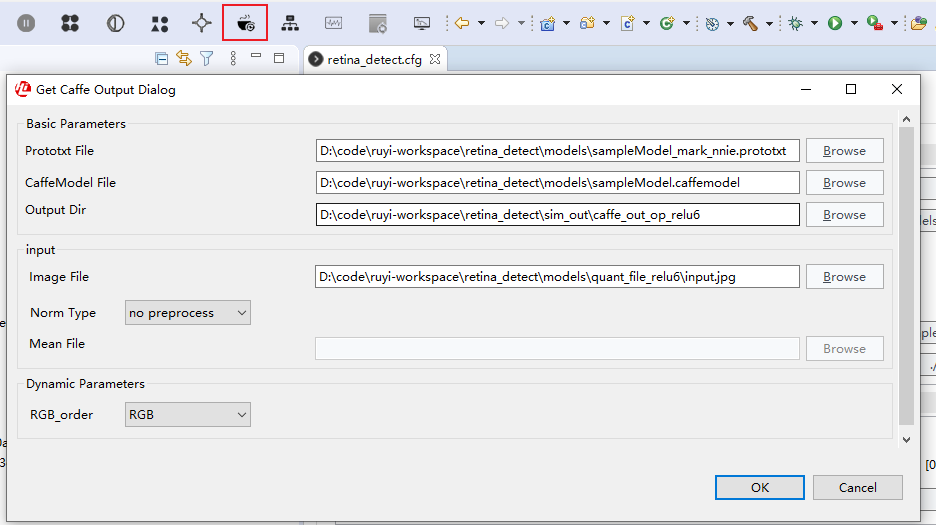
- 工具如图进行配置,关键预处理方式与nnie mapper设为一致,则会将中间结果输出到指定目录
- 中间结果保存为
*.float文件,与*.hex一样,每行一个元素,共输出尺寸n*c*h*w行,但元素为用科学计数法表示的小数。 - 这个工具只能选择图像作为输入,如果要对比自定义tensor作为输入的结果则需要生成tensor对应的jpg,且选择合适的预处理以转化成原tensor,方便与nnie量化中间结果进行比较,理论上可行,但颇为不便,此处未做尝试。
- 此工具对应
RuyiStudio\Resources\pythonScript\cnn_convert_bin_and_print_featuremap.py脚本,也可以直接修改脚本,应该也可以实现自定义tensor作为输入,同样未做尝试。
对比不同模型的中间结果
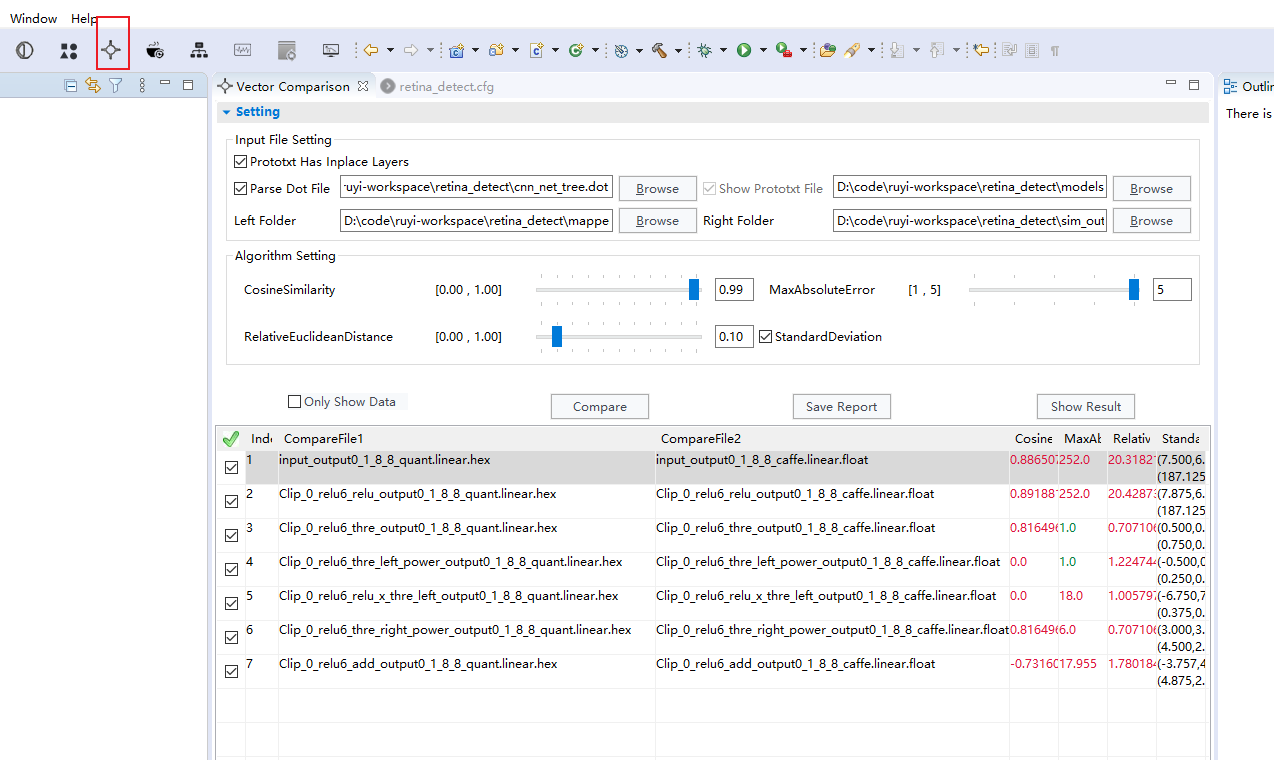
Prototxt Has Inplace Layers:如果prototxt中存在inplace写法(即为相互连接的几个层中,top是相同的,bottom是不完全相同的)则需要勾选,并选择相应的prototxt文件,这些层会被表示为一个框,一般通过nnie mapper的自动标记功能生成的*nnie_mark_*.prototxt会把合适的层组成inplace结构,应该是能优化性能吧。具体如下图;
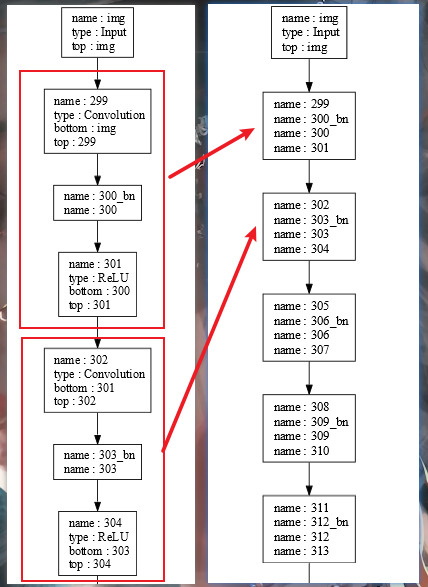
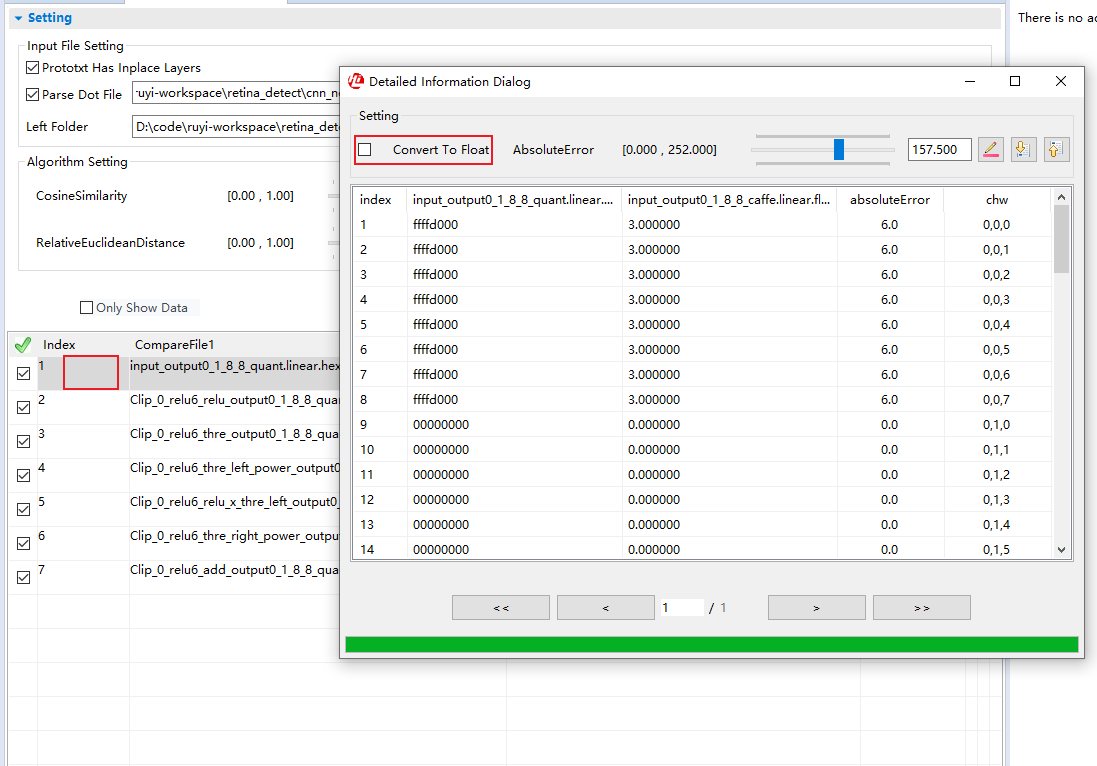
Parse Dot File:如果是对比的结果一个是caffe或nnie mapper的推理结果,另一个是仿真数据,则需要勾选并选择工程目录下生成的cnn_net_tree.dot文件,以进行层的匹配;Left Folder/Right Folder:选择要对比的两个文件夹,注意nnie mapper的中间结果会非常多,很多都是不需要的,可以根据caffe结果的文件名筛选出对应的文件单独放到另一个文件夹下,否则单是读取文件的时间就会慢到让你崩溃(因为它会一边读文件,一遍进行层匹配);Algorithm Setting:是一些误差参数的阈值设定,超过阈值的会被标红,默认就好;- 点击
Compare,比较向量相似度,一般看余弦相似度CosineSimilarity,大于0.99一般问题不大,0.95-0.99之间有点问题,0.95以下就可能会导致比较严重的掉点了; - 点击
Show Result:会将误差标注的拓扑图上,并用颜色区分严重程度,方便定位哪些层问题问题比较大; - 双击需要查看的行,会弹出每个元素对比的窗口,这里有个比较好用功能就是
Convert To Float,当你不知道怎么从补码转换到float时,这里可以给你一个参考,但不建议双击尺寸较大的行,加载的速度慢到怀疑人生;
- 对比看什么呢?
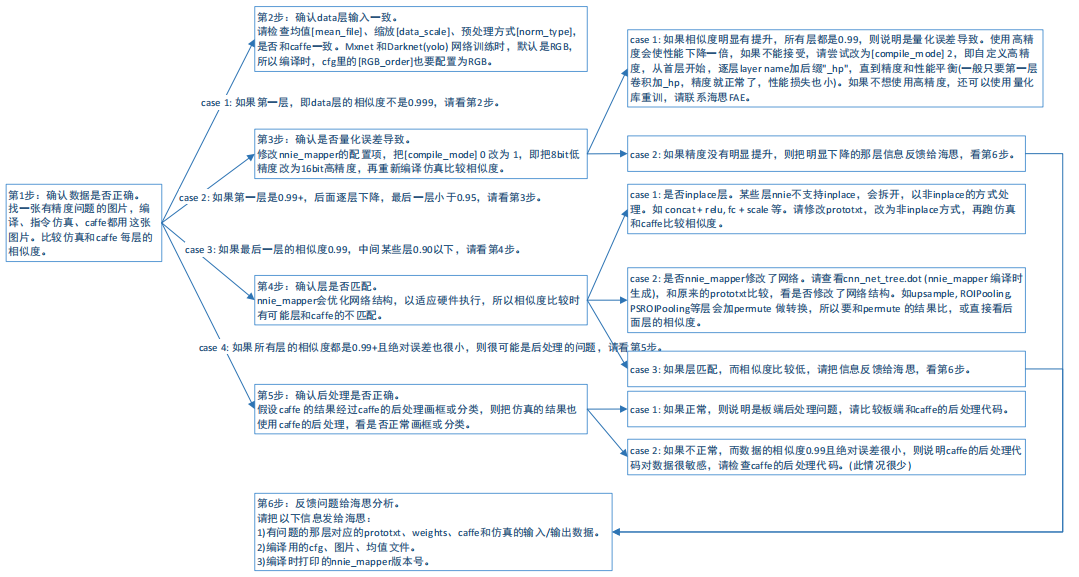
问题3 low-bandwidth 量化精度下降
现象1:benchmark AP 下降明显
自用人车狗模型:
mnn结果

nnie-high-precision结果
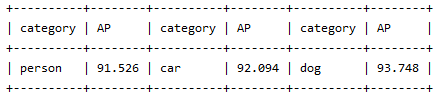
nnie-low-bandwidth结果
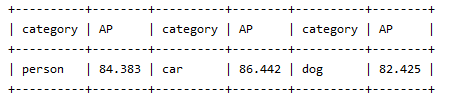
现象2:vector comparison 余弦相似度低
比较nnie-high-precision与caffe中间结果,余弦相似度 输入=1,后续各层均>0.99,下图展示了部分层的误差情况,灰色代表≥0.99
比较nnie-low-precision与caffe中间结果,余弦相似度 输入=1,后续出现下降情况,部分层降到0.9以下,输出层在0.95左右,下图展示了部分层的误差情况,橘色为0.95~0.99,红色为<0.95

解决办法:high-precision 精度恢复
如上所述,当把量化方式改为16bit的high-precision模式时,精度的下降在可接受的范围内(AP↓0.5%)
衍生问题:specify (FP16+INT8混合量化)无法达到预期的折中效果
按照上面精度问题的定位步骤图中第3步-case1的建议,做了如下尝试
- 将第一个卷积层置为
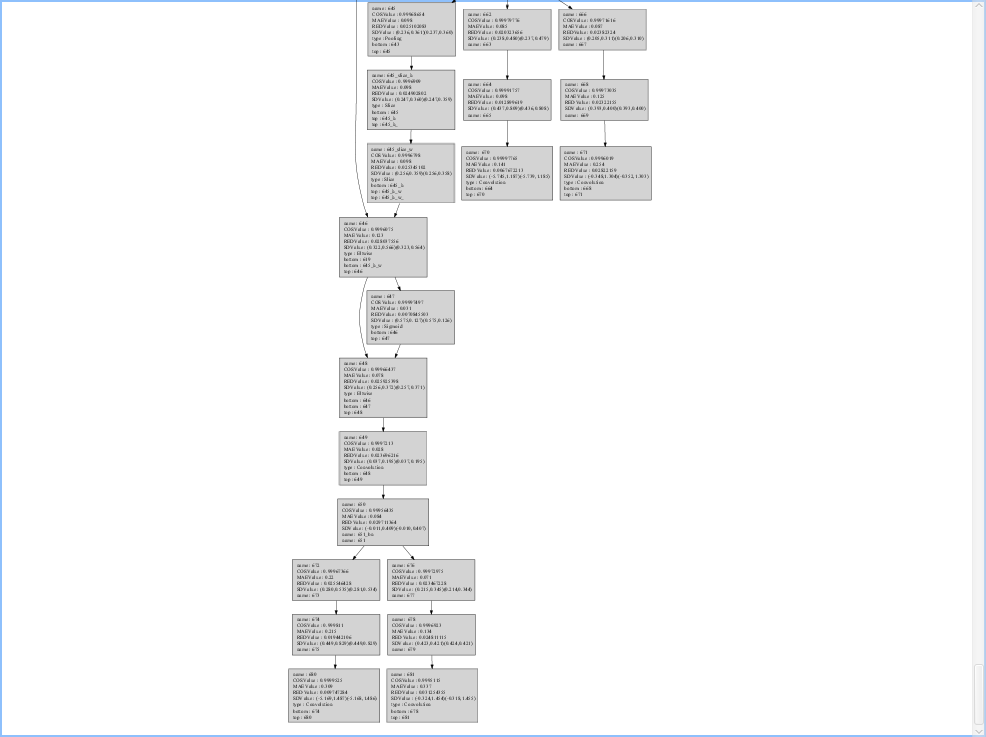
_hp:AP和向量相似度有一点提升,但不明显 - 从前往后逐层置为
_hp:首先,实测像bn,relu这样没有权重的层,即使设为_hp也没有影响,且通过Ruyistudio的Graph View工具看到的Layer Info,这些层也没有High precision layer参数(见下图),侧面印证了这一点。其次,当把第二个卷积层(437)置为_hp后,就出问题了,该层的余弦相似度降到0.81,后续所有层的余弦相似度都断崖式下降。
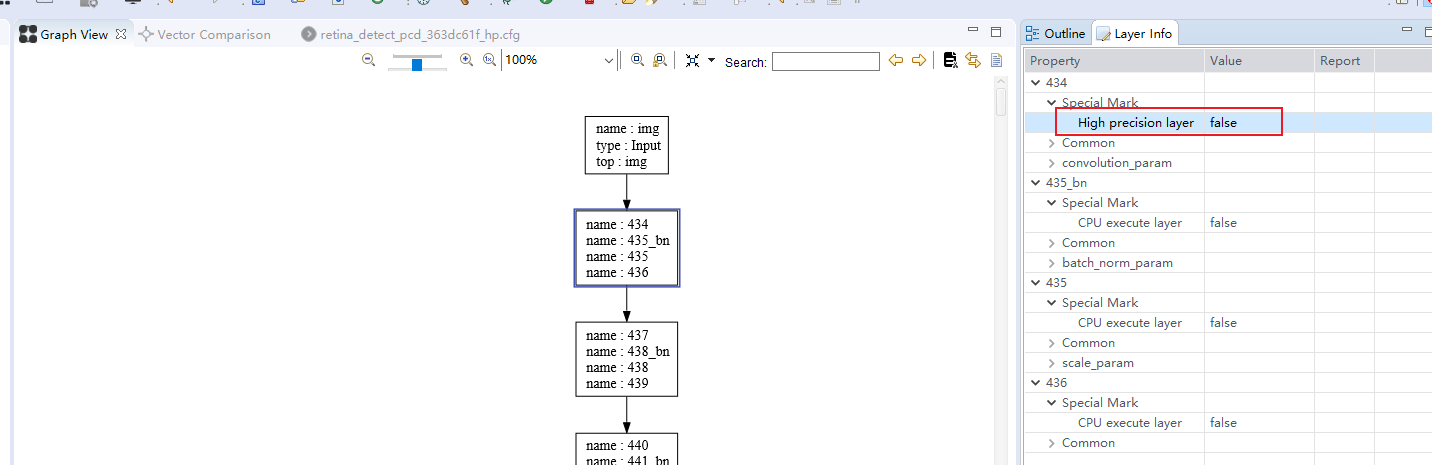
- 所有层(带
High precision layer)全部置为_hp:理论上该操作应当与compile_mode=High-precision获得同样的结果,但是却与上面第二点类似,从437开始,精度断崖式下降。尝试在此基础上,把437踢出_hp的队伍,发现,精度从445开始出现断崖式下降。再把445踢出_hp队伍,又从453开始重蹈覆辙。后面还是历史的轮回,没有再进一步验证。
代价:由此带来的性能损失
目前采用16bit量化模式可以解决精度问题,但带来了性能的损失,实测自用人车狗模型的推理时间由20ms->30ms
替代解决方案:FP16+INT8混合量化
specify的bug定位到了,hisi FAE反馈当卷积层的group不为1,高精度量化存在bug,可以用DepthwiseConv做替换进行规避,据说DepthwiseConv的性能还更好一些。
layer { |
替换为
layer { |
实测在仅将前两个卷积层用FP16量化的情况下,上述人车狗模型混合量化的性能与INT8量化接近(<1ms),精度掉点在可接受的范围内(1-2个点)
 wechat
wechat alipay
alipay






![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)