AI算法基础 [16]:分组网络GroupConv
前言
分组卷积(Group convolution),最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。Alex认为group conv的方式能够增加 filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
原理
普通卷积和分组卷积的示意图如下所示:
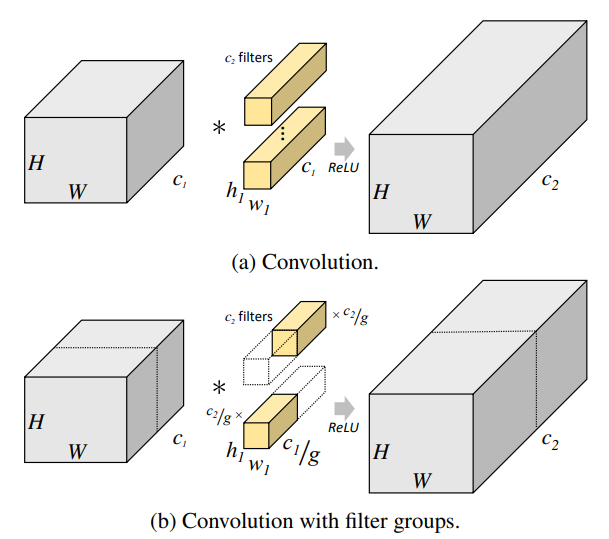
按照NCHW排布来看,对普通卷积而言:
- 单个输入feature map尺寸:$ 1 \times c_1 \times H_{in} \times W_{in}$
- 个卷积核的尺寸:
- 单个输出feature map尺寸:
- 参数量(假设无bias):
- 运算量(仅考虑浮点乘法):
对分为g组的分组卷积(上图中g=2)而言:
- 每组的输入feature map尺寸:$ 1 \times c_1/g \times H_{in} \times W_{in}$
- 每组的卷积核尺寸:
- 每组的输出feature map尺寸:,最终各组输出concat到一起
- g组总参数量(假设无bias):
- g组总运算量(仅考虑浮点乘法):
可以看到,得到相同尺寸的output feature map,分组卷积的参数量和运算量只有普通卷积的,是一种更高效的卷积方式。
从上面也能看出,分组个数g要同时能被输入通道数和输出通道数整除。
参考
[1] Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 旭穹の陋室!
 wechat
wechat alipay
alipay
相关推荐






评论
![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)