AI算法基础 [10]:长短期记忆网络LSTM
前言
RNN的不足就在于随着时间序列的增加,前后信息关联度会逐渐减小,存在横向梯度消失现象。即短期记忆问题或长期依赖问题。为了解决这一问题,LSTM应运而生。
算法原理
RNN->LSTM
长短期记忆网络(Long Short-Term Memory network,LSTM)是一种特殊的RNN,和RNN一样,其隐藏层有着随时间序列重复的节点,只不过节点内部的结构要更为复杂。
RNN中隐藏层节点内部的结构非常简单,如果激活函数为tanh,则如下图所示:
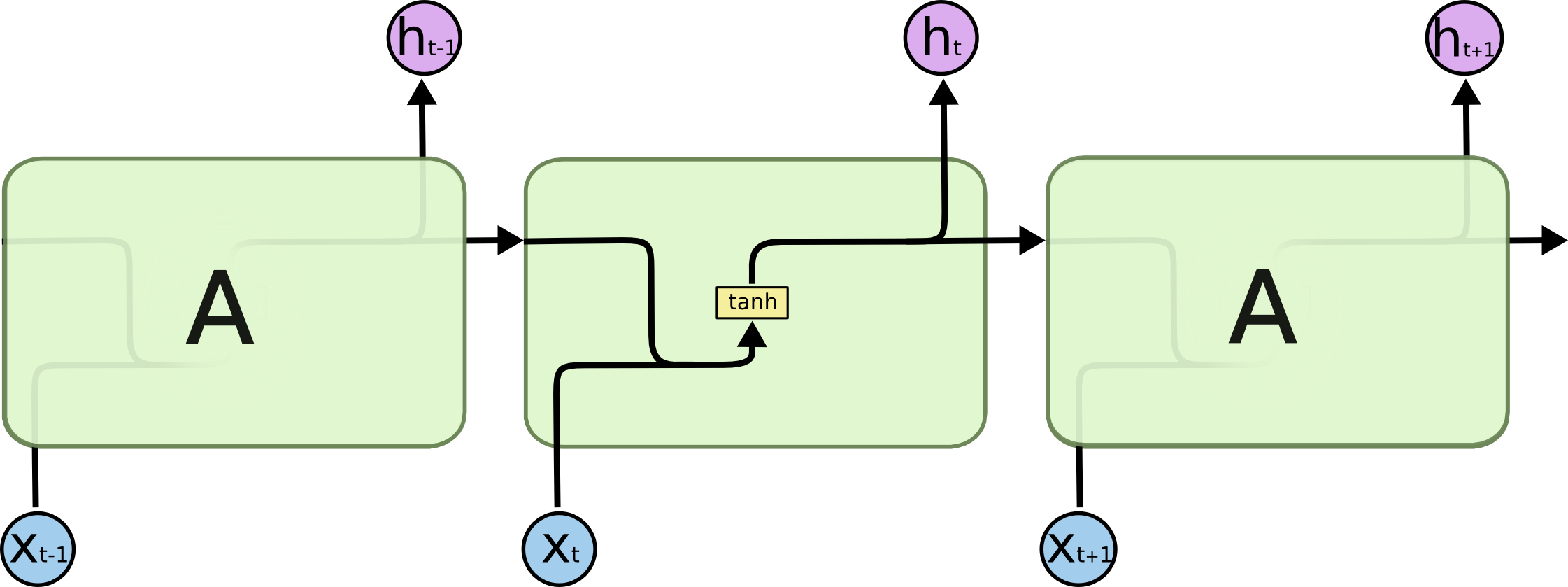
LSTM的结构要更为复杂,如下图:
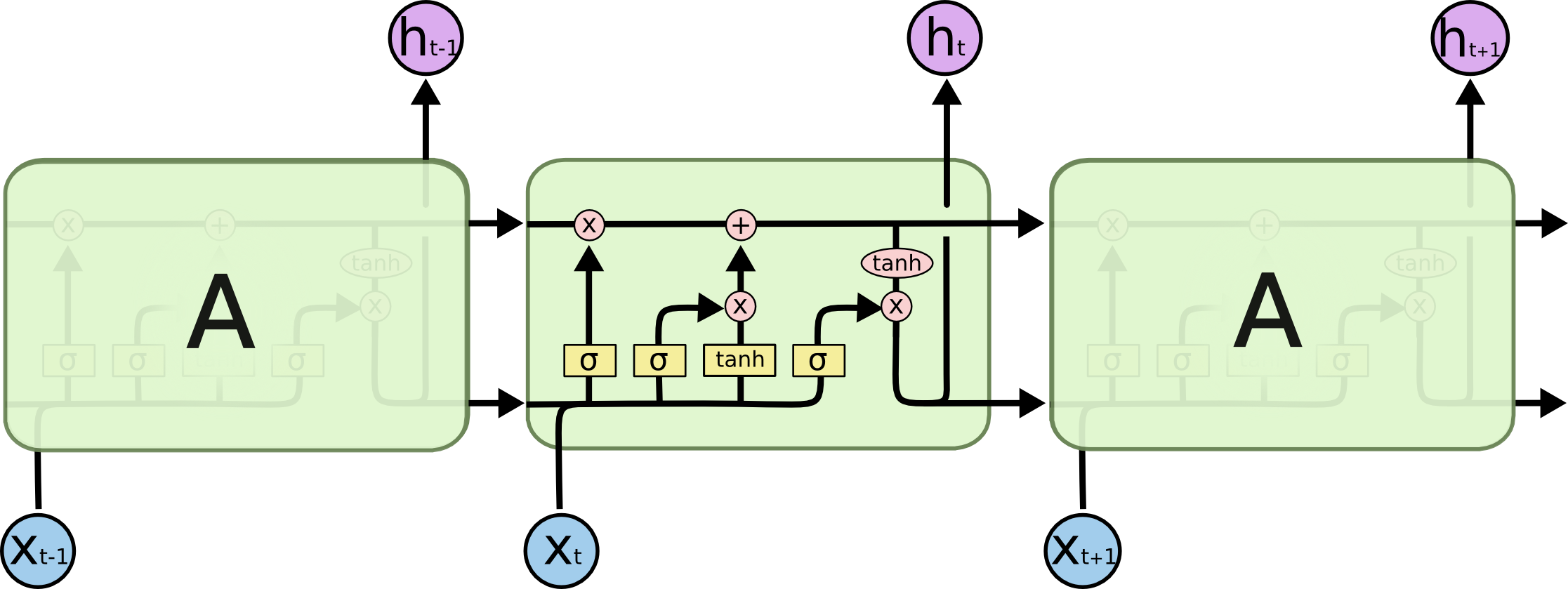
图中各图形符号的含义如下:

- 黄色方框:神经网络(激活)层(黄框tanh和粉圈tanh的区别就是黄框前是有的卷积操作的);
- 粉红色圆圈:逐点运算(即为hadamard product,后续图中公式也用表示;即为矩阵加法);
- 黑色箭头线:向量转移;
- 箭头汇合:向量合并
concat操作; - 箭头分离:向量拷贝供不同模块使用;
核心思想
LSTM的核心思想是胞元状态(Cell State)的流动,即图中上方的水平贯穿线。
胞元状态有点像一个传送带。它沿着时间轴一路往下,每个节点只会对其做一些小的线性变换。信息很容易以不变的方式流过。
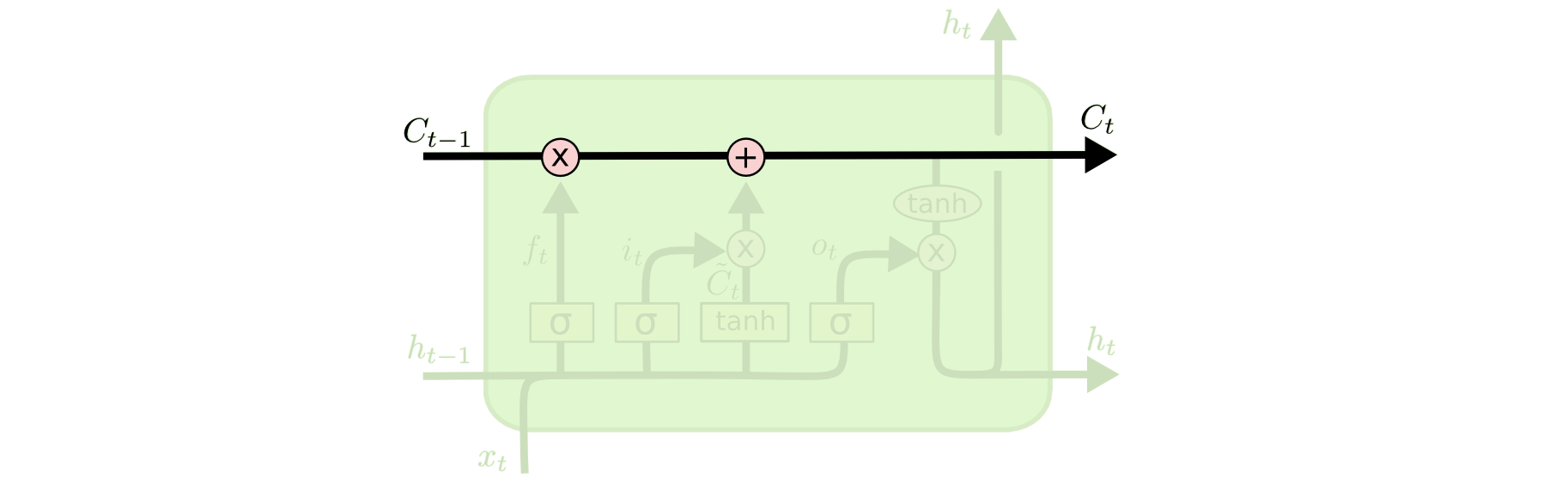
所谓的线性变换即为给胞元状态移除或添加信息,这是通过一种叫门的结构进行调节的。门可以选择性的让信息通过,由一个sigmoid激活层和一个逐点乘操作组成。sigmoid的输出约束在了0~1之间,即表示让信息通过的程度。一个LSTM节点有3个门结构,用于保持和控制胞元状态。
结构分解
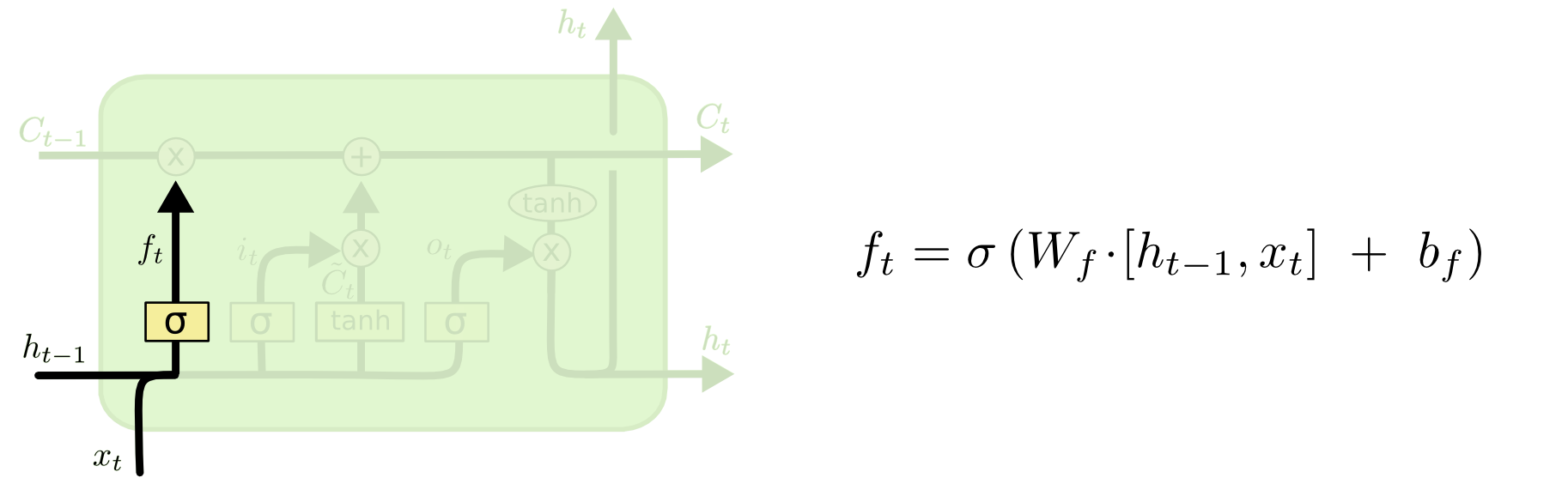
遗忘门(forget gate)
决定上一时刻胞元状态的通过/遗忘程度,它的输入是(隐藏层状态,hidden state)和,输出为,即为的每一个值生成一个0~1的scale系数。0代表完全遗忘,1代表完全通过。
举一个NLP的例子,胞元状态中可能包含当前主语的性别信息,以便能够使用正确的代词(他她它)。当看到新的主语出现时,则需要忘记旧的主语的性别。
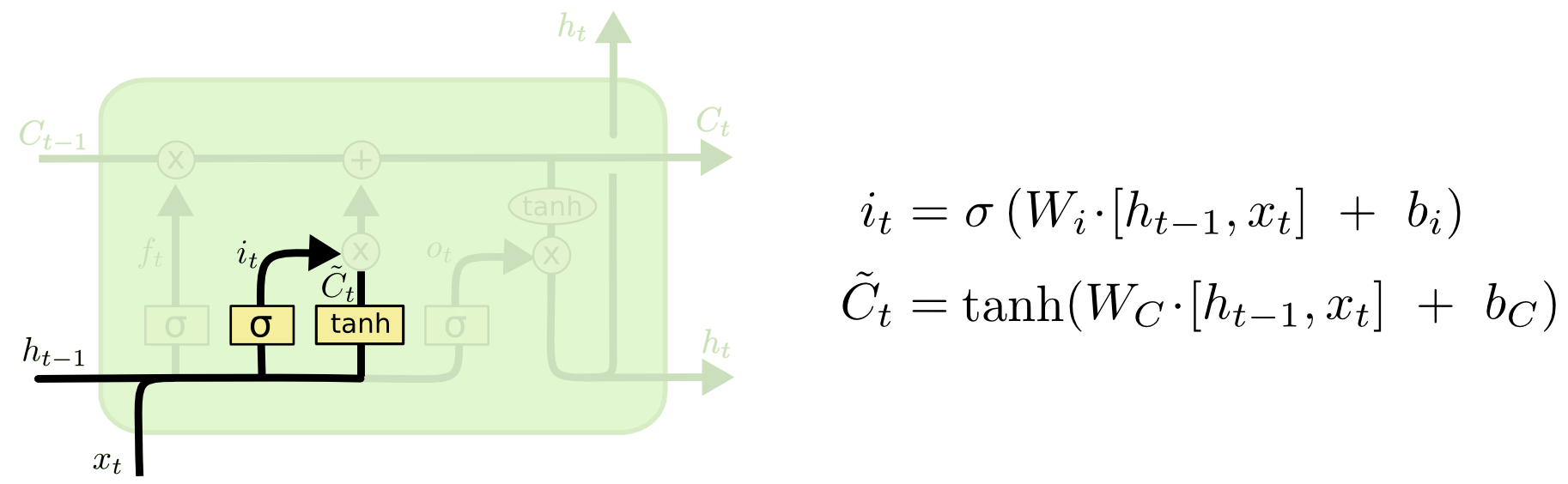
输入门(input gate)
决定哪些新的信息要被更新进胞元状态,及更新的程度,输入同样是和,输出为,它作用到一个新的候选值向量,这个是由tanh激活层对输入做非线性变换得到的。最终生成的信息会逐点加到胞元状态中。
还以NLP为例,我们需要增加一个新的性别到胞元状态中,以替换已经被忘记的旧性别。
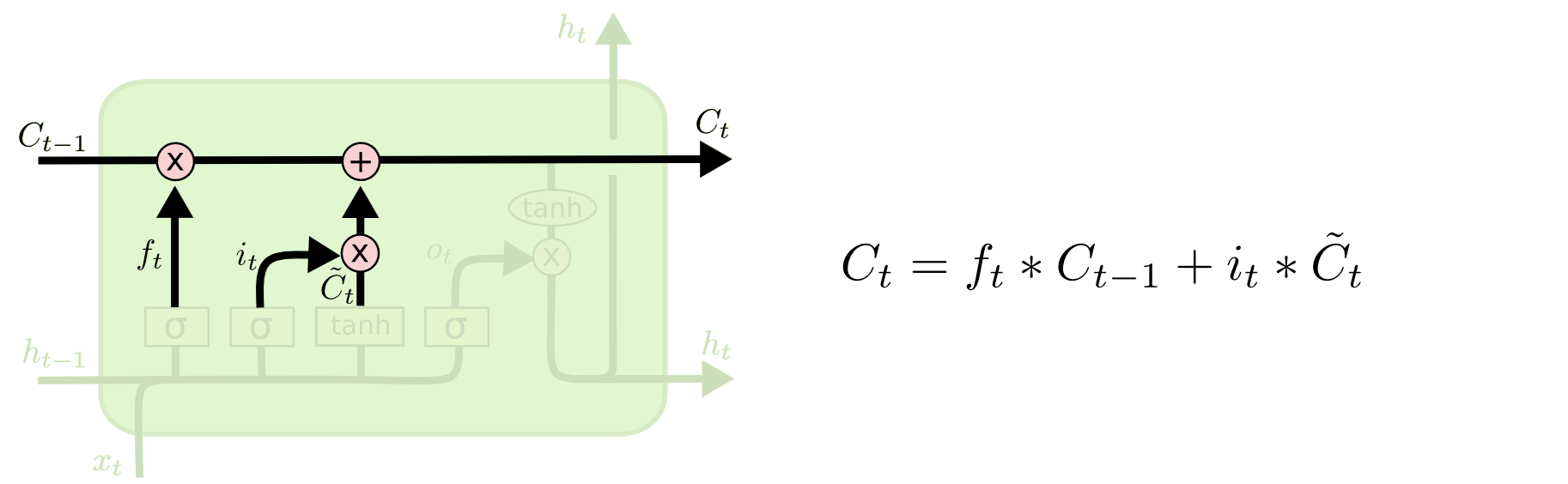
有了上述两步的输出,就可以将胞元状态由更新到了。其实就是做一次逐点的线性变换。乘上来遗忘我们决定遗忘的信息,加上来增加新的信息。
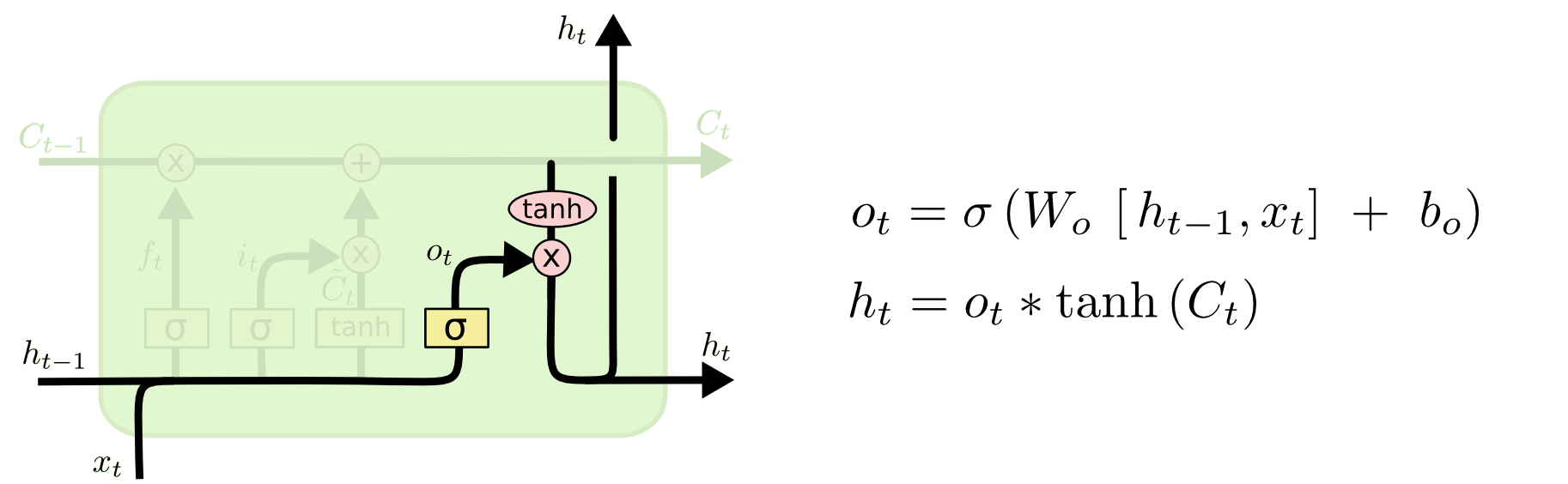
输出门(output gate)
决定哪些胞元状态要被输出,及输出的程度。输入同样是和,输出为,它作用到胞元状态经过tanh激活函数后的向量上。
还以NLP为例,我们现在看到了一个新的主语,则输出信息最好跟动词的选择相关,因为下一个词大概率是谓语。这时输出信息中就可以包含主语是单数还是复数,这决定了动词的形态。
总结
LSTM 节点通过门结构对胞元状态上的信息进行线性的修改,从而保证了在时间序列变长的情况下,依然能够保持时间相关性不会衰减。
参考
 wechat
wechat alipay
alipay






![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)