计算机体系结构 [4]:流水线冒险与预测
前言
想要通过流水线设计来提高CPU的吞吐率,其实是冒着一定的风险的。就类似于接力赛跑中,交接棒时会通过提前起跑来获取优势,但这时能否以全速完成交接取决于前后两个人的步调是否能达成一致。我们在流水线也会遇到一些被称为冒险(Hazard)的场景,冒险会阻止指令流中下一条指令在其指定的时钟周期内执行,从而降低流水化所能获得的理想的吞吐量。
冒险
主要有三大冒险,分别是结构冒险(Structural Hazard)、数据冒险(Data Hazard)以及控制冒险(Control Hazard)。
结构冒险
结构冒险本质上以硬件层面的资源竞争问题,即CPU在同一个时钟周期的两条不同指令的不同阶段,用到了同一个硬件电路。一个典型的例子如下图所示:
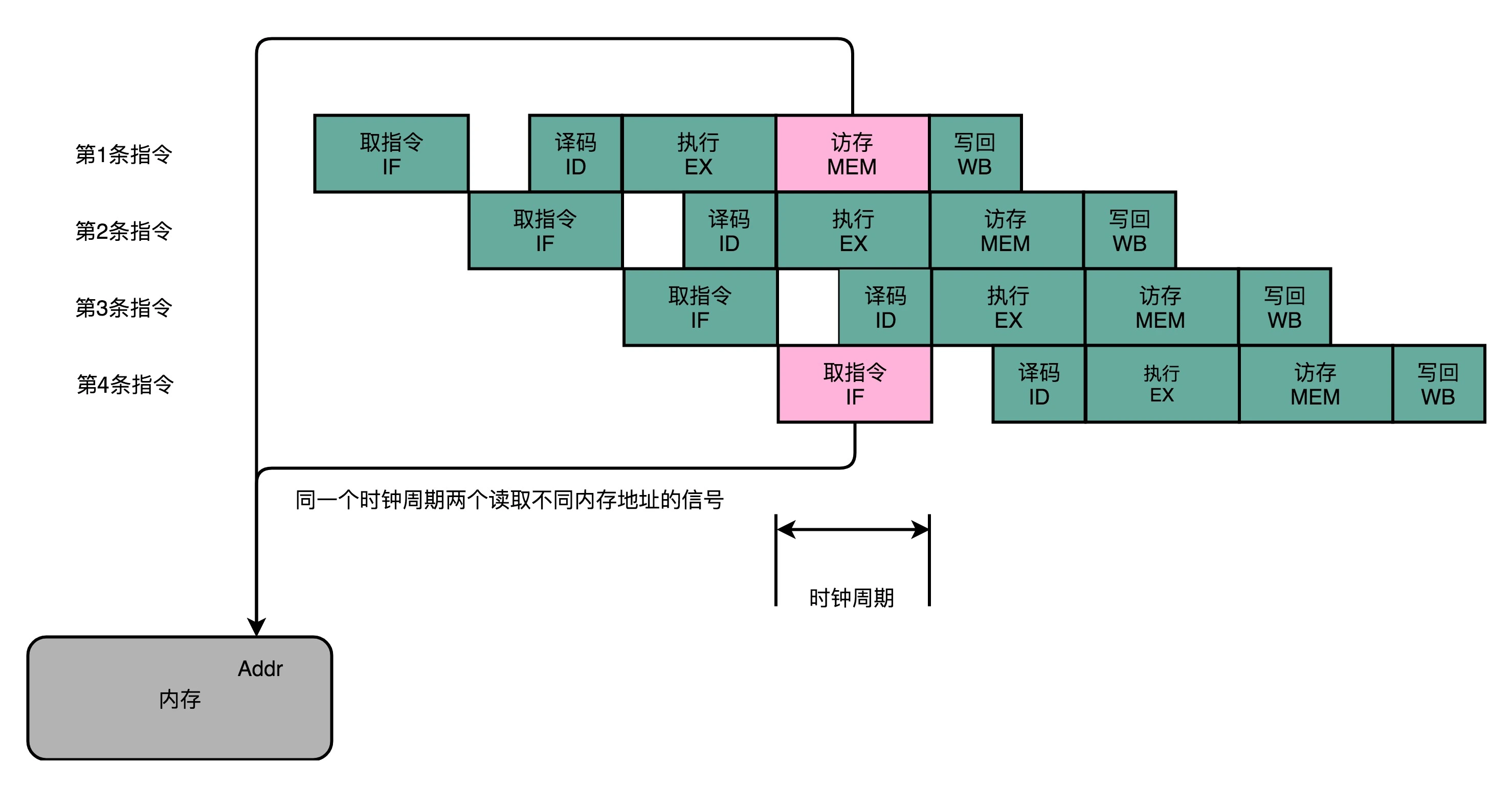
上图是一个典型的5级流水线,其中第一条指令的访存(MEM)阶段和第四条指令的取指令(IF)都涉及对内存数据的读取。若我们只有一个地址译码器去解析内存地址,则一个时钟周期内只能读取一条数据,故第一条指令和第四条指令并不能同时执行。
对于结构冒险,显而易见的解决方案就是增加资源。比如对于上面的问题,就可以将内存分为两部分,一部分为存放指令的程序内存,一部分是存放数据的数据内存,每部分有自己的地址译码器。这其实是哈佛架构(Harvard Architecture)中所采用的设计。
而冯·诺伊曼体系结构(又称普林斯顿架构(Princeton Architecture))中并未将内存进行拆分,因为这会限制内存使用的灵活性。不过也借鉴了哈佛结构的思想,现代CPU虽然没有在内存层面进行对应的拆分,却在 CPU 内部的高速缓存部分进行了区分,把高速缓存分成了指令缓存(Instruction Cache)和数据缓存(Data Cache)两部分。
内存的访问速度远比 CPU 的速度要慢,所以现代CPU并不会直接读取主内存。它会从主内存把一段连续的指令和数据加载到高速缓存中,这样后续的访问都是访问高速缓存。而指令缓存和数据缓存的拆分,使得我们的 CPU 在进行数据访问和取指令的时候,不会再发生资源冲突的问题。
指令对齐
MIPS指令集(5级流水线的典型代表)中几种指令的流水级分布如下表:
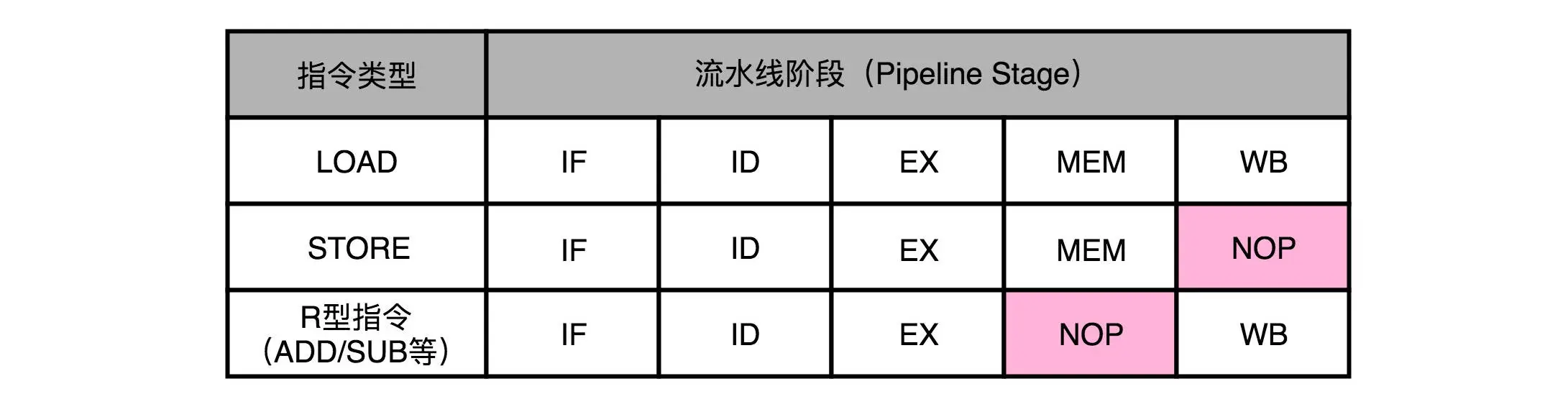
从上表中可见,STORE指令不需要写回到寄存器,故没有WB阶段,R型指令只针对寄存器进行操作,不需要访存,故没有MEM阶段。但是流水线设计时,并没有直接跳过该阶段,而是插入了一个NOP操作,这样做的目的是为了避免两条指令在同一个时钟周期内执行相同的stage(用到相同的硬件资源),也就避免的结构冒险。这叫做指令对齐。
数据冒险
数据冒险其实就是同时执行的多个指令之间,有数据依赖的场景。这些数据依赖关系可以分为三大类:分别是先写后读(Read After Write,RAW)、先读后写(Write After Read,WAR)和写后再写(Write After Write,WAW)。
先写后读的依赖关系,一般称为数据依赖(Data Dependency)。
先读后写的依赖关系,一般称为反依赖(Anti-Dependency)。
写后再写的依赖关系,一般称为输出依赖(Output Dependency)。
流水线停顿
解决数据冒险最简单(最笨)的办法就是流水线停顿(Pipeline Stall),又称流水线冒泡(Pipeline Bubbling)。在进行指令译码的时候,会拿到对应指令所需要访问的寄存器和内存地址,这时CPU中的冒险检测电路就能够对是否会触发数据冒险做出判断,因此就能够决定是按计划发射该指令,还是停顿一个或多个周期。但所谓的停顿不是真的停下来,而是插入一个NOP操作,即什么都不干的空操作。
操作数转发
先来看一个简单的例子:
add $t0, $s2,$s1 |
对于上面两条指令,存在先写后读($t0)的数据冒险。若采用流水线停顿的方式解决冒险,则时序图如下所示:
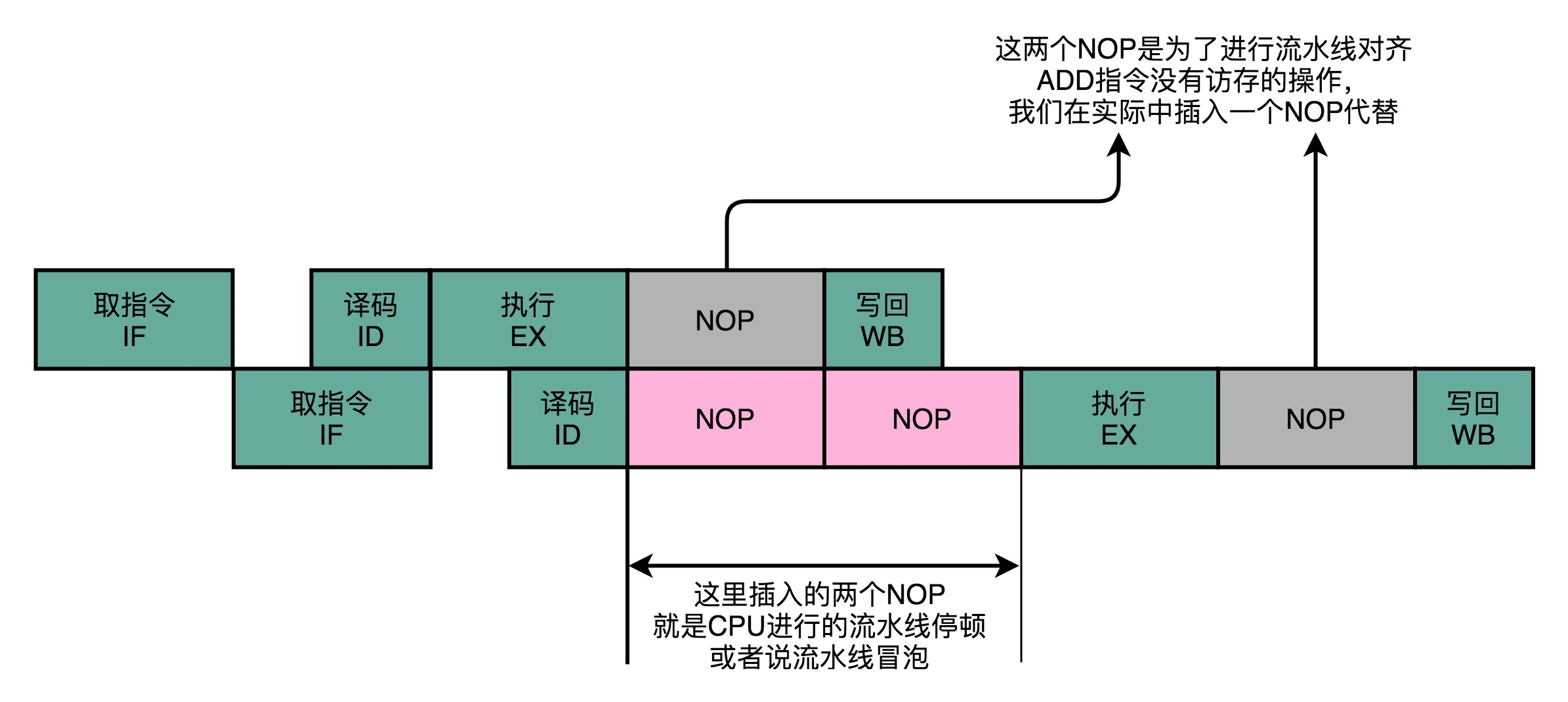
这里第二条指令多花了2个时钟周期用于等待第一条指令完成数据写回。但是我们其实并不需要等到写回完成,才开始执行第二条指令。我们可以将第一指令的输出直接传输到下一条指令的ALU,则时序图就如下所示:
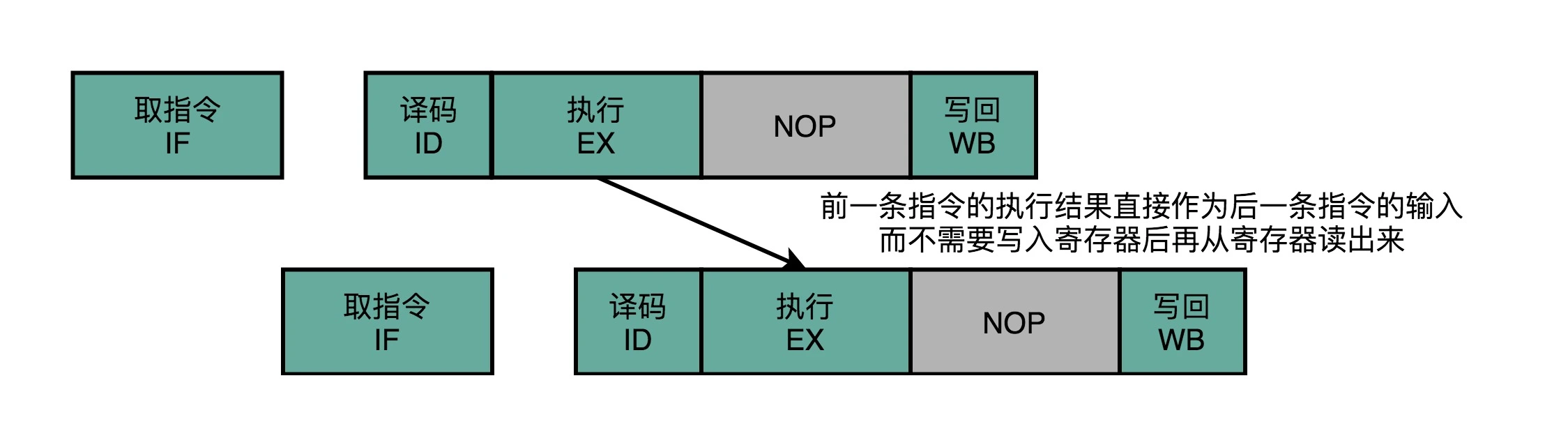
这种解决方法叫做操作数转发/前推(Operand Forwarding)或操作数旁路(Operand Bypassing)。转发解释了该方法的逻辑含义,而旁路则解释了该方法的硬件含义,即ALU的输出通过“旁路”线连接到ALU的输入,从而跳过(Bypass)了写入寄存器,再读取寄存器的过程。
当然转发并不能解决所有的冒险情景,有时还是要跟流水线冒泡一起使用。如下图:
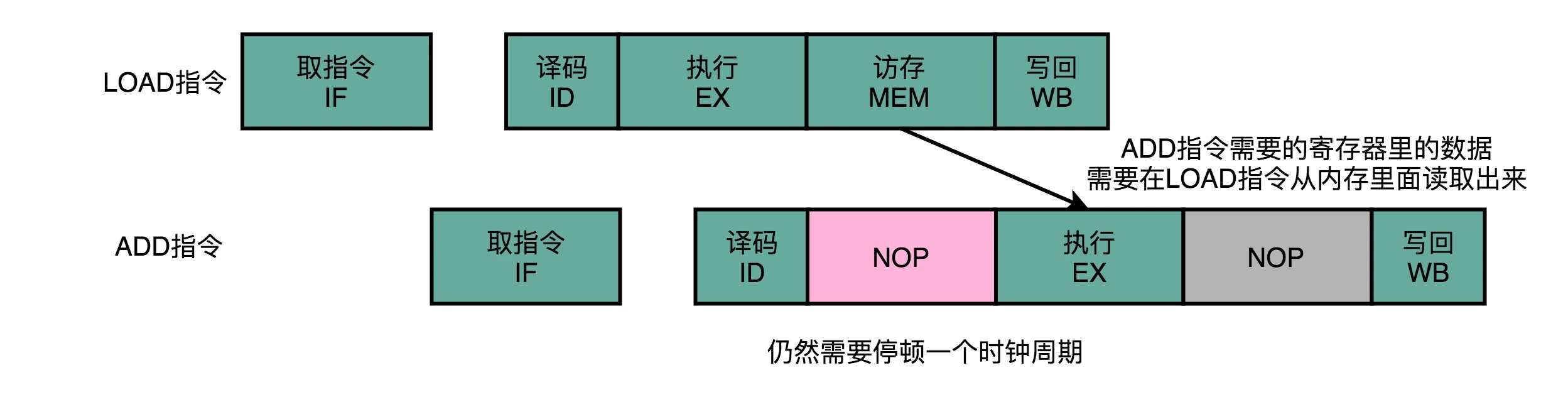
乱序执行/发射
在流水线里,如果后面的指令不依赖前面的指令,那就不用等待前面的指令执行,它完全可以先执行。这被称为乱序执行(Out-of-Order Execution,OoOE)。一个例子如下图所示:
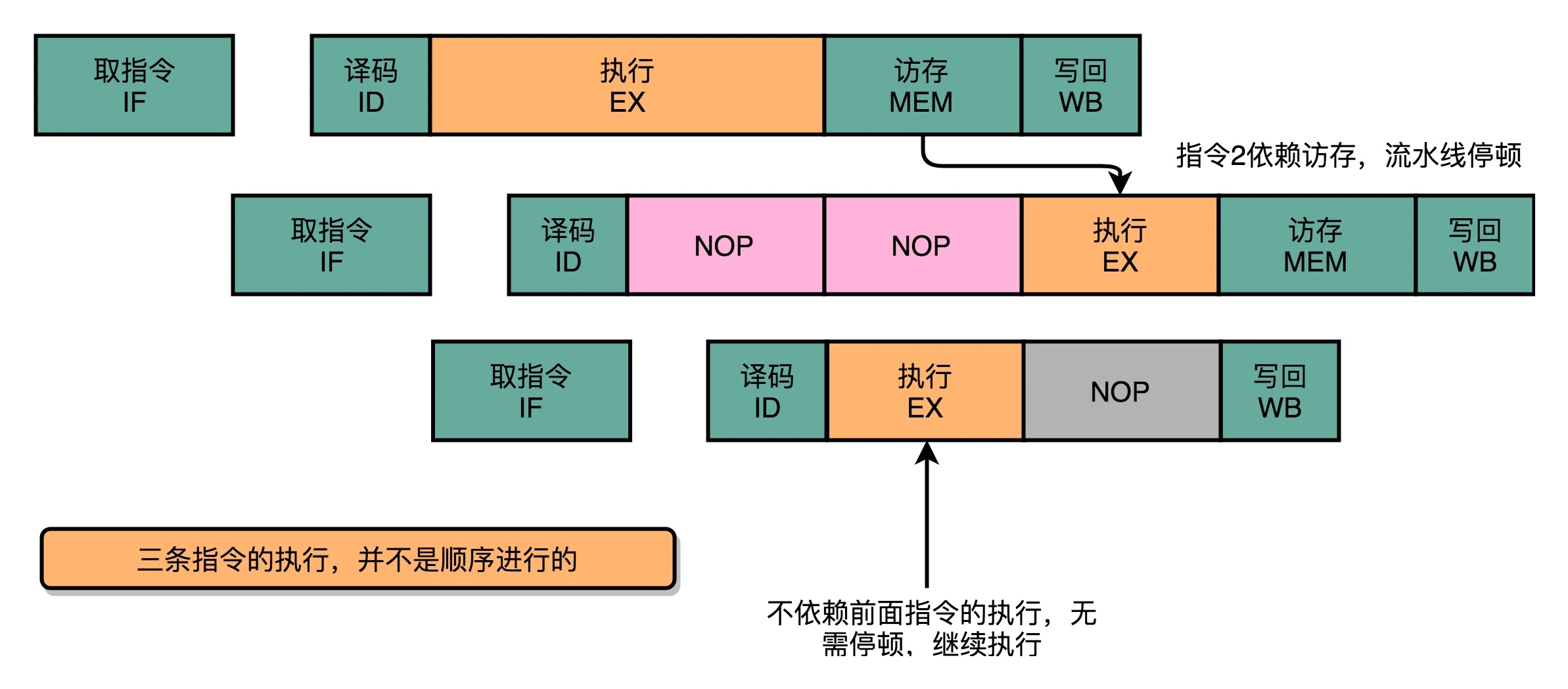
第三条指令并不依赖于前两条指令的计算结果,所以在第二条指令等待第一条指令的访存和写回阶段的时候,第三条指令就已经执行完成了。
使用乱序执行的CPU的流水线与经典5级流水线就不太一样了:
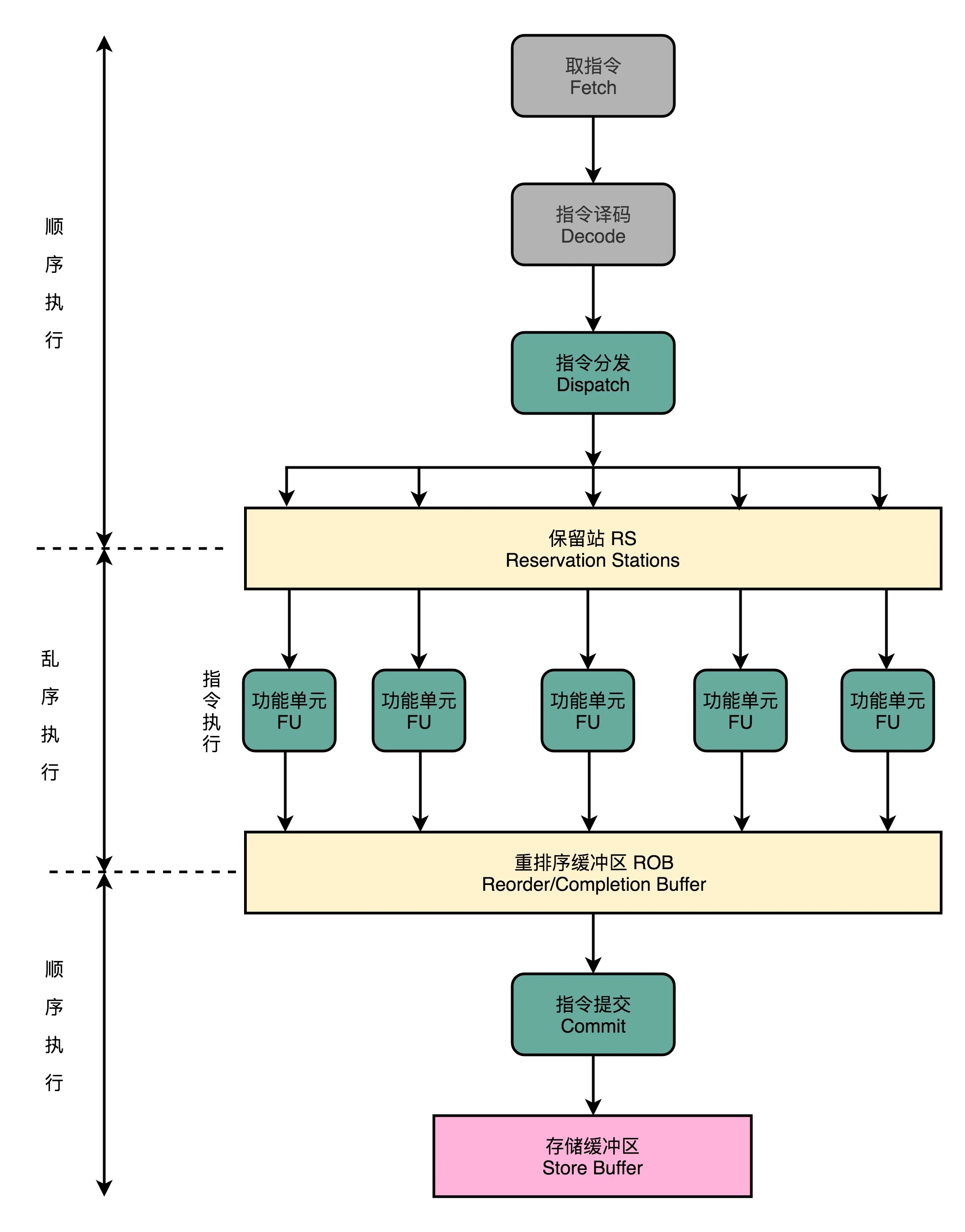
-
- IF和ID阶段与原来一样,顺序执行(看Skylake的结构框图,其实IF和ID也是多通道并行的);
-
- 指令译码结束后,会进行一次指令分发,把指令发到保留站(Reservation Stations,RS)中;
-
- 保留站中的指令并不会立即执行,而是等待它们依赖的数据准备完毕后才会执行;
-
- 指令执行是交由功能单元(Function Unit,FU)完成。FU其实就是ALU,不同的FU可以并行执行,但不同的FU支持的指令并不相同(如整形计算单元和浮点计算单元是分开的,加减运算和乘法运算单元也是分开的)。
-
- 指令执行阶段完成后,并不直接把结果写回寄存器,而是存放在重排序缓冲区(Re-Order Buffer,ROB);
-
- 在ROB中,CPU按照指令提取的顺序,对计算结果重新排序。只有排在前面的指令都完成了,才会提交当前指令,完成计算;
-
- 计算结果不会直接写回内存或告诉缓存,而是先放到存储缓冲区(Store Buffer)中(方便转发?),最终才会写入高速缓存和内存里。
从上面的过程描述可以看出,乱序执行是CPU层面的事情,发生在指令译码阶段分析到指令间的不存在数据依赖关系的前提下。但乱序执行后,会对计算结果进行重排,所以在CPU外部看来,指令仍然是有序执行的。
乱序执行,极大地提高了 CPU 的运行效率。核心原因是,现代 CPU 的运行速度比访问主内存的速度要快很多。如果完全采用顺序执行的方式,很多时间都会浪费在前面指令等待获取内存数据的时间里。CPU 不得不加入 NOP 操作进行空转。而现代 CPU 的流水线级数也已经相对比较深了,到达了 14 级,乱序执行可以充分利用较深流水线带来的并发性,尽可能的逼近吞吐量的理论上限。
控制冒险
为了确保能取到正确的指令,而不得不进行等待延迟的情景,就是控制冒险(Control Harzard)。例如跳转指令的(顺序)下一条指令是否应当执行,只有等到跳转指令指令执行完(流水线停顿),更新了PC寄存器,才能确定。除此之外还有什么方法解决控制冒险吗?答案是肯定的。
缩短分支延迟
以条件跳转指令为例,条件比较和实际跳转的opcode,条件码寄存器,还有要跳转的地址在ID阶段都能获得。这也就是说,可以另外设计旁路电路,将条件判断和地址跳转操作都提前到ID阶段,而不需要在EX阶段由ALU完成。这与前面提到的操作数转发实际上是异曲同工,都是将计算结果提前反馈给流水线。
但这样做并不能完全解决问题,跳转仍然要等到ID阶段结束才能完成,而这时应当已经完成了下一条指令的取指操作了,所以还是不可避免的产生一个时钟周期的流水线停顿。
分支预测
最简单的分支预测(branch Prediction)技术,叫作“假装分支不发生”。即CPU仍然按照顺序往下执行指令。这是一种静态预测技术。有50%的概率预测正确。如果预测失败,则需要对后面取出的指令中已经执行的部分做丢弃操作,这在流水线中叫做Zap或Flush。除了放弃后面的已经执行到一半的指令外,还需要做对应的清除操作,比如清空或还原寄存器中的数据等,而这些清除操作,都是有时间开销的。

动态分支预测
用一个比特,去记录当前分支的比较情况,直接用当前分支的比较情况,来预测下一次分支时候的比较情况的方法叫做一级分支预测(One Level Branch Prediction)或1比特饱和计数(1-bit saturating counter)。
一级分支预测的鲁棒性不强,我们可以引入状态机(State Machine)处理分支预测,如下图所示:
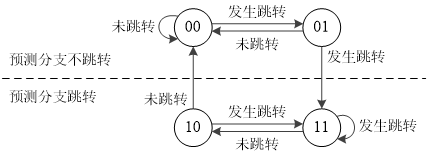
在这个状态机中,有4个状态,所以需要2个比特位来记录对应的状态。因此这种方法称为2比特饱和计数,或者叫双模态预测器(Bimodal Predictor)。
参考
[1] 深入浅出计算机组成原理
[2] 乱序执行所依赖的Tomasulo 算法
 wechat
wechat alipay
alipay
![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)