计算机体系结构 [2]:指令级并行(ILP)与数据级并行(DLP)
前言
指令级并行( ILP, Instruction Level Parallelism)是指利用流水级并行和多指令发射等方式提高程序执行的并行度;
数据级并行(DLP, Data Level Parallelism)是指处理器能够同时处理多条数据的并行方式,即SIMD。
本文将对上述几种程序优化方式实现简单的测试样例进行性能提升的验证。
理论基础
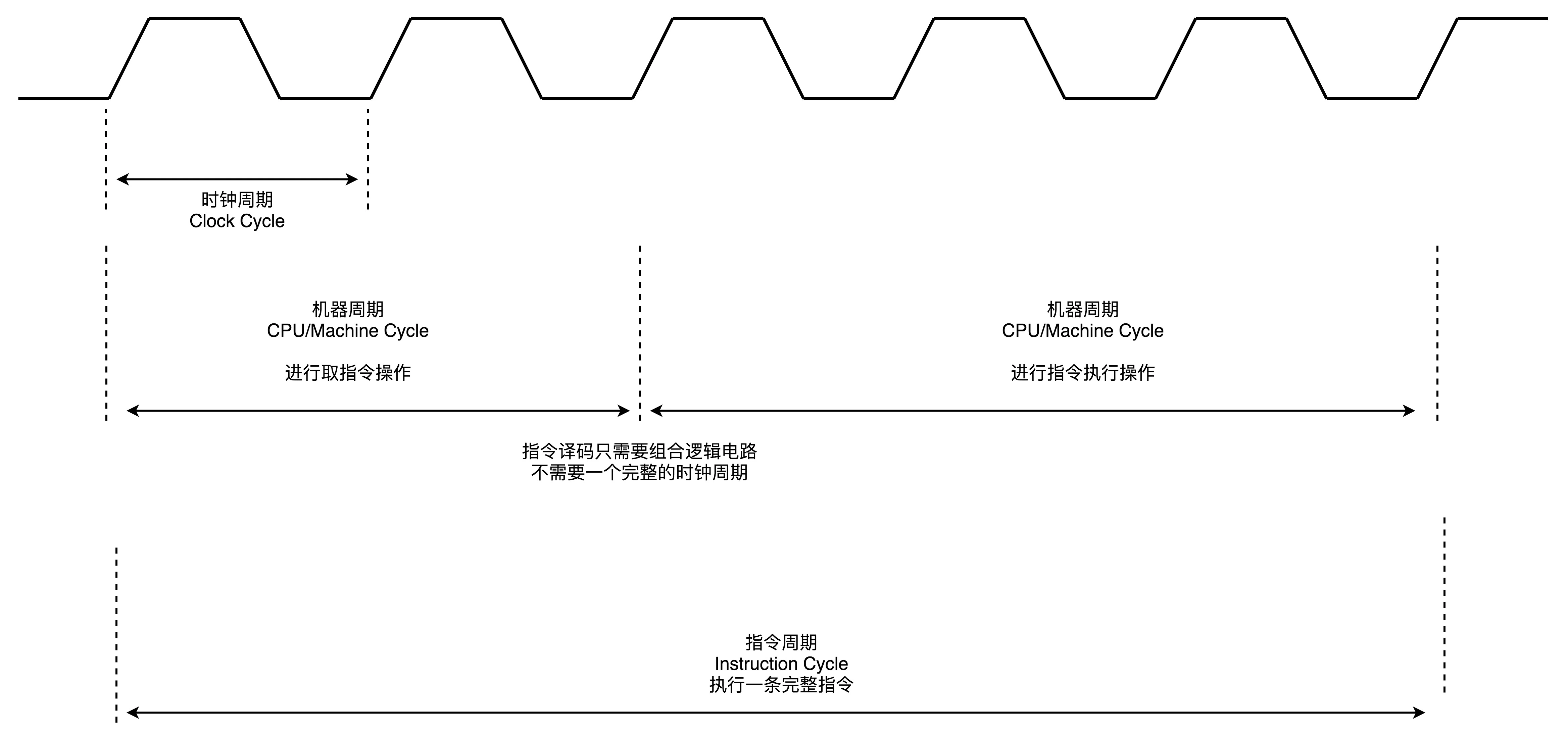
周期
指令周期(Instruction Cycle):完成一条指令的时间;
机器周期(Machine Cycle,又称CPU周期):完成一条指令中单个基本操作(取指,译码,执行等)的时间;
时钟周期(Clock Cycle):主频的倒数;
三者之间的关系大致如下:
经典5级流水线
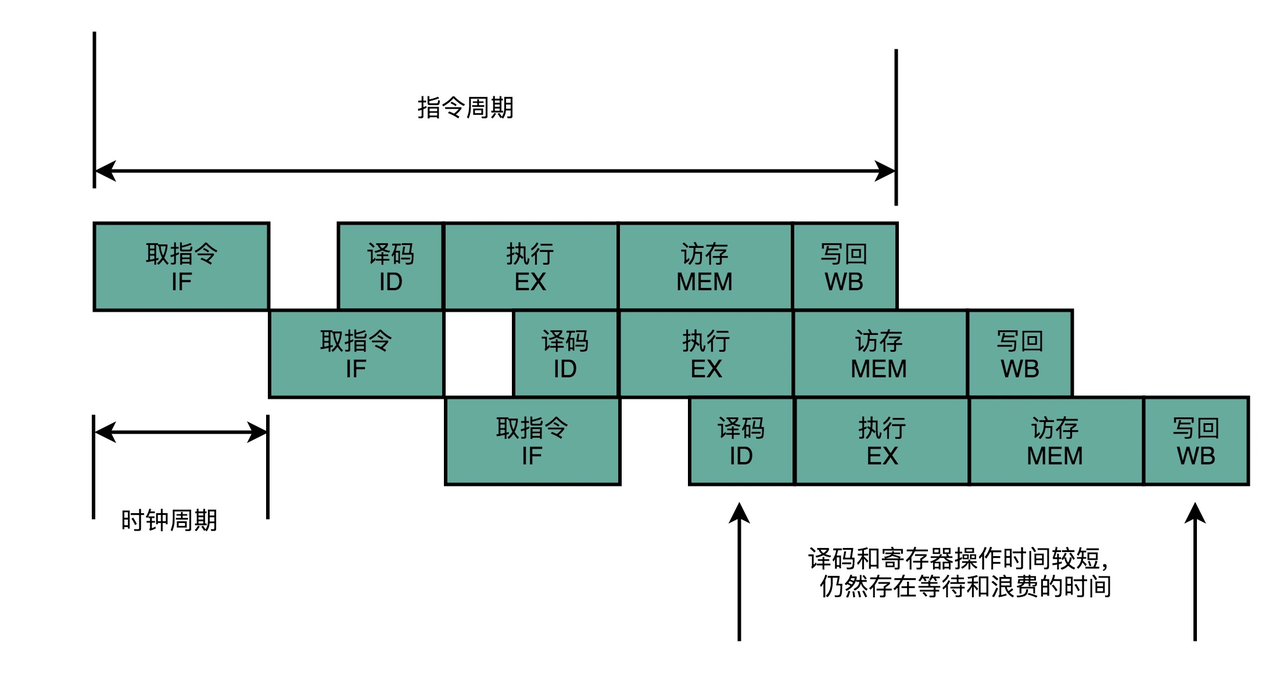
经典的5级流水线(现代CPU不止5级流水线,随着技术发展到今天,你日常用的手机 ARM 的 CPU 或者 Intel Core的CPU,流水线的深度是 14 级(存疑,暂无数据支撑找到了,看这里))如下图所示:
-
指令提取周期(IF):送出PC(程序计数器),并将指令从存储器提取到指令寄存器中(IR);将PC递增4,以完成下一顺序指令的寻址。
-
指令译码/寄存器提取周期(ID):对指令进行译码;并访问通用寄存器组(寄存器堆),读出所需操作数,放入临时寄存器;
-
执行/实际地址周期(EX):不同指令所进行的操作不同。
-
load和store指令:ALU把指令中所指定的寄存器的内容与偏移量相加,形成访存有效地址。
-
寄存器-寄存器ALU指令:ALU按照操作码指定的操作对从通用寄存器组中读出的数据进行运算。
-
寄存器-立即数ALU指令:ALU按照操作码指定的操作对从通用寄存器组中读出的操作数和指令中给出的立即数进行运算。
-
分支指令:ALU把指令中给出的偏移量与PC值相加,形成转移目标的地址。同时,对在前一个周期读出的操作数进行判断,确定分支是否成功。
-
-
寄存器访问/分支完成计算(MEM):不同指令所进行的操作不同。该周期处理的指令只有load、store和分支指令。其它类型的指令在此周期不做任何操作。
-
load指令:用上一个周期计算出的有效地址从存储器中读出相应的数据;
-
store指令:把指定的数据写入这个有效地址所指出的存储器单元。
-
分支指令:分支“成功”,就把转移目标地址送入PC,分支指令执行完成。
-
-
写回周期(WB):不同指令所进行的操作不同。ALU运算指令和load指令在这个周期把结果数据写入通用寄存器组。
- ALU运算指令:结果数据来自ALU。
- load指令:结果数据来自存储器。
流水线为什么不是越长越好?
因为增加流水线深度是有性能代价的。
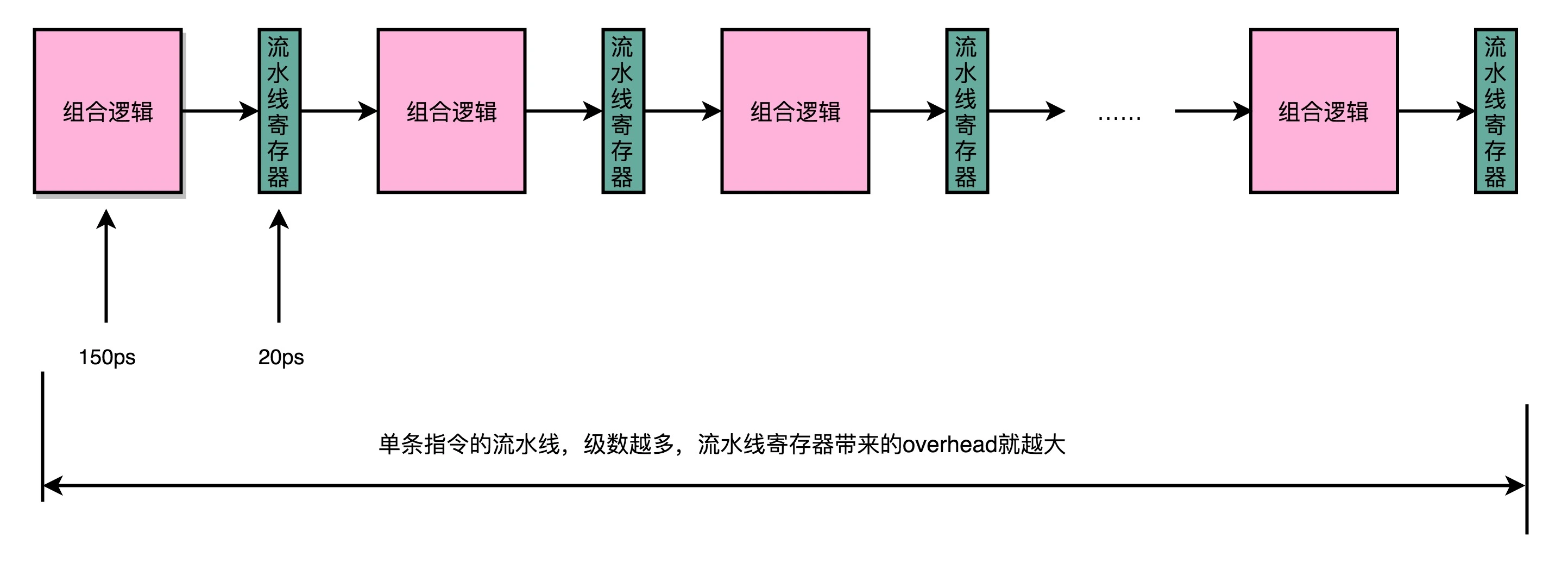
在流水线中,我们用来同步时钟周期的,是流水线级而不再是整条指令。所以每个流水线级的输出都要放到流水线寄存器(Pipeline Register)中,然后下个时钟周期,交于下一级流水线级进行处理。
所以每增加一级流水线级,就会多一次写入/读取流水线寄存器的操作,尽管这个过程相比流水线级本身的操作时间要快的多,但无脑的增加流水线的深度,会导致这一过程在整条指令时间消耗中所占的比例越来越大。其次,流水线深度的增加,还会导致冒险问题更难解决,从而导致吞吐量(IPC,Instruction Per Cycle,为CPI,Cycle Per Instruction的倒数)很难达到设计的最大值。因此,应当合理的设计流水线级数,在流水线深度和流水线寄存器overhead间做一定的trade-off。
测试用例
测试环境
平台:NVIDIA TX2,CPU Cortex A57,ArmV8架构,支持NEON Advanced SIMD,支持NEON Intrinsics,支持SuperScalar(超标量,又称指令多发射)
线程:单线程,不涉及线程级并行(TLP, Thread Level Parallelism)
编译器优化:O3
测试运算量
测试用例将会计算如下公式所示的操作:
在本例中,,,即对两个长度为的buffer执行乘累加运算,每个元素循环次,运算量为(1G)MACs。
基础实现
无任何优化的C++代码:
void OptLevel0(const float *input, |
通过objdump -d得到反汇编代码如下:
0000000000000d08 <_Z9OptLevel0PKfPfii>: |
其中d30到d44为最内层循环代码的汇编代码,可以看到编译器优化并没有将乘加运算进行向量化,而是只采用了标量的融合乘加计算指令fmadd,一条指令只进行一次浮点乘加运算,基本没有加速。
实测性能:4275ms
NEON向量化并行(SIMD)
使用NEON指令集对乘加运算向量化,这里没有写内联汇编,而是使用了NEON Intrinsics,ARMV8的向量寄存器为128位宽,一条指令可以处理4个浮点数据。
void OptLevel1(const float *input, |
同样查看反汇编有以下:
0000000000000d58 <_Z9OptLevel1PKfPfii>: |
其中,vfmaq_f32对应的汇编指令为fmla,使用了v0和v1两个向量寄存器,一条指令进行四次浮点乘加运算。
实测性能:1179ms,提升72.4%,接近理论值75%。
超标量(指令多发射)
将一条指令从指令译码级(ID)移入此流水线的执行级(EX)的过程称为指令发射(Issue)。
Cortex A57支持超标量(Superscalar)又称多发射(Multiple Issue),即存在多条执行pipeline,一个时钟周期内可以发射多条指令,即指令的吞吐量(throughput)> 1,或者称CPI(Cycle Per Instruction)< 1(这里吐槽一下intel的表示方法,其认为Throughput和CPI是同一个东西,对于双发射的指令,其标注为Throughput=CPI=0.5;我觉得应该是倒数的关系,即Throughput=ICP(Instruction Per Cycle)=2,CPI=0.5)。一个多发射的近似示意图如下所示:
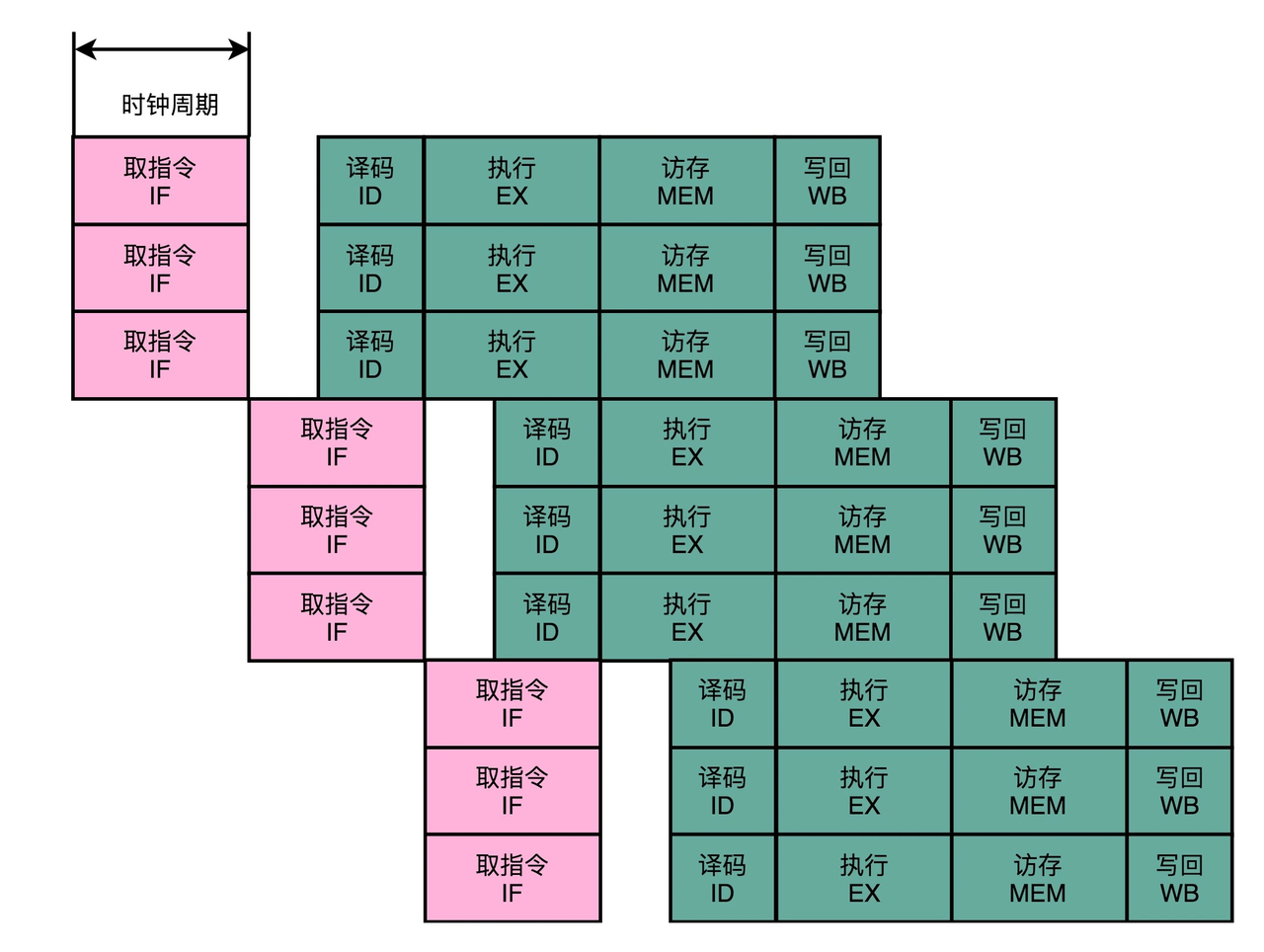
而超标量的硬件实现则是(像乱序执行时给EX阶段增加不同的FU一样)给IF和ID阶段也增加硬件并行支持,可以一次性从内存里面取出多条指令,然后分发给多个并行的指令译码器,进行译码,然后对应交给不同的功能单元(FU)去执行。如下图所示:
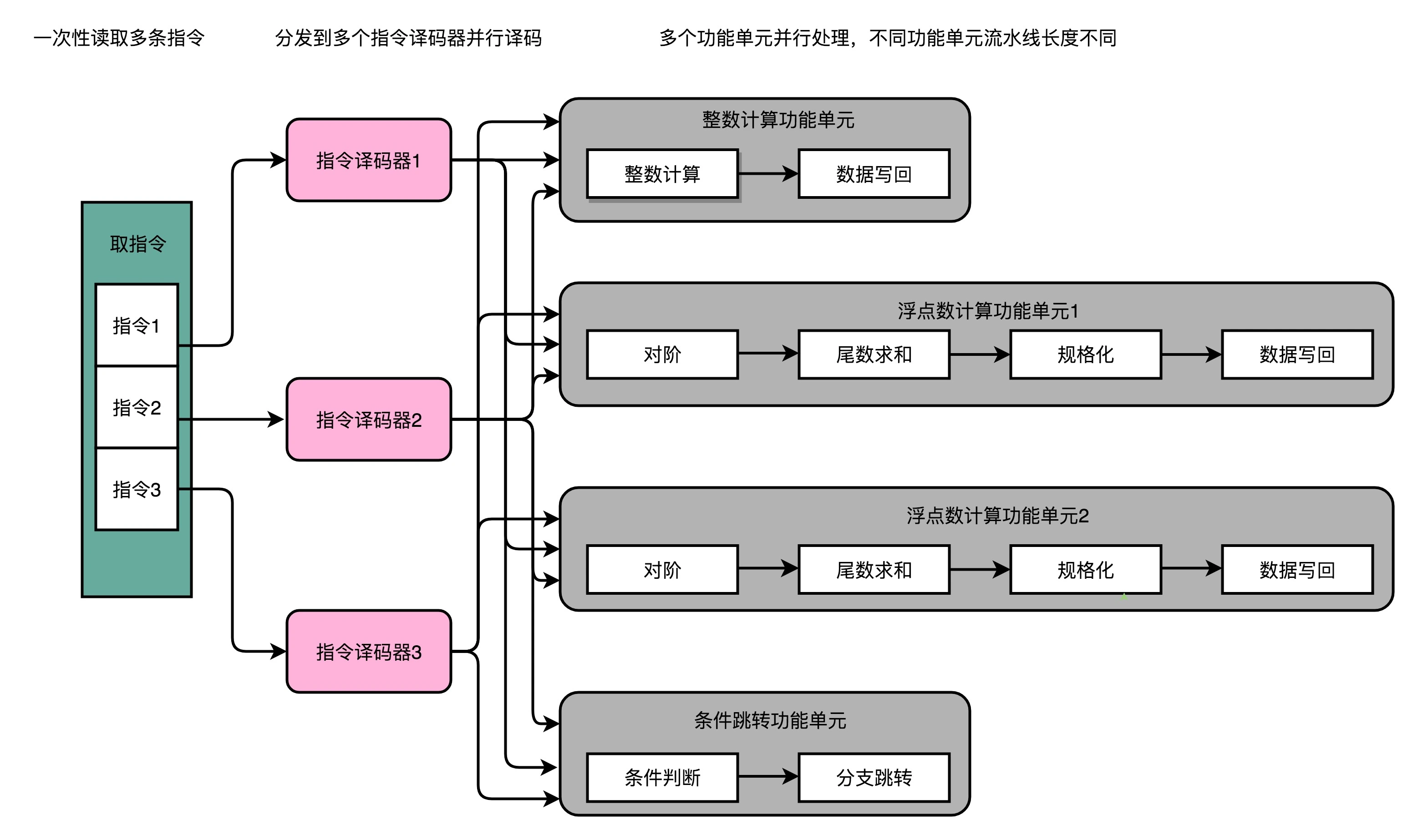
Cortex A57 Software Optimization Guide external中关于多发射的示意图如下:
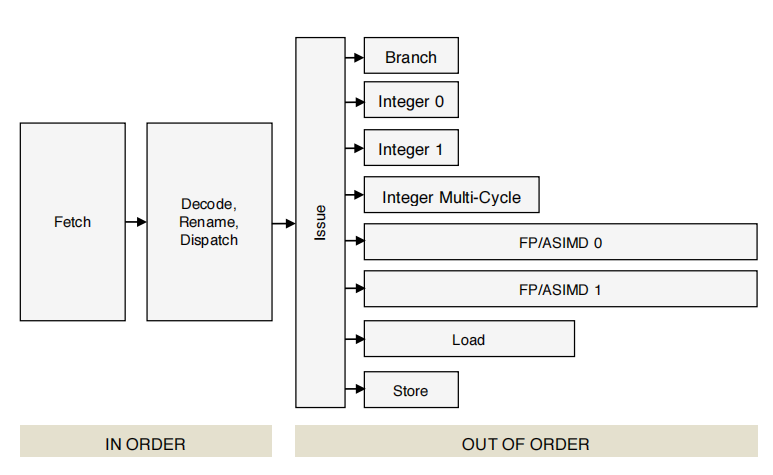
其中Fetch和Decode是同时对多条指令进行读取和译码,如果指令(们)满足多发射条件(不存在数据冒险),就会在一个时钟周期内发射多条指令到不同的执行pipeline。
查询手册可知fmla指令的吞吐量为2,即一个时钟周期内可以同时发射两条指令到两条pipeline,并行计算。
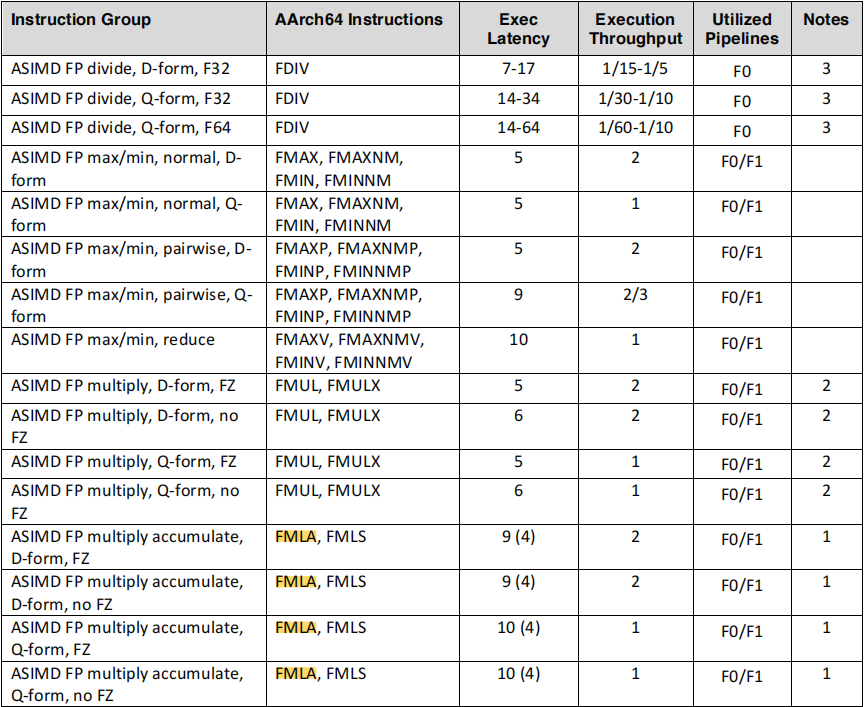
这里官方手册中有一点很奇怪,
FMLA的D-form(Double Word,双字)指令(对应Intrinsics为vfma_f32)确实是双发射,但Q-form(Quad word,四字)指令(对应Intrinsics为vfmaq_f32)是单发射。虽然看到有论文写到,在Cortex A57中,有两个64位宽的浮点pipeline,Q-form指令会拆成两个D-form指令发射到这两个pipeline中,但这也不是我们通常认为的那种双发射啊(按这样理解,并行度还是4而不是8)。且后面的实验也能看到,用10条vfmaq_f32指令填满2条流水线的5个流水级是性能最优的(耗时刚好是用5条指令的一半),这也侧面印证了。vfmaq_f32也是双发射的。搞不懂了,姑且就认为vfmaq_f32的吞吐量就是2了。这里留个坑,回头弄明白了再来填吧来填坑了,仔细看表格,发现
vfmaq_f32的延迟是10,即可以理解为单发射,10个流水级。所以也刚好是10条vfmaq_f32指令可以把流水级填满。
双发射要求两条指令之间没有数据依赖(不会因数据冒险而产生发射停顿),因此修改代码,外层循环一次加载8个float数据到两个向量寄存器,最内层循环每次发射两条FMLA进行计算。
void OptLevel2(const float *input, |
查看反汇编如下:
0000000000000dc0 <_Z9OptLevel2PKfPfii>: |
其中包含了两条fmla指令,分别使用了两个向量寄存器v1,v3和v0,v2。两条指令数据互不依赖,可以进行双发射。
实测性能:621ms,(相比上一优化)提升47.3%,接近理论值50%。
填坑之后,可以看到这里并不是真正意义的双发射,而是做了
2x的流水级并行,本节和下一节中关于双发射的描述并不符合实际情况,起码在A57上并不准确。
流水级并行
5级流水线的不同流水级(Pipeline Stage)在同一时钟周期内也可以并行(比如IF取完上一条指令后就空闲出来了,自然就可以取下一条指令,此时上一条指令在ID级),因此可以在一个指令周期内(不同的时钟周期)发射多条指令,保证一个时钟周期内流水线的各个阶段都有任务在执行。只要执行时间足够长(计算量足够大)的话,除了开始和结束流水线的部分,流水线可以近似5x并行。示意图如下:
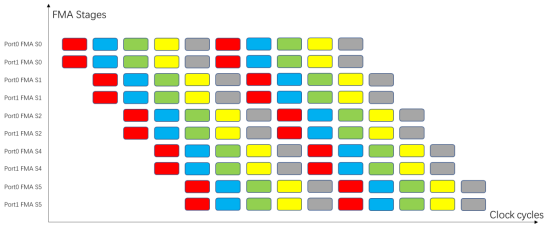
其中纵轴S0到S5表示流水线的5个流水级,Port0和Port1表示有两个发射端口,即双发射。第一个时钟周期,有两条FMA指令(红色)被发射到Port0和Port1,并执行流水线的第一流水级IF(其实按照更狭义的理解,这里不能称为发射,而是IF取两条指令,后续ID级检查冒险后,能流入EX后才叫发射。但是由于IF和ID可以处理多条指令,不存在数据冒险的前提下,与EX级一起看成一整条pipeline,也没毛病,且更容易理解);而后到了第二个时钟周期,这两条指令进入第二流水级ID,同时新的两条FMA指令(蓝色)进入第一流水级IF;依此类推,周而复始,完美衔接,不存在任何停顿。
如果是单发射的CPU,需要连续5条(不存在数据冒险的)指令才能填满流水线各个阶段。如果是双发射,则需要至少10条指令。
同样,流水级并行的关键还是在于指令间不存在数据依赖,不产生数据冒险而发生发射停顿。
因此修改代码,外层循环一次加载40个float数据到10个向量寄存器,最内层循环每次发射(广义)10条FMLA进行计算。
void OptLevel3(const float *input, |
对应汇编代码如下:
0000000000000e58 <_Z9OptLevel3PKfPfii>: |
可以看到最内层循环中使用了10条fmla指令,20个向量寄存器v0-v7,v16-v27。
实测性能:139ms,(相比上一优化)提升77.6%,接近理论值80%。
多平台验证
除TX2外,数据来源自东哥分享,未自测
| 平台 | 架构 | L0/ms | L1/ms | L2/ms | L3/ms | 备注 |
|---|---|---|---|---|---|---|
| TX2 | Cortex A57 AARCH64 2GHz主频 | 4275 | 1179 | 621 | 139 | |
| Apple M1 | AARCH64 3.14Ghz主频 | 1023 | 220 | 130 | 43 | |
| AX630A | Cortex A53 AARCH64 1.3Ghz主频 | 1256 | 317 | 161 | 44 | buffer size调整为 |
| Amba H22 | Cortex A53 AARCH32 1Ghz主频 | 2569 | 474 | 240 | 68 | buffer size调整为;L3优化中外层循环一次加载32个浮点数据 |
上面Amba H22的实验设计中,L3优化中外层循环改为一次加载32个浮点数据的原因是,AARCH32只有16个128bit的向量寄存器,8个用于加载input数据,8个用于累加output,只能(非要超量加载也不是不行,只不过需要用到超量部分的数据时,已加载的数据会被压入栈,腾出寄存器给新的数据,这样会增加访存量,且流水线也不能完美衔接,导致性能下降)一次加载32个浮点数据。
总结
- 这里是从运算量角度分析性能提升的原因,其实由于一条指令load/store多个数据,访存量也会减少。
- 本例中的计算过程比较简单,能够比较接近理论的性能峰值;当计算变复杂时,计算中的数据依赖关系增多,并行将会更难实现,也许更加巧妙的利用流水线可以优化性能,也许根本就无解。
参考
[1] 计算机体系结构:量化研究方法(第5版)
[2] https://zhuanlan.zhihu.com/p/426127316
致谢
依旧感谢东哥的分享~
 wechat
wechat alipay
alipay





![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)