AI算法基础 [14]:GEMM进一步优化
前言
在上篇文章中介绍了how to optimize gemm是如何优化GEMM算法的性能,但他最终的优化结果就是理论极限吗?显然不是,下面将在其基础上进一步探究GEMM性能优化的边界。
测试环境
CPU:Intel Core i7 8700,3.2GHz主频,支持AVX2,FMA3,Coffee Lake(Skylake)架构
操作系统:WSL-Ubuntu-18.04
L1 Cache Size:32KB
Cache Line Size:64B
编译优化等级:O2
优化尝试
使用AVX2指令集
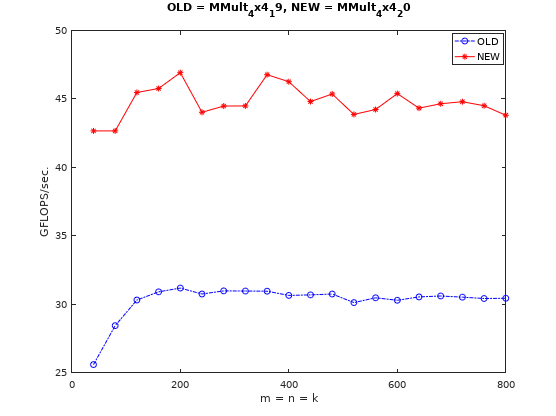
从上面可以看到,我的CPU最高支持AVX2指令集,AVX2指令集的向量寄存器为256bit,可以同时处理4个双精度浮点数据,因此用AVX2指令替换SSE指令后,性能理论上可以提升2倍。代码见这里。注意需要在makefile中添加-mavx编译选项,性能变化如下图所示:
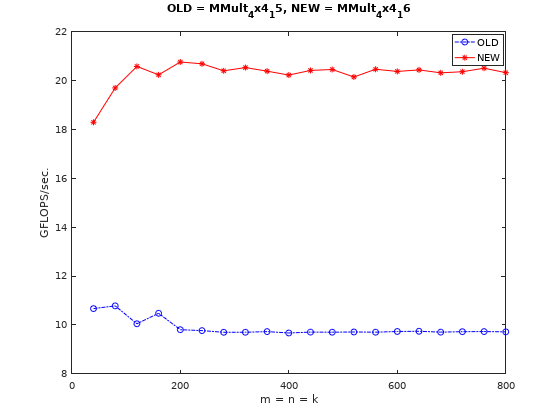
从上图可以看出,性能提升接近预期值。
指令全覆盖
已实现的微内核中的向量的乘加计算和store操作的代码并没有写成Intrinsics指令形式(编译器可能会优化),尝试将所有代码均替换成Intrinsics指令形式,观察是否有性能提升。
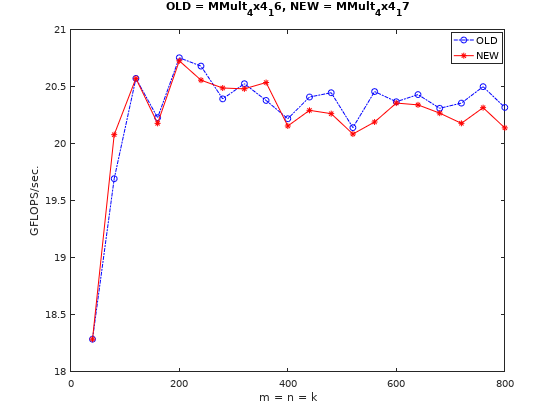
仅改动乘加运算部分,性能有波动但无明显提升,这也说明了乘加操作编译器会自动优化,如下图:
由于存在矩阵分块,所以原实现是将输出向量寄存器初始化为0,4x4的微内核(micro-kernel)计算结束后逐点累加到C矩阵的对应元素上,这显然不是很有效率。可以将C矩阵对应元素load到输出寄存器,微内核计算时直接累加,计算结束后通过_mm256_storeu_pd也可以一次store4个元素。代码看这里,提升效果见下图:
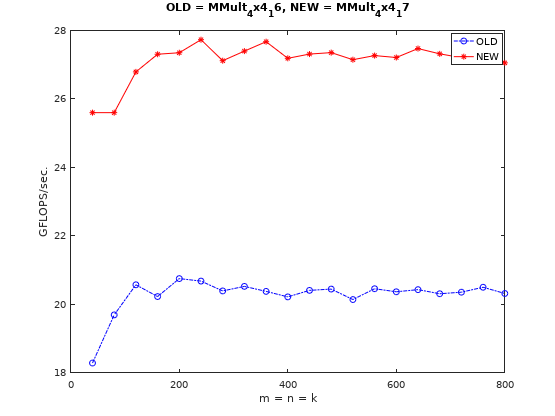
由于提升了访存效率,性能有提升是可以预见的。
使用FMA指令
AVX2加入了FMA指令,可以用一条指令_mm256_fmadd_pd完成乘加操作。注意需要在makefile中添加-mfma编译选项,代码见这里。性能变化如下图所示:
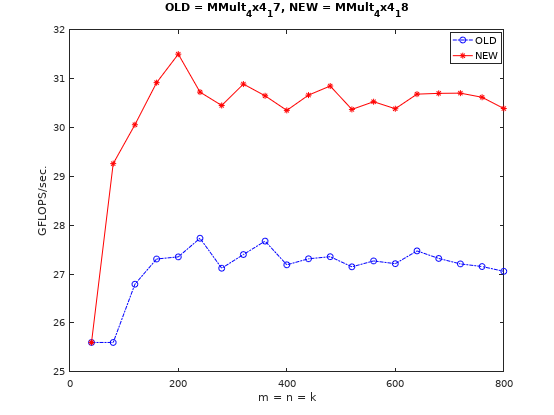
节约寄存器
这里用于加载B矩阵元素(并进行广播)的向量寄存器用了4个,其实是可以只用一个寄存器加载,计算用过之后再加载下一个元素。代码见这里性能实测结果如下图所示:
结果如预期,性能没有明显变化。这里如果就这样结束讨论,就是在第一层,其实还有第二层和第三层(乃至大气层)。结合大佬的这个文章,我们能略窥一二。
Skylake指令集流水线
这里先丢出一张我之前根本不会看也“不会”看的图:
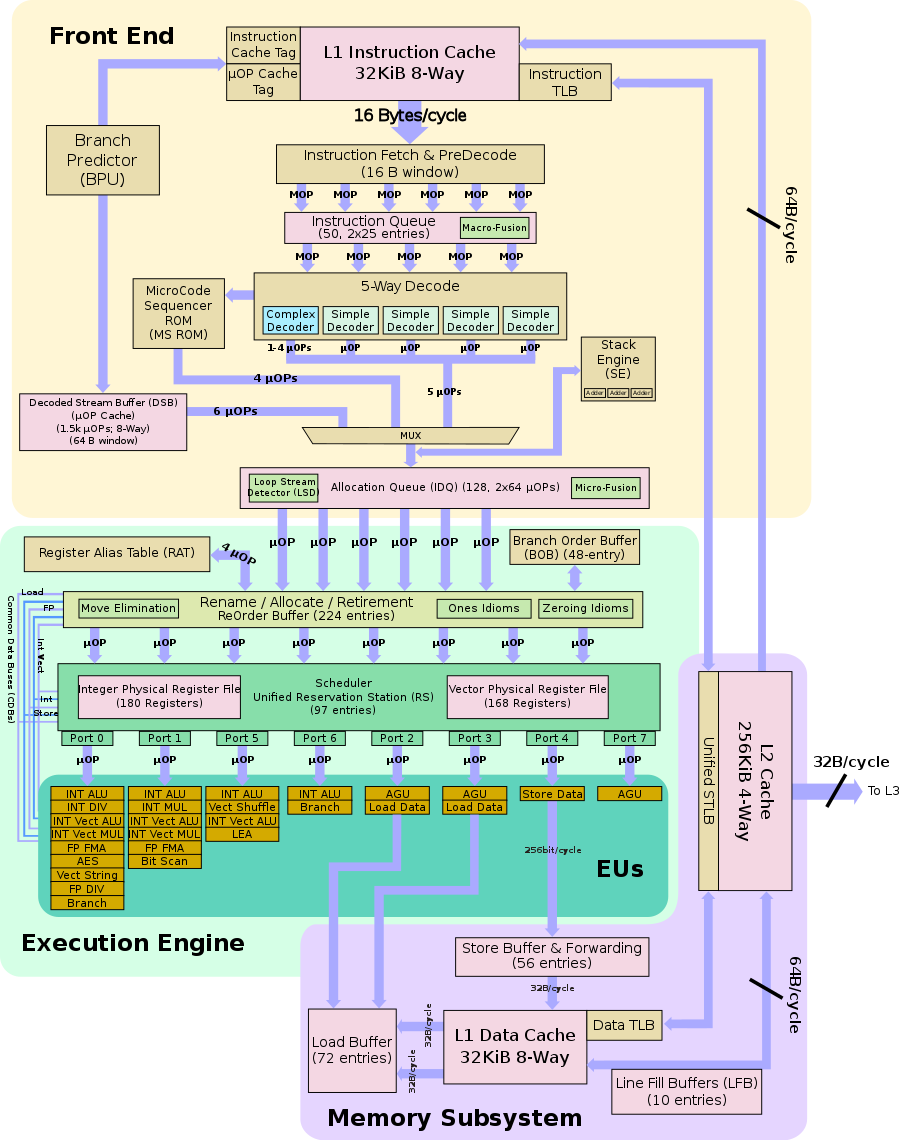
当然我现在仍然只能看懂一部分,如果看过我这篇文章或者了解常用的5级流水线的朋友,应该是能跟我一样有点意识的,这张图其实对应了Skylake架构指令集流水线的几个阶段的。其中Front End就对应了指令IF和ID阶段,Execution Engine就对应指令EX阶段,Memory Subsystem就对应指令MEM阶段。当然其中有更多比通用5级流水线更复杂的设计,这里不多做展开(其实是我不懂)。这里只说一些我知道的,或者说在我的CPU宇宙中能够逻辑自洽的东西。
多发射
这里先看一下EUs这部份,这里有Port1-Port7共8个端口,其中Port0和Port1各有一个FP FMA单元,这也从硬件上解释了为什么FMA指令的吞吐量为2,即可以做到双发射的原因。同样也可以看到Port2和Port3也各有一个Load Data单元,这说明加载数据的操作也是可以做到双发射的,且与FMA的双发射可以并行。
物理寄存器和重命名
我们知道AVX指令集有16个256bit位宽的浮点运算YMM逻辑寄存器(或者叫体系结构寄存器),这些寄存器是我们在编程时可以直接访问的逻辑上的寄存器。但是实际的物理寄存器是远远多于16个的,这在上图中也有体现(EUs上面的Scheduler中有个粉色框写着Vector Physical Register File(168 Register),但是不确定这168是否都可以给浮点运算用)。而逻辑寄存器到物理寄存器的映射就是寄存器重命名(上图中也有体现)。
那么为什么要这么做呢?Wiki给出了答案我觉得就讲的很好。首先上结论,重命名是为了解决指令乱序执行(或叫乱序发射)数据冲突(或者叫数据冒险)问题的。编译器会尽可能检查可能存在的数据冲突,把不同的寄存器分配给可能产生数据冲突的指令。但是编译器可以用的逻辑寄存器的数量是有限的(16个),总会出现不够分的情况,这时侯就需要通过硬件实现的寄存器重命名将不同指令中的同一个逻辑寄存器映射不同的物理寄存器,以解决可能出现的数据冲突,从而在硬件层面为指令集增加并行能力。那为啥不直接用跟物理寄存器一样多的逻辑寄存器呢?首先是历史继承问题,老的CPU的物理寄存器没有现在多,未来也许会更多,总不能加一些物理寄存器就修改一次指令集,这不合理;其次是增加逻辑寄存器会导致指令集变大,code size相应的也会变大,超过L1 Instruction Cache的话就会导致Cache miss增加, 这更致命。
回头看代码
有了上面这些理解,那么这时再回看上面节约寄存器的这段微内核代码,是不是有了更多的想法。那好,让我们来猜测一下编译器优化和CPU执行时的行为:
for ( p=0; p<k; p++ ){ |
对应的汇编代码如下:
130: c5 fd 28 06 vmovapd (%rsi),%ymm0 |
这里提到的发射如果没有特殊标注,均指狭义的发射,即为指令从ID到EX阶段。
首先,我们现在知道了Skylake CPU是具备在一个时钟周期内同时发射2条FMA指令和2条Load指令的。查阅手册可知Skylake架构下_mm256_load_pd和_mm256_broadcast_sd的延迟都是7,_mm256_fmadd_pd的延迟是4。关于Intel Intrinsics Guide中延迟概念的解读可能还存在一些歧义(不清楚这个latency是否包含IF和ID阶段),我这里就把它当作指令走完一整条流水线的时钟周期。假设IF和ID共占2个时钟周期,即Load指令发射后延迟为5,FMA指令发射后延迟为2。那么有以下两种推测:
- 如果按照顺序发射来理解,经过两个时钟周期的IF和ID,第3个时钟周期开始时发射了两条Load指令和两条FMA指令。在不考虑数据转发的情况下,5个时钟周期后,第1条FMA指令的数据才准备好,这期间FMA指令已经完成了IF和ID阶段,但由于数据冲突是处于发射停顿状态,一旦数据就位,再过2个时钟周期才能完成第1条FMA指令的计算。即9个周期后,
ymm5寄存器的值才会被拿走用掉,此时ymm5的WAR数据冲突才会解除,才可以开始发射第3条load指令,然后还要等5+2个周期才能完成第2条FMA指令的计算。后面依此类推,这样子的并行度就不是很高。 - 如果按照乱序发射+重命名来理解,则如下图:
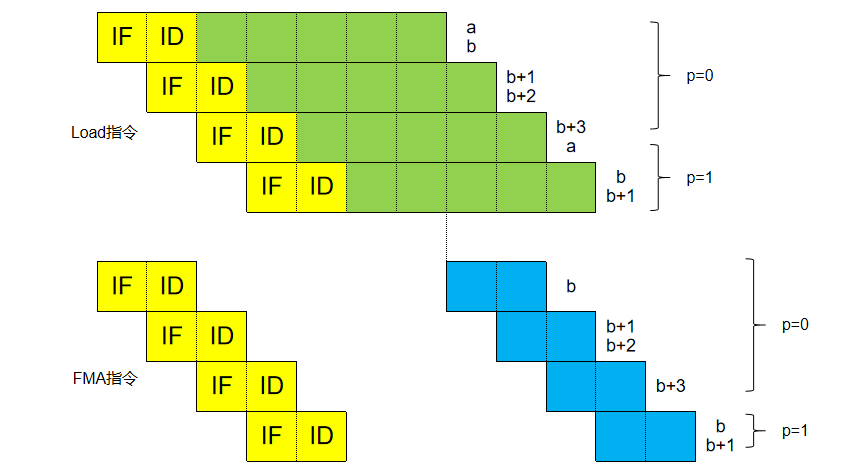
- 第3个时钟周期发射第1/2条Load指令,第4个时钟周期发射第3/4条Load指令,后面依此类推。第1条FMA指令要停顿到第7个周期后才完成发射,这样子第3/4条Load指令实际上是乱序到第1条FMA指令前发射的。这时如果没有重命名,对逻辑寄存器
ymm5的再次写入就会有WAW数据冲突,所以需要重命名将ymm5映射到不同的物理寄存器来完成发射。这样子FMA指令除了第一次5个周期的发射停顿外,后面的循环中便不会产生停顿,但会存在单发射(其实也是一种停顿,如图中FMA指令第三行,5个Load指令给4个FMA指令喂数据,必然会出现供应不上的时刻,即瓶颈为Load指令,而非FMA指令)。
所以这样只使用一个逻辑寄存器Load数据,穿插在FMA指令之间的代码,跟之前用5个逻辑寄存器一次Load完所有参与计算的数据,再执行FMA指令,在指令发射层面看是一样的。这才是为什么节约寄存器的修改并没有影响到性能的真正原因。
寄存器分块
从上面分析中可以看到,上述FMA计算过程还并没有把流水线的各流水级填满。可以查到Skylake架构下_mm256_fmadd_pd指令的延迟为4(可以理解为4级流水线),吞吐量为2(双发射)。也就是说至少要8条FMA指令才能将流水级填满。也就是说4x4的微内核(仅需要4条FMA指令)并不是最优解。
那么问题来了?将微内核改成4x8或者8x4就是最优解嘛?两者性能是相当的嘛?更大的微内核尺寸会更好还是更坏?接下来边做实验边分析。
8x4向量化
8x4向量化后微内核中的一轮运算对应的寄存器分块情况如下图所示:
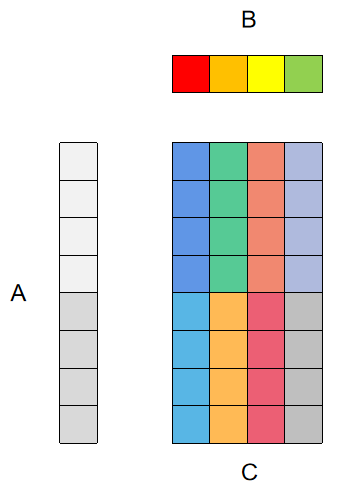
其中用于累加C矩阵输出结果的向量寄存器为2x4个,用于加载A矩阵数据的寄存器为2个,用于加载B矩阵数据并广播的为1个。代码见这里,注意一点就是除了微内核AddDot8x4外,A矩阵的Pack函数PackMatrixA也要做对应的修改。性能变化如下图所示:
如预期,性能是有提升的。这里简单再分析一下,在微内核中,共有6条Load指令给8条FMA指令喂数据,不会出现喂不饱的情况。8条FMA指令进行双发射可以填满4级流水线。理论上,这里的寄存器分块方式基本上就可以达到最优了。真的是这样嘛?
内存对齐
在看更多的例子之前,先解决一个小问题。
在上面的例子中,我们对A矩阵的Load操作是使用的_mm256_load_pd,这其实是有风险的。_mm256_load_pd要求内存是32字节对齐的,当没有对齐时,会报Segmentation fault错误。解决方法有两个:
- 分配/释放内存时使用
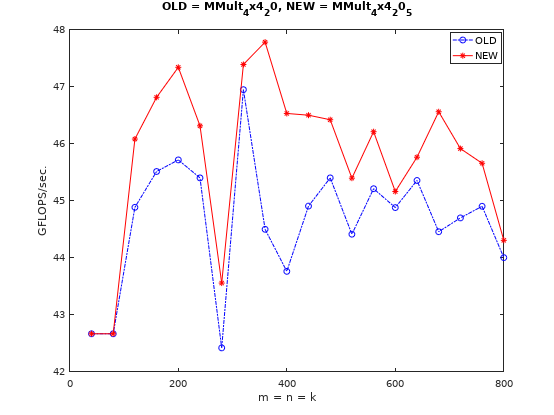
_mm_malloc和_mm_free,_mm_malloc的第二参数可以指定对齐的字节数。我们进一步也可以把对C矩阵的Load指令也改为_mm256_load_pd。代码看这里,注意外部分配内存也要修改,实测性能有略微提升,但不明显,见下图:
- 使用
_mm256_loadu_pd,该load操作不要求内存对齐,但相应的访存性能会下降。实测确实会影响最终性能,见下图:
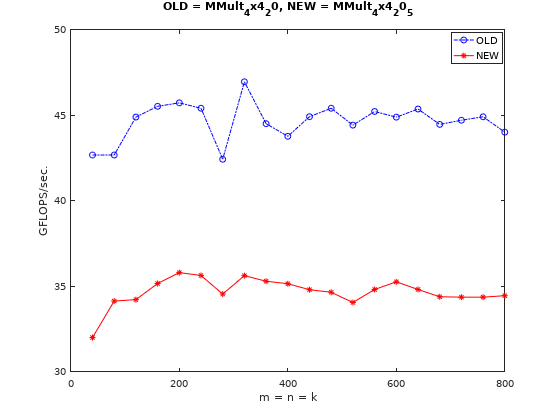
后面我们还是选择_mm256_loadu_pd这种方式进行接下来的实验,因为我们没有实现对不能整除部分(corner case)的特殊处理,严格对齐的方式对输入尺寸,分块尺寸和微内核尺寸就都有要求,否则就会出错。这里方便做对比,就采用非对齐方式。
12x4向量化
大佬的这个文章是选用的4x3寄存器分块方式(行优先排布),对应到我们这边就是12x4向量化(即3x4寄存器分块),示意图如下图所示:
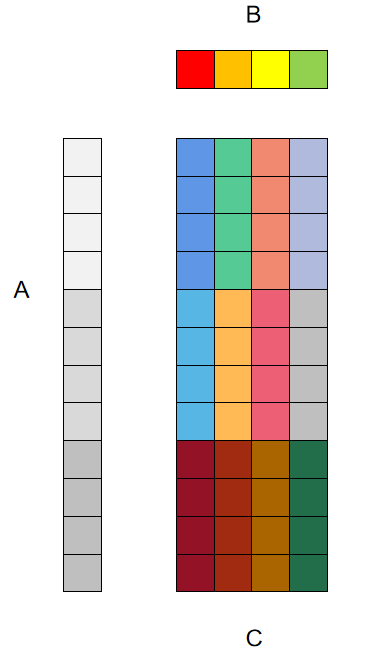
其中用于累加C矩阵输出结果的向量寄存器为3x4个,用于加载A矩阵数据的寄存器为3个,用于加载B矩阵数据并广播的为1个。刚好用完16个YMM逻辑寄存器(其实用超了应该也没关系,有重命名机制)。代码见这里,注意这里代码中将测试矩阵大小和矩阵分块大小都做了调整,以便能够匹配微内核的尺寸。性能变化情况如下:
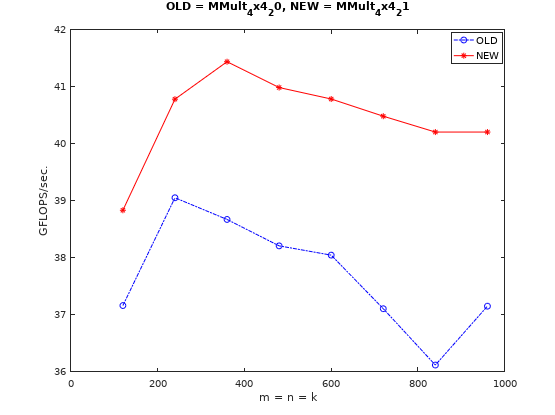
问题就出现了,这跟我们的预期不一样啊。我们之前认为8条FMA指令就可以就可以填满4级流水线的,但是增加到12条FMA指令,性能居然还有进一步提升。该怎么解释呢?
首先我们这里的测试环境比原文中的环境要更加复杂,涉及到矩阵分块和局部Pack,即便分块后的矩阵也肯定会超过L1 Cache Size的,访存性能这块肯定会有影响;其次我的用Intrincisc实现,原文中是汇编实现,这块可能也会有影响;第三,我甚至怀疑Skylake的FMA指令不是4级流水线,于是将原文代码修改成4x2寄存器分块方式再次测试,测试代码见这里,发现GFLOPS也基本上能拉满,所以并不是这一块的原因。
至于具体是哪方面原因导致的其实很难分析,也尝试过将micro-kernel单独拿出来,并且将矩阵大小控制在L1 Cache Size以内去测性能,发现也是两种寄存器分块方式的性能也是有差异的。以我现在的认知,不知道该怎么解释了,先留个坑,后面看能不能填上。
8x5向量化
8x5向量化,即2x5寄存器分块,其中用于累加C矩阵输出结果的向量寄存器为2x5个,用于加载A矩阵数据的寄存器为2个,用于加载B矩阵数据并广播的为1个。示意图如下图所示:
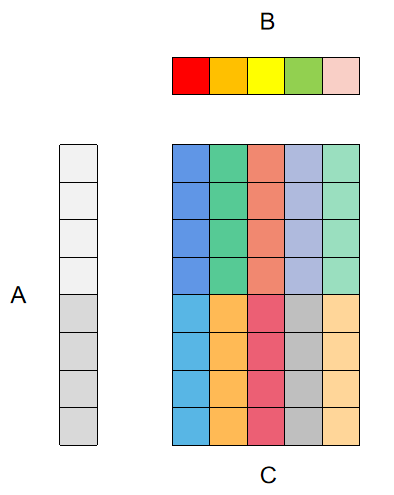
代码见这里,其他不多说,直接看性能变化:
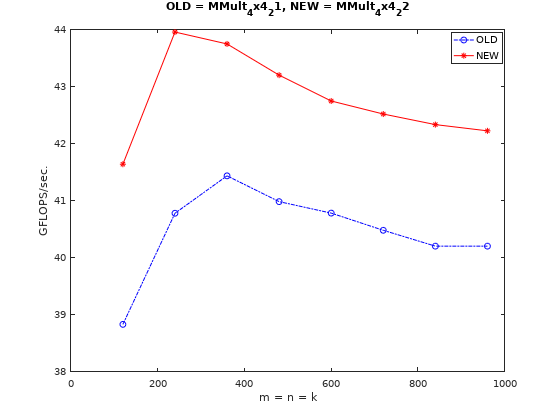
这!?继续挖坑吧。
循环展开
注意到sgemm_hsw是在一次循环中处理了4次k++的数据的,相当于循环展开。这会对性能有帮助嘛?我们也试试看。代码见这里,性能变化情况如下图:
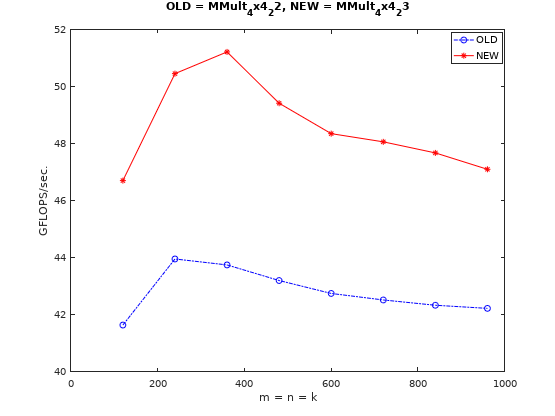
循环展开确实会有性能提升,循环展开可以减少分支预测错误,减少条件跳转指令(条件跳转指令的存在会影响乱序发射),从而提升性能。
前面不同的寄存器分块方式性能不同也可能有一部分这个原因。
总结
- 真正要优化好任意尺寸的GEMM运算的性能,要考虑的东西包括但不限于SIMD,访存,Cache,流水线并行,数据冒险,控制冒险等等;
- 寄存器分块那一部分还是有一些搞不清楚的问题,后续有了新的感悟再来补充吧。
参考
 wechat
wechat alipay
alipay






![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)