计算机体系结构 [6]:存储器层次结构
前言
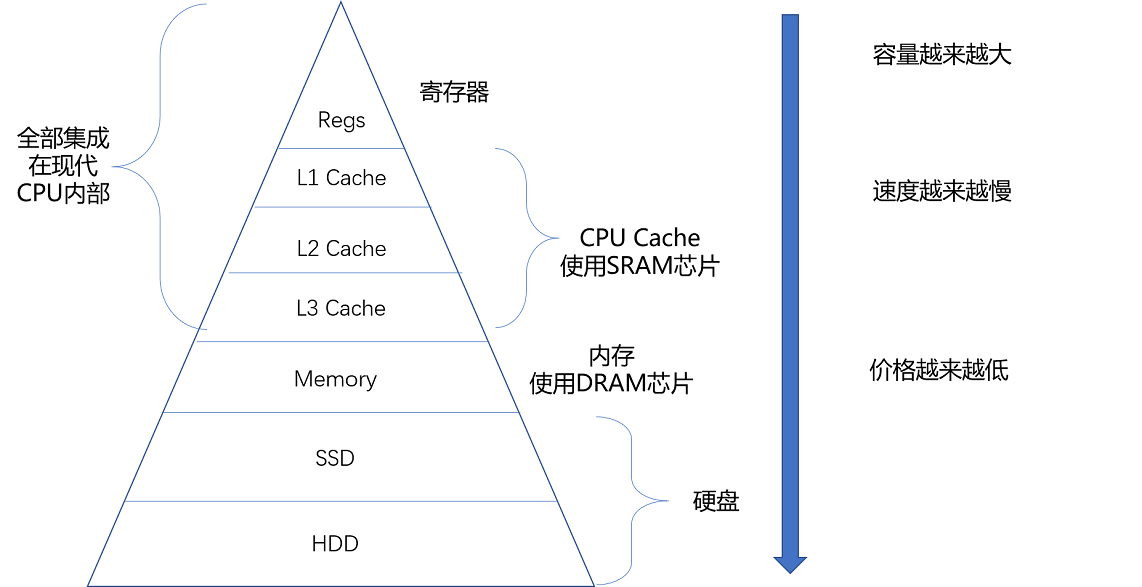
存储器的层次结构如下图所示:
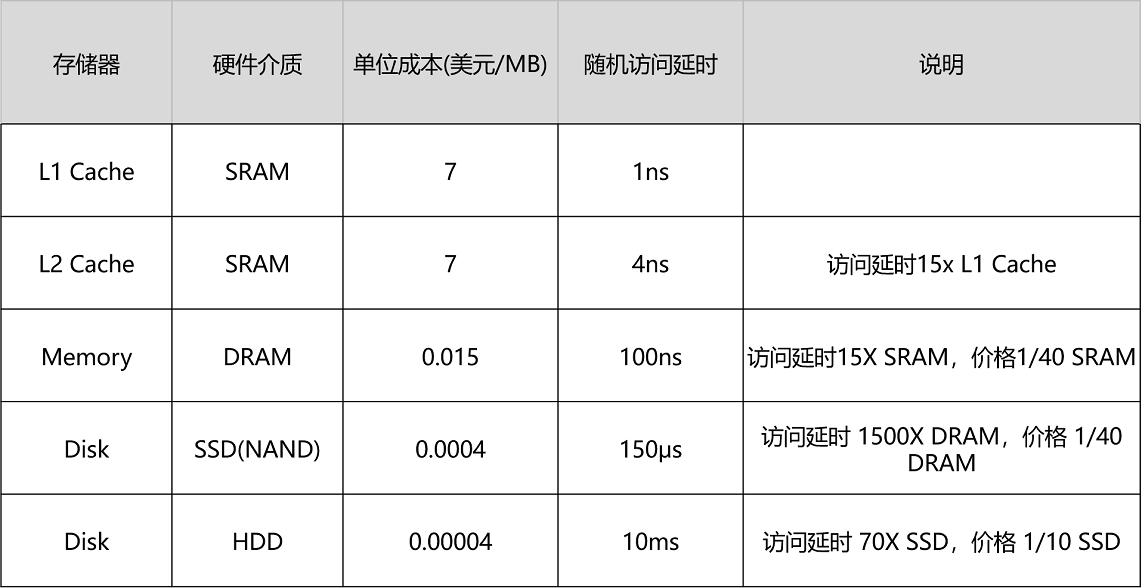
各类存储器的成本和延时对比如下图,一个历年硬件设备延时变化的链接:
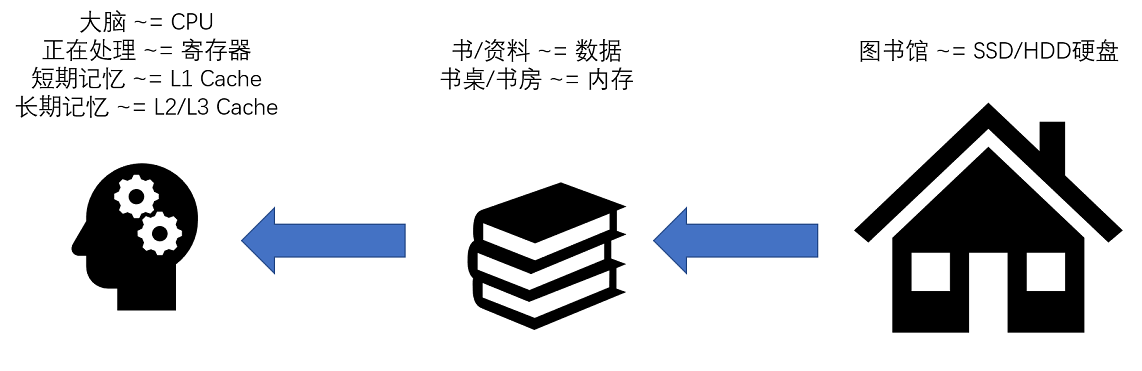
一个简单的类比如下图所示:
存储器层次结构的设计并不仅受成本层面的限制,更受物理层面的限制。L1 Cache不仅昂贵,其访问速度和它到 CPU 的物理距离有关。仅靠堆料并不能打破电信号不能超过光速的物理限制。
SRAM/Cache
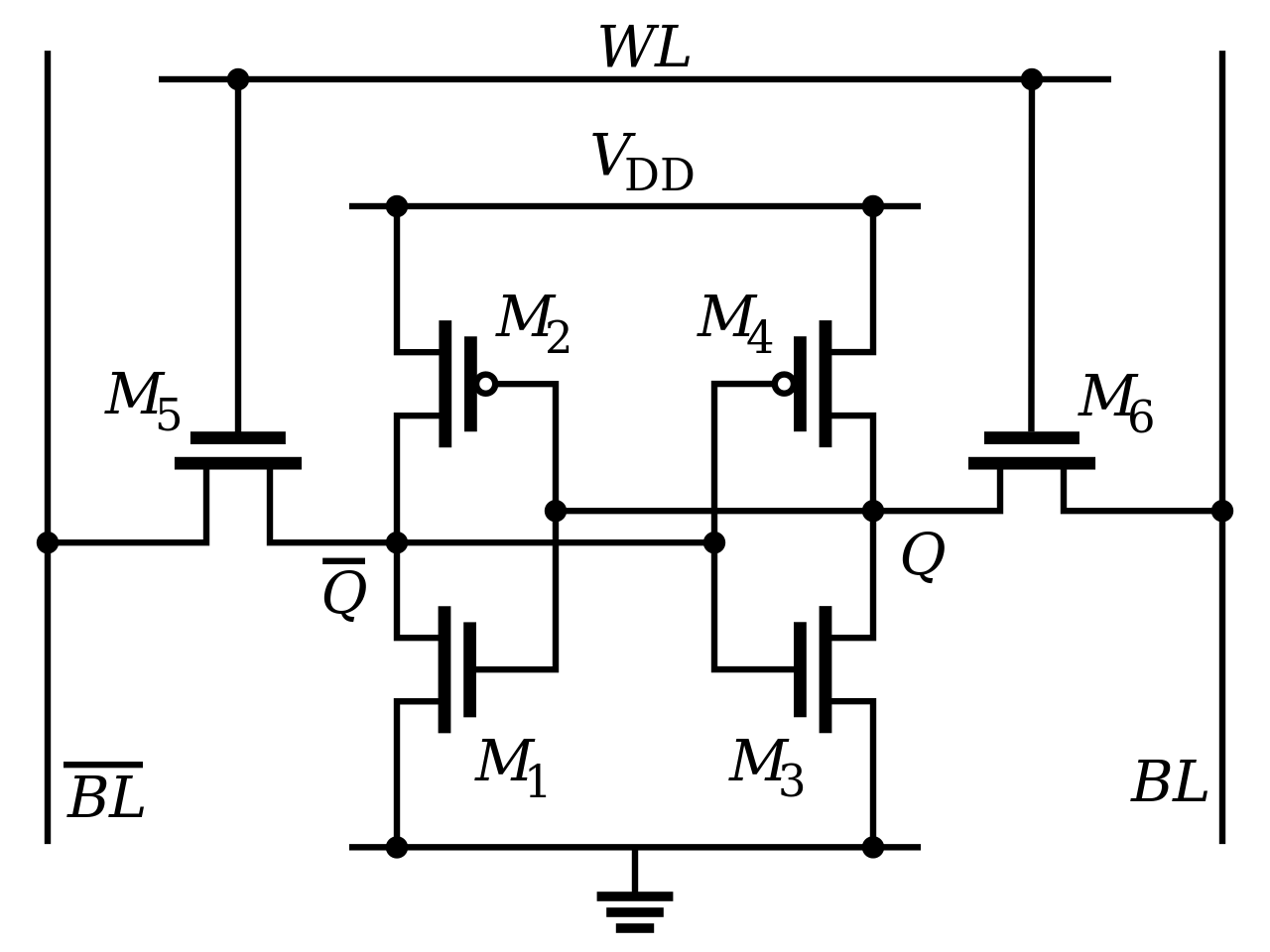
**SRAM(**Static Random-Access Memory,静态随机存取存储器),所谓静态,是只要处在通电状态,里面的数据就可以保持存在。而一旦断电,里面的数据就会丢失了。特点:存储密度不高(一个比特需要6-8个晶体管),但电路简单,访问速度非常快,一个6个晶体管组成一个比特的SRAM的示意图如下:
Cache通常分为L1、L2、L3三级:
- L1 Cache:嵌在每个CPU核心内部,访问速度最快。通常分成指令缓存和数据缓存(借鉴哈佛结构解决结构冒险问题);
- L2 Cache:同样每个CPU核心独有,但不在核心内部,访问速度略慢。
- L3 Cache:多个CPU核心共用,尺寸更大,但访问速度更慢。
为什么需要Cache?
随着硬件的发展,CPU性能和内存访问性能之间的差距越来越大,为了不让CPU因为等待来自内存的指令和数据而“原地空转”,引入了以SRAM作为介质的高速缓存Cache。
内存中的指令、数据,会被加载到 L1-L3 Cache 中,而不是直接由 CPU 访问内存去拿。在 95% 的情况下,CPU 都只需要访问 L1-L3 Cache,从里面读取指令和数据,而无需访问内存。
CPU 从内存中读取数据到 CPU Cache 的过程中,是一小块一小块来读取数据的,而不是按照单个数组元素来读取数据的。这样一小块一小块的数据单位叫作 Cache Line(缓存块)。
现代 CPU 中大量的空间已经被 SRAM 占据,下图中用红色框出的部分就是Intel CPU 中的 L3 Cache:
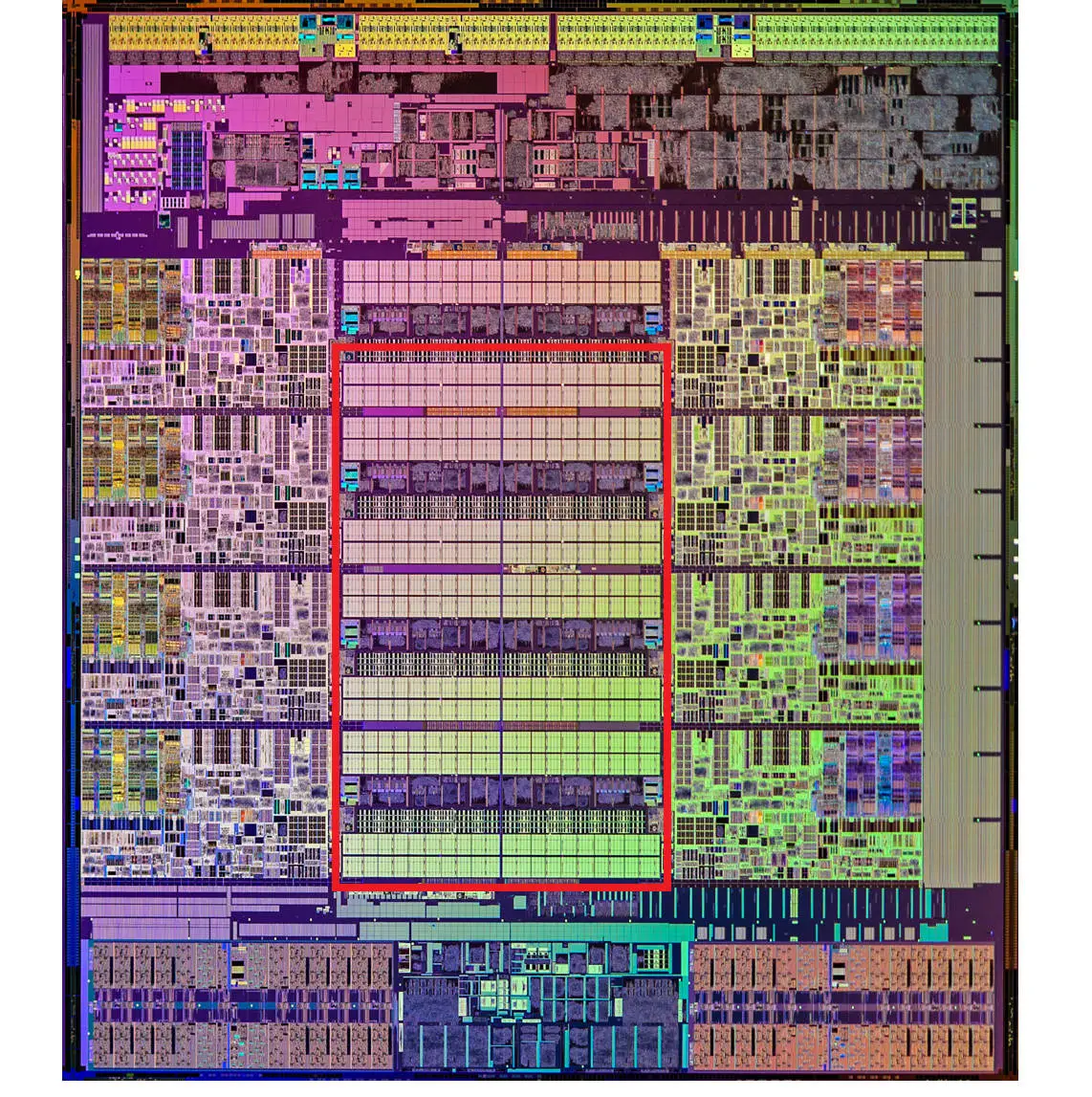
Cache访问逻辑
现代 CPU 进行数据读取的时候,无论数据是否已经存储在 Cache 中,CPU 始终会首先访问 Cache。只有当 CPU 在 Cache 中找不到数据的时候,才会去访问内存,并将待读取的数据以及其后一个Cache Line大小的数据写入 Cache 之中。当局部性原理起作用时,最近刚刚被访问的数据及其附近的数据,会很快再次被访问。而 Cache 的访问速度远远快于内存,这样,CPU 花在等待内存访问上的时间就会大大变短。
直接映射Cache
内存地址到Cache Line的映射关系如下图所示:
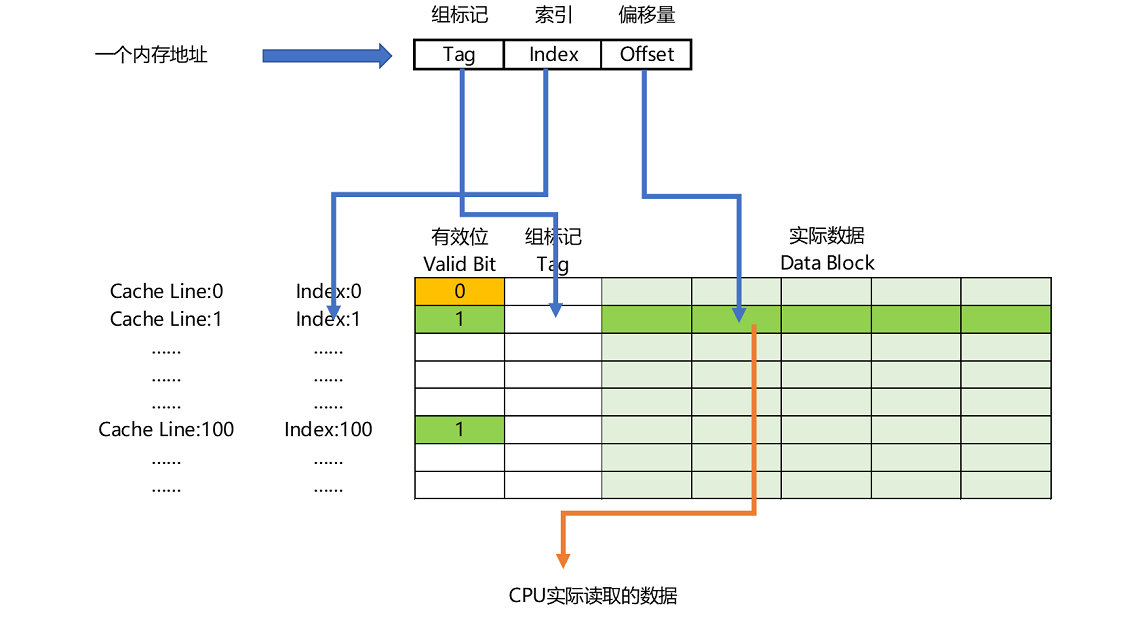
内存访问地址可以认为是组标记(Tag)、索引(Index)和偏移量(Offset)的组合。其中:
- 偏移量:为待读取的数据字在Cache Line的Data Block中的偏移地址,以Cache Line大小为64字节为例,偏移量在内存地址的最后6位。
- 索引:在直接映射Cache策略下,待读取数据所在的内存块始终映射到一个固定的Cache Line,而映射关系通常是通过mod(求余)运算实现。而mod运算就等于取地址的低N位。举个简单的例子,假设Cache Line个数为8,待读取数据为总计32个内存块中的第21个内存块,则对应到Cache Line的索引就是5。在实际计算中,mod操作其实就是取地址的中间N=3位得到索引值。
- 组标记:显而易见,mod操作会导致多个内存块对应同一个Cache Line,为了区分是哪一个内存块的数据被缓存到Cache Line中,需要将内存地址中剩余的高位组成组标记存储在Cache Line中。
- 有效位(Valid Bit):此外,Cache Line中还需要一个有效位来标记Cache line中的数据是从内存块中加载的有效数据,还是机器上电时的空(无效)数据。
有了上述的概念,那么一个完整的访存操作会有如下步骤:
-
- 根据内存地址的中间N位计算在Cache中的索引;
-
- 判断该索引对应的Cache Line的有效位,确认Cache中数据是否有效;
-
- 对比内存地址高位和Cache Line中的组标记,确认该Cache Line中数据是否为我们要访问的内存数据;
-
- 根据内存地址中的Offset位,从Cache Line的Data Block中读取希望访问的数据;
-
- 若2、3步骤判断为否,则CPU会访问内存,将对应的内存块加载到Cache Line中,同时更新有效位和组标记。
除直接映射Cache外,常见的缓存放置策略还有全相连 Cache(Fully Associative Cache)、组相连 Cache(Set Associative Cache)。
Cache写入同步问题
我们现在用的 Intel CPU,通常都是多核的。每一个 CPU 核里面,都有独属于自己的 L1、L2 的 Cache,然后再有多个 CPU 核共用的 L3 Cache和主内存。如下图所示:
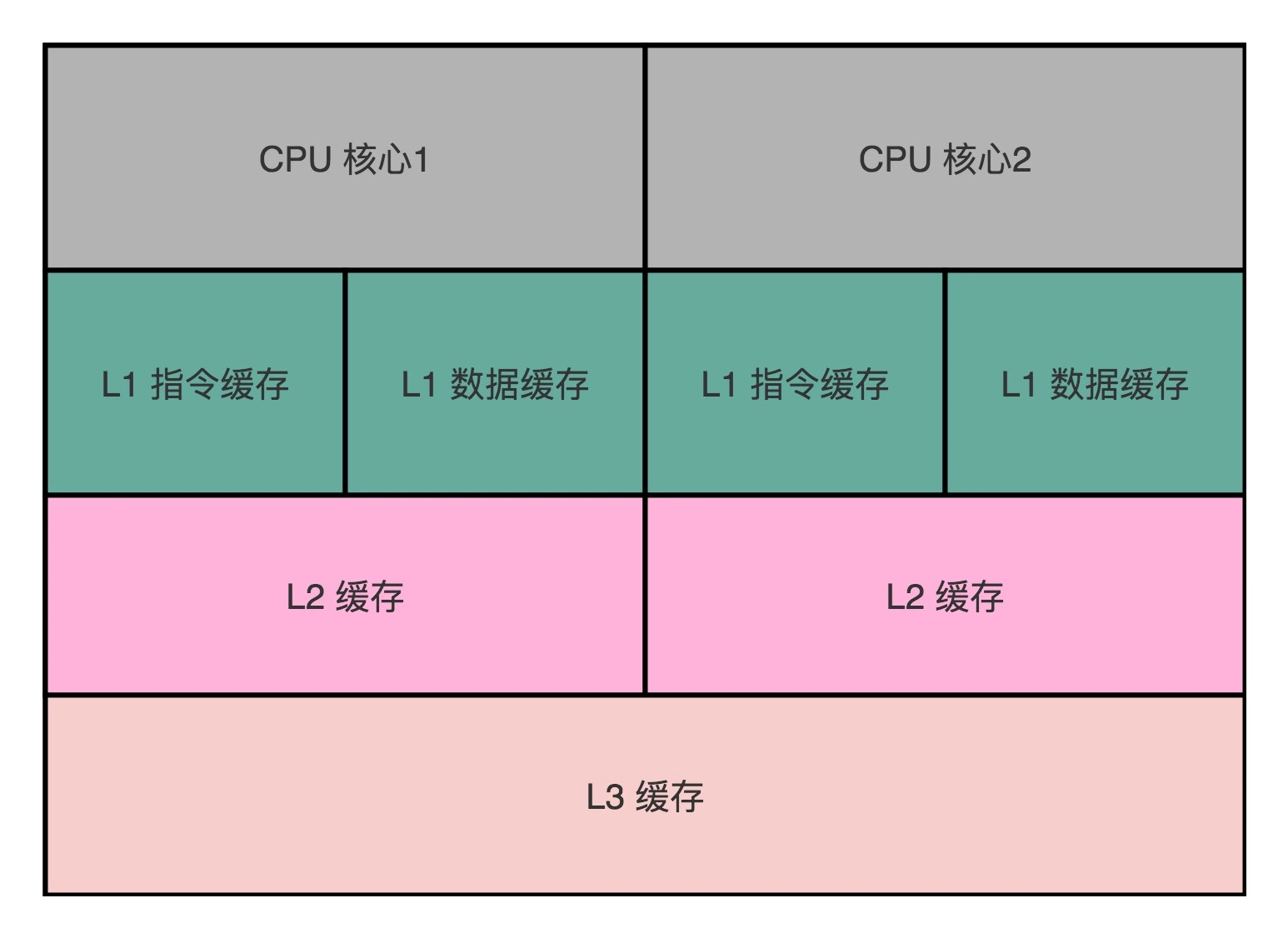
因为 CPU Cache 的访问速度要比主内存快很多,而在 CPU Cache 里面,L1/L2 的 Cache 也要比 L3 的 Cache 快。所以,上一讲我们可以看到,CPU 始终都是尽可能地从 CPU Cache 中去获取数据,而不是每一次都要从主内存里面去读取数据。
同样的,写入数据时写入Cache的速度也比写入主内存快,那我们写入数据到底时写入到Cache中,还是写入到主内存?如果直接写到主内存中,Cache中的数据是否就失效了?如果存在多个线程(多个CPU核),一个线程写了自己的L1/L2 Cache或主内存,其他线程的缓存是否需要同步(缓存一致性问题)?
首先回答第一个问题,这里介绍两种写入策略:
写直达(Write-Through)
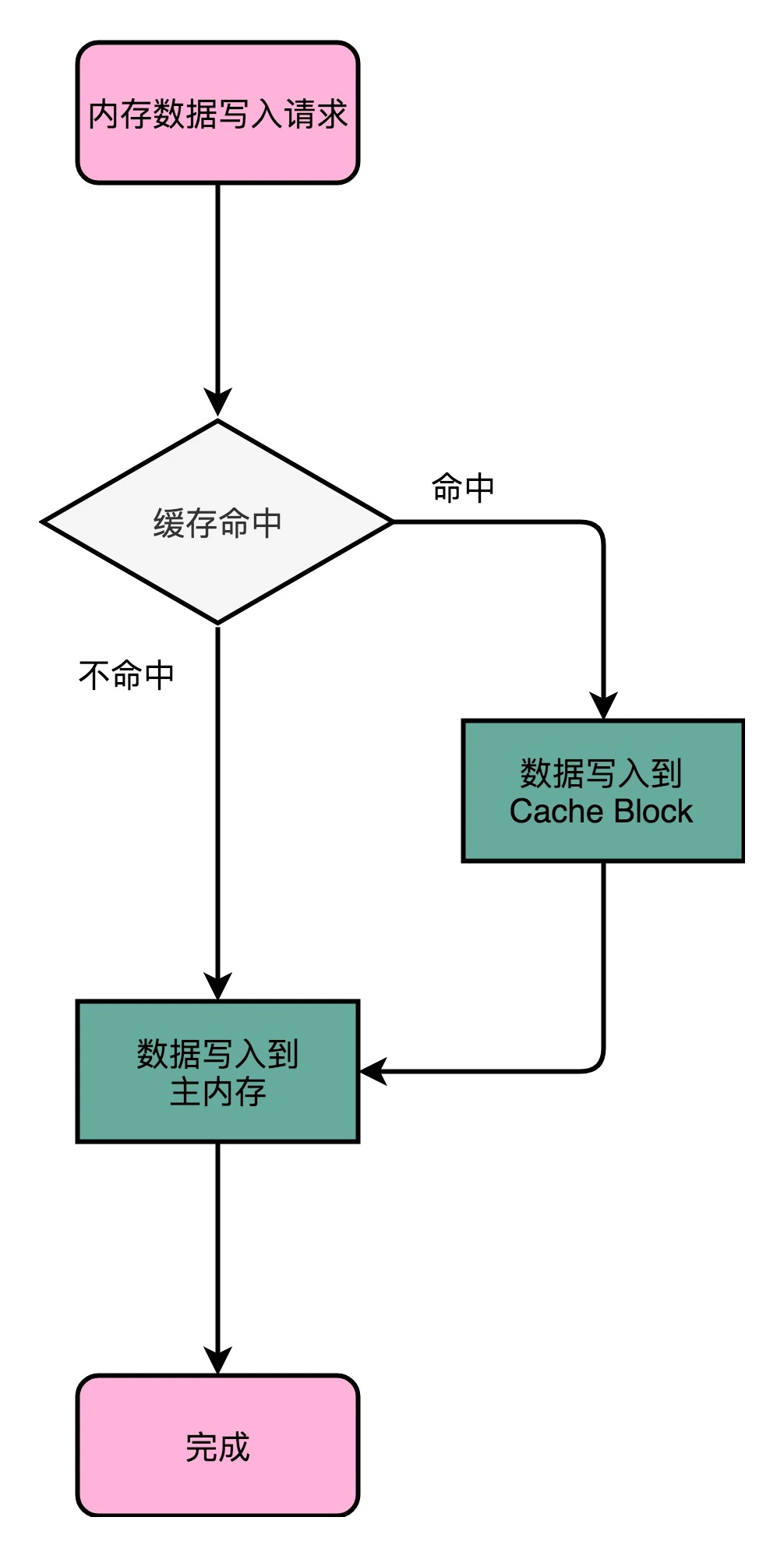
这个策略每次数据都会写入到主内存:如果缓存命中,就先把数据写入更新到Cache里,再写入到主内存;如果未命中,则直接写入主内存。
写直达策略逻辑很简单明了,但同样缺点也很明显,那就是很慢。
写回(Write-Back)
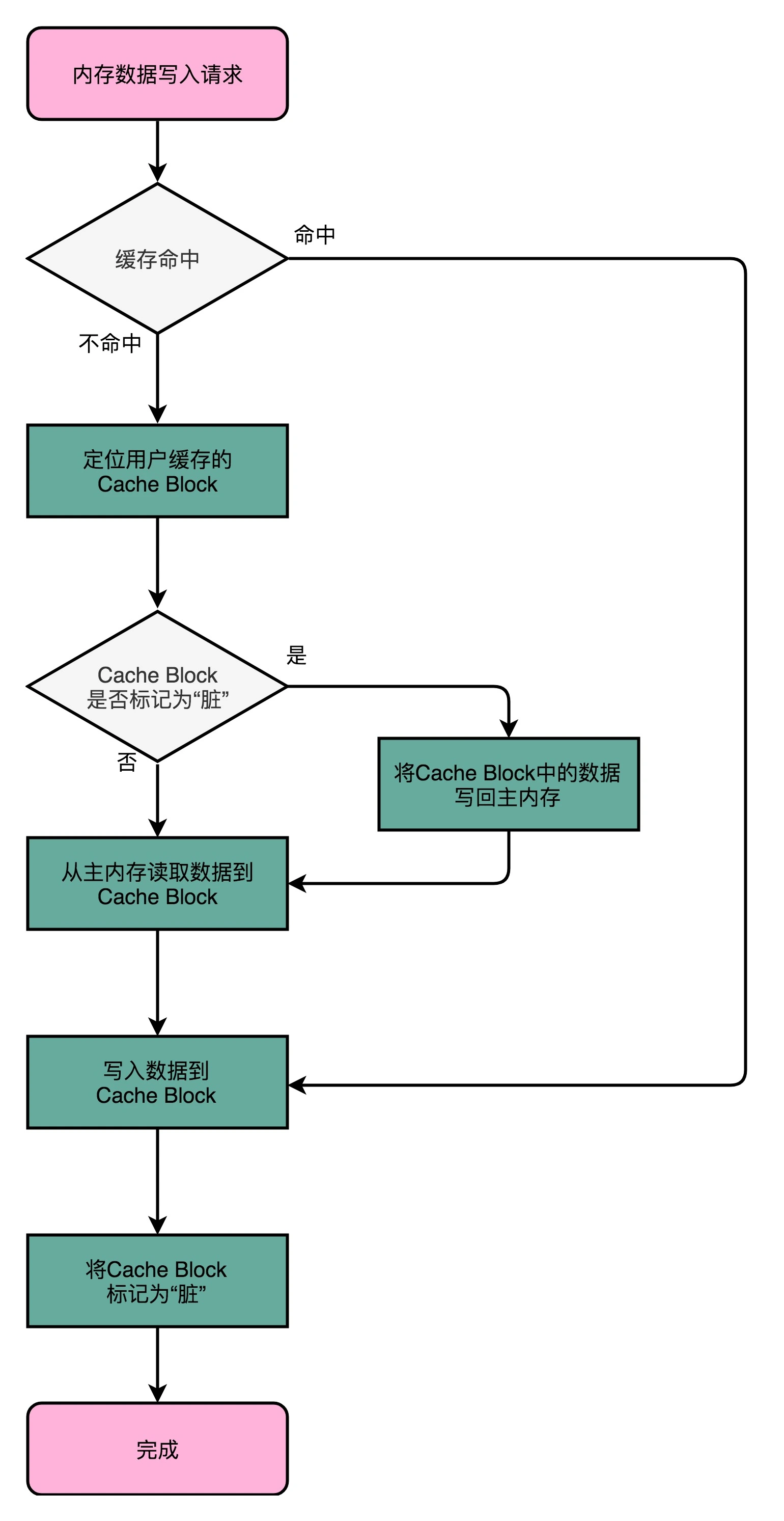
写回策略不用每次都把数据写入到主内存中,而只写到Cache中。只有当Cache里面的数据要被替换(映射关系变化)时,才需要将数据写入到主内存中。具体的流程如下:
如果发现我们要写入的数据命中了Cache,则只更新Cache中的数据,并标记该Cache Block(Cache Line)为脏的(Dirty),所谓Dirty,就是指该Block中的数据与主内存中是不一致的,需要同步。
如果待写入数据未命中Cache,则查看其索引对应的Cache Line是否被标记为Dirty。若是,则需要将该Cache Line中Data Block里的数据写回到对应的主内存中,再从待写入内存地址对应的主内存块中读取数据到Cache Line中(这一步不是多余的,因为后续写入Cache Line 的数据只是Data Block中的一部分),再把当前要写入的数据写入到Cache Line中,并标记该Cache Line为Dirty;若否,则跳过将Cache Block中数据写回对应主内存的操作,直接执行后续步骤。
当采用写回策略时,读取内存数据的操作同样也要判断Dirty标记:若要加载主内存中的数据到Cache中,且该Cache Line被标记为Dirty,则要先将数据写回到对应的主内存块中,则执行加载操作覆盖该Cache Line。
可以看到,写回策略的目的就是让写入内存操作尽可能只与Cache交互,实在不行了再去读写主内存,从而提升性能。
总线嗅探机制与MESI协议
但是,无论是写回还是写直达,都还没有解决多线程(多CPU核)情况下的缓存一致性(Cache Coherence)问题,为此我们需要解决以下两个问题:
- 写传播(Write Propagation):即一个CPU核中的Cache更新,要能够传播到其他核心的对应Cache Line中;
- 事务串行化(Transaction Serialization):在一个或多个CPU核心里的读取和写入操作,在其他核心看来,是(按时间先后)顺序一致的。要做到事务串行化,需要实现两点:第一,一个CPU核心对数据的操作,要同步通信给其他CPU核心;第二,如果两个CPU核心有同一个数据的Cache,则需要对该Cache数据的更新加锁。
可以通过总线嗅探(Bus Snooping)机制用来解决写传播问题。即把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。
基于总线嗅探机制,还可以分成很多种不同的缓存一致性协议:
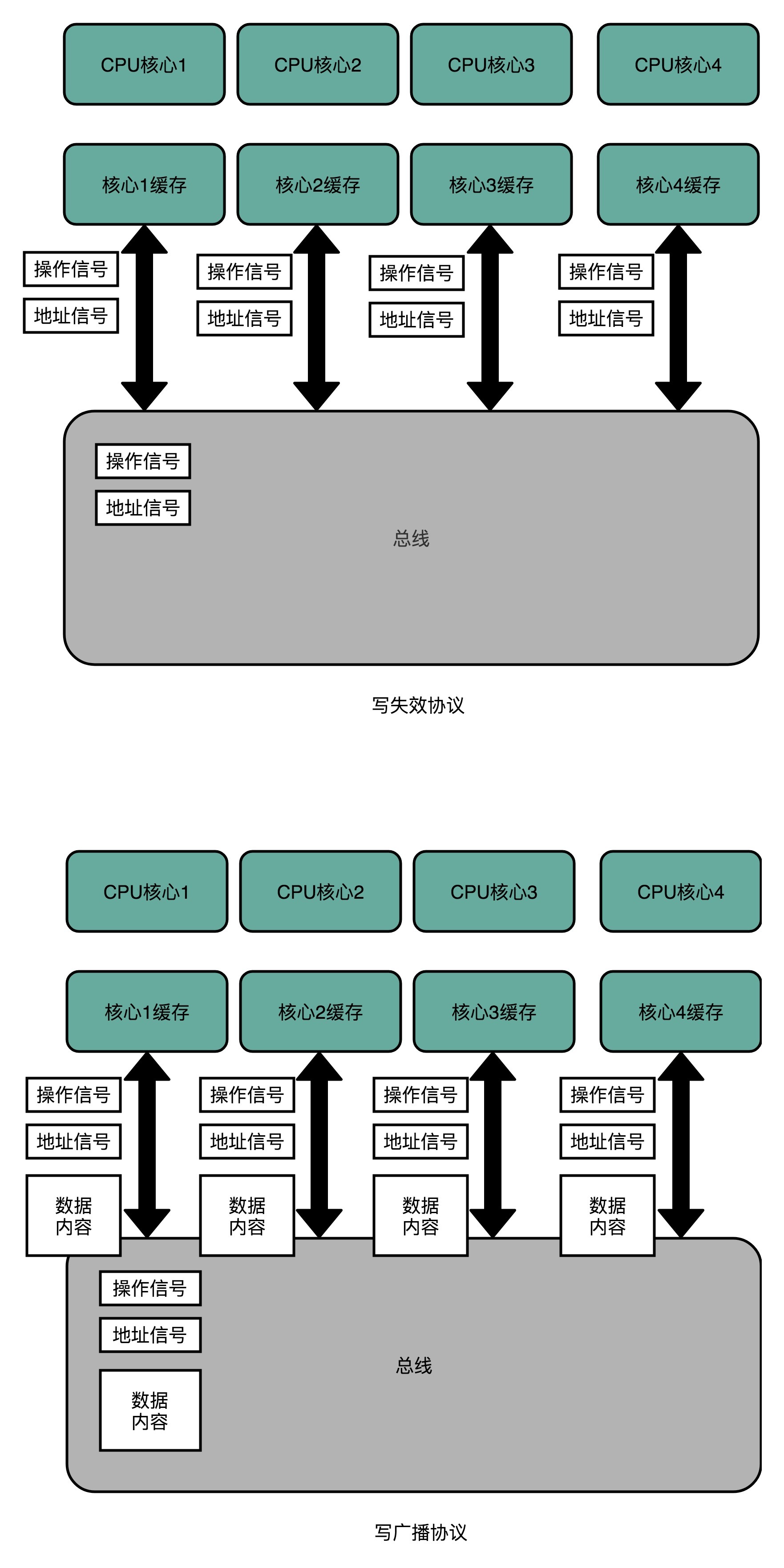
- 写失效(Write Invalidate)协议:只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。
- 写广播(Write Broadcast)协议:一个写入请求会广播到所有的 CPU 核心,同时更新各个核心里的 Cache。
写广播在实现上很简单,但需要占用更多的总线带宽。写失效只需要广播失效的内存地址,而写广播还需要把对应的数据广播给其他 CPU 核心。
而其中最常用的是MESI协议,它是一种写失效协议。MESI代表该协议下Cache Line的四种状态标记:
-
M:已修改(Modified),Dirty状态,表示Cache Line的数据已经更新,但没有写回主内存;
-
E:独占(Exclusive),Clean状态,Cache Line中数据与主内存一致,且没有其他核加载对应的数据到自己的Cache中。对独占状态Cache Line 写入数据,不需要广播给其他CPU核;
-
S:共享(Shared),Clean状态,Cache Line中数据与主内存一致,有其他核加载了同一块数据到自己的Cache中。更新共享状态的Cache Line数据,不能直接修改,要先广播要求其他CPU核将对应的Cache Line置为已失效状态,然后才能更新当前核Cache中的数据。这个广播操作,一般叫做RFO(Request For Ownership),类似于一种加锁操作,同一时间内只有一个CPU核能执行写入操作。
-
I:已失效(Invalidated),Dirty状态,Cache Line中数据不是最新的,其他核中对应的Cache Line的数据已修改,但没有同步到当前核;
整个MESI的状态流转,可以用一个有限状态机来表征。这里触发状态切换的事件,可能是来自当前核(本地),也可能是来自其他核通过总线广播的信号。
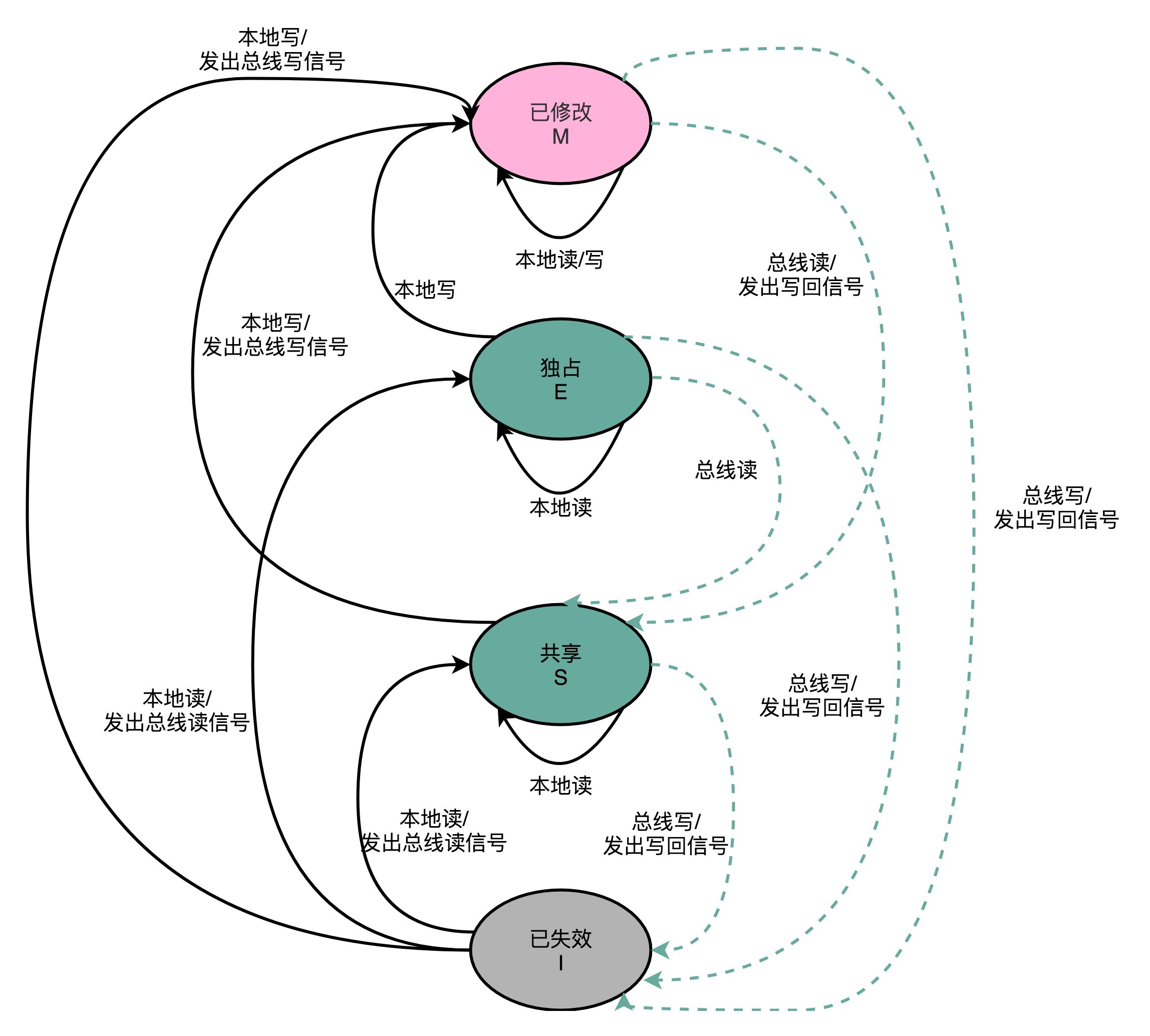
举一个简单的例子:
-
假设初始状态为:CPU 核A中某Cache Line状态为M,核B中相应的Cache Line状态为I;
-
此时核B需要需要读取该Cache Line中数据(本地读),由于此时的状态I不满足读请求条件,便会通过总线广播请求(发出总线读信号);
-
此时核A嗅探到总线上的读请求(总线读),便会将其对应Cache Line中数据写回主内存(发出写回信号),并且Cache Line 状态切换到S(M->S);
-
此时内存中数据更新到最新,核B的本地读操作得以继续完成,将数据从内存加载到Cache Line中,并交由CPU核处理。并且将Cache Line 状态切换为S(I->S);
-
结束状态为:CPU 核A中某Cache Line状态为S,核B中相应的Cache Line状态为S;
上述示例中的触发事件及状态切换的流程与图中一一对应,也尝试代入其他场景进行理解。
至此,我们通过MESI协议解决了多CPU核情况下的缓存一致性问题。
DRAM/内存
DRAM(Dynamic Random Access Memory,动态随机存取存储器),所谓动态,是因为DRAM数据是存储在电容里的,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。特点:存储密度更大(一个比特只需要一个晶体管和一个电容存储),但DRAM的数据访问电路和刷新电路都要比SRAM更复杂,所以访问延时更长。
在这篇文章中,我们简单讨论了一下程序装载时依赖的内存分页(Paging)机制,现在我们就来看一下虚拟内存地址和物理内存地址是如何转换的。
简单页表
存放虚拟内存页到物理内存页的映射关系的映射表,叫做页表(Page Table)。页表会把一个内存地址分成页号(Directory)和偏移量(Offset)两个部分。以一个8位的地址为例,假设一个页的大小是8(2^3)字节,则高5位为页号,低3位为偏移量。则从虚拟内存地址到物理内存地址的转换就是如下三个步骤:
-
把虚拟内存地址,切分成页号和偏移量的组合;
-
从页表里面,查询出虚拟页号对应的物理页号;
-
直接拿物理页号拼接上前面的偏移量,就得到了物理内存地址。
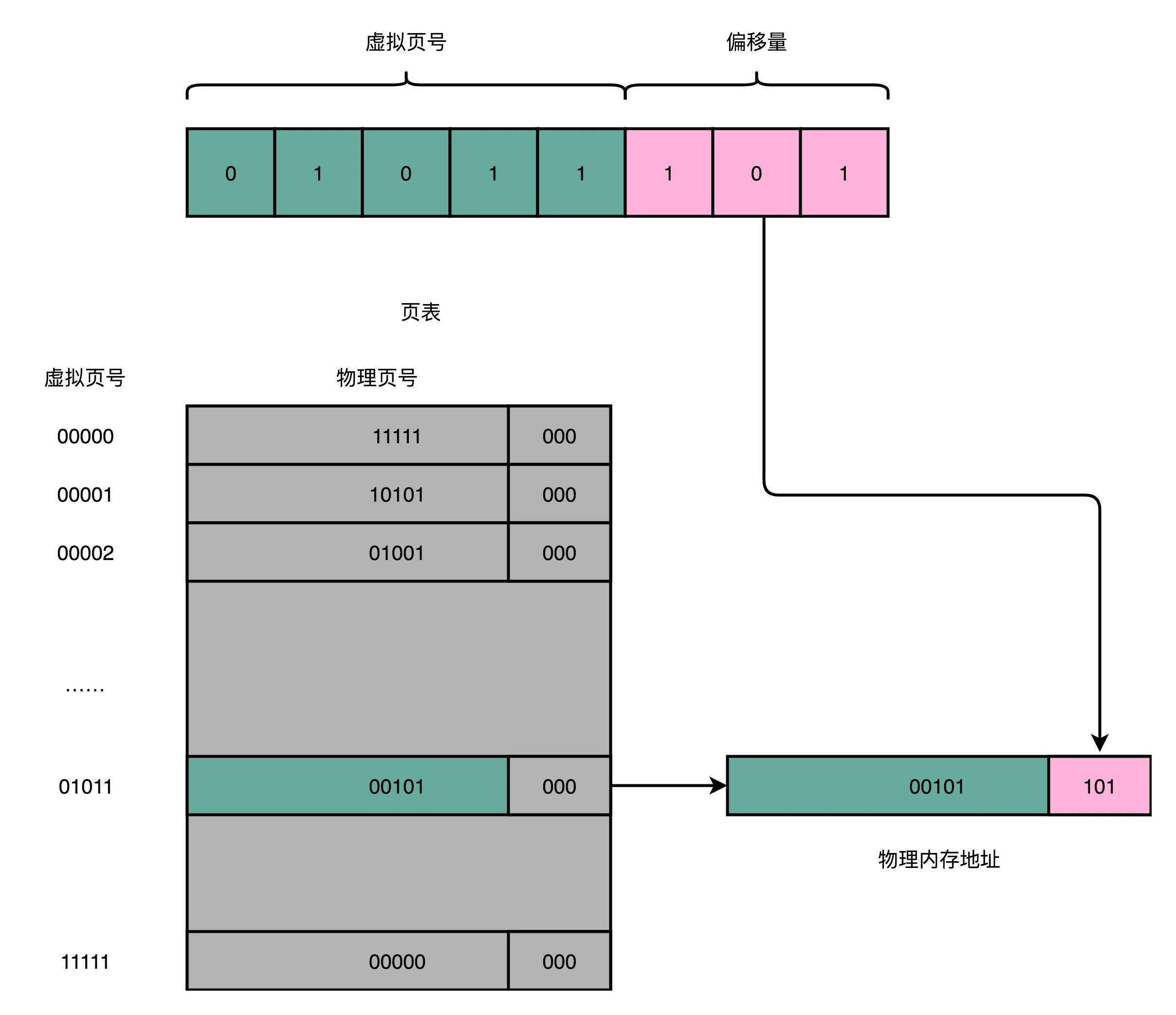
但简单页表的问题也很明显,就是页表本身的内存占用比较大,以32位地址,单页4K(2^12)字节为例,则高20位为页号,简单页表则需要记录2^20个映射关系,每个映射关系用4字节保存,则简单页表的总大小为2^22字节,即4M字节,看起来并不大?但是每个程序的进程都需要维护一份自己独立的4M页表,即便这个程序本身只有几K大小。进程多了,占用的内存量也是很可观的。况且现在都是64位操作系统了,还是用这种简单粗暴的方式,显然不合适。
多级页表
很容易想到的是,我们并不需要存下所有内存地址的映射关系,每个进程所占用的内存是有限的,需要的页自然也是有限的。我们只需要去存那些用到的页之间的映射关系就好了。在实践中,我们通常采用的是一种叫作多级页表(Multi-Level Page Table)的方法存放映射关系。
进程的内存地址空间,通常是“两头实、中间空”。栈空间(编译时就确定了大小)自顶而下(低地址到高地址)。堆空间自底而上(高地址到低地址)动态分配。因此,虚拟内存占用的地址空间,通常是两段连续的空间。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。
以一个4级的多级页表为例,虚拟内存地址被拆分成4级页表索引+偏移量的形式,如下图:
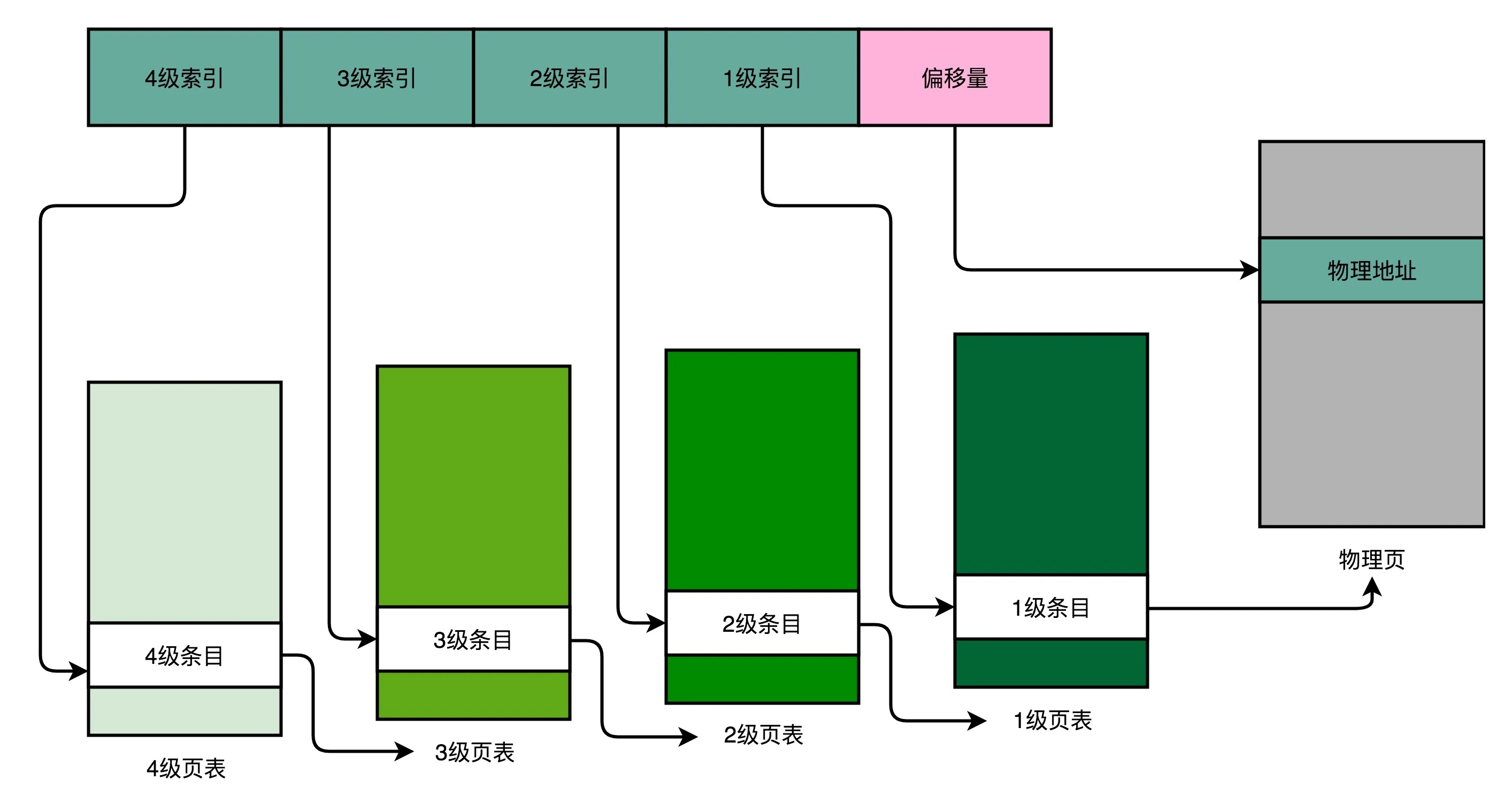
相应的,每个进程有且只有一张4级页表,我们先通过 4 级页表索引,找到 4 级页表里面对应的条目(Entry)。这个条目里存放的是一张 3 级页表所在的位置。4 级页面里面的每一个条目,都对应着一张 3 级页表,所以我们可能有多张 3 级页表。
找到对应这张 3 级页表之后,我们用 3 级索引去找到对应的 3 级索引的条目。3 级索引的条目再会指向一个 2 级页表。同样的,2 级页表里我们可以用 2 级索引指向一个 1 级页表。
而最后一层的 1 级页表里面的条目,对应的数据内容就是物理页号了。在拿到了物理页号之后,我们同样可以用“页号 + 偏移量”的方式,来获取最终的物理内存地址。至此,完成了从虚拟内存地址到物理内存地址的映射。
我们可能有多张 1 级页表、2 级页表,乃至 3 级页表。但是,因为实际的虚拟内存空间通常是连续的(即整个进程所占用的内存空间的4级索引,3级索引乃至2级索引可能都是一样的),我们很可能只需要很少的 2 级页表,甚至只需要 1 张 3 级页表就够了。
事实上,多级页表就像一个多叉树的数据结构,所以我们常常称它为页表树(Page Table Tree)。因为虚拟内存地址分布的连续性,树的第一层节点的指针(4级索引/条目),很多就是空的,也就不需要有对应的子树了。所谓不需要子树,其实就是不需要对应的 2 级、3 级的页表。如下图所示:
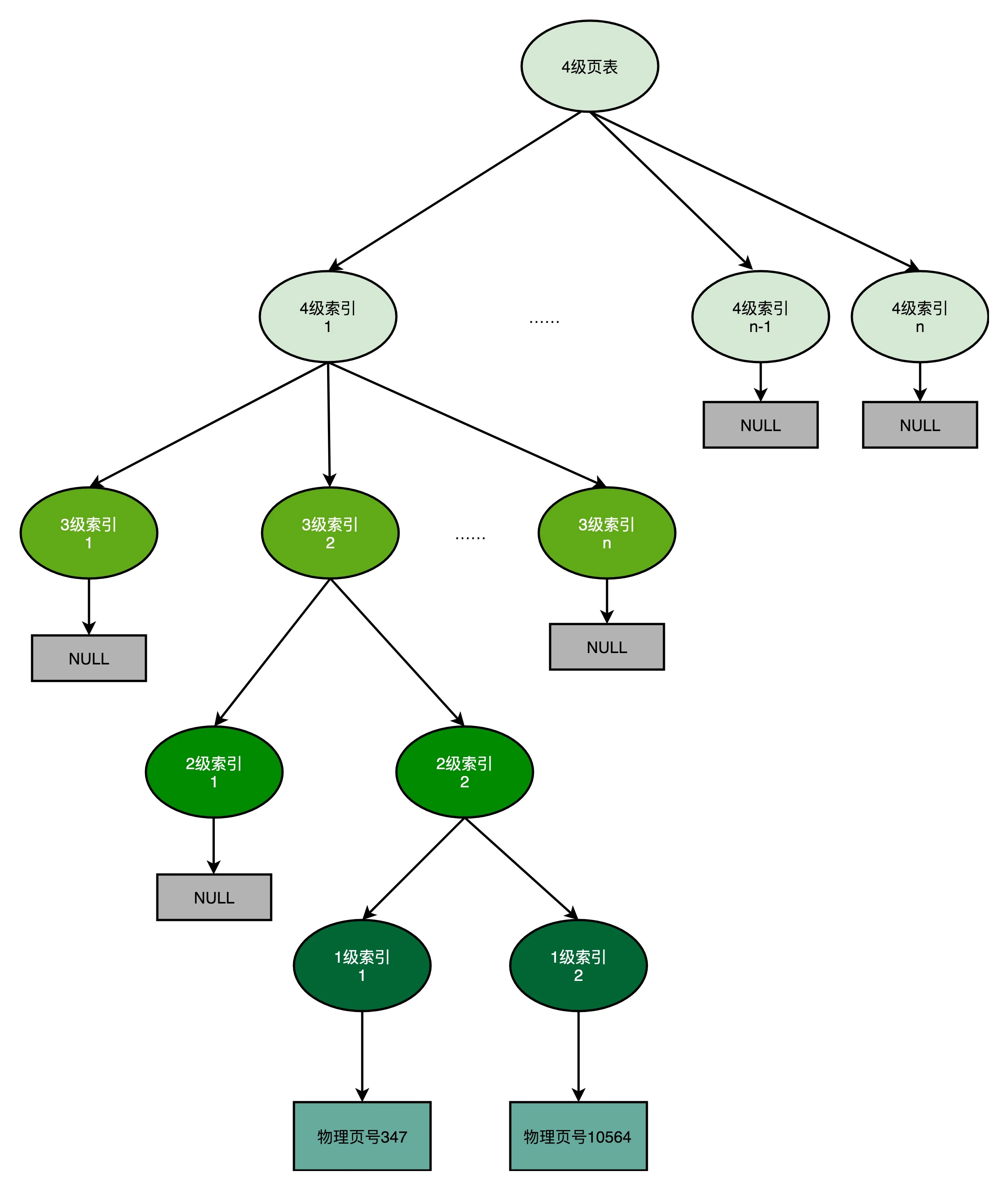
现在我们来简单测算一下多级页表的内存占用情况:假设偏移量仍然是12位,即单页内存大小为4KB,4级索引平均分配,每级索引占用5位,则每张页表中的条目个数为32(2^5)个,每个条目对应下一级页表的地址或者物理内存地址的页号,用4字节保存,这样每张页表的大小为128字节。对一张1级页表而言,这128字节对应的物理内存空间为32*4KB=128KB,而对于一张2级页表而言,这128字节对应32张1级页表,对应的物理内存空间为32*128KB=4MB。
假设一个进程如果占用了 8MB 的内存空间,分成了 2 个 4MB 的连续空间。那么,它一共需要 2 个独立的、填满的 2 级页表,也就意味着有 64 个 1 级页表,2 个独立的 3 级页表(至于为啥不把两个对应2级页表的条目放到一个3级页表中,可能是因为堆和栈是两端分布,内存不连续吧),1 个 4 级页表。一共需要 69 个索引表,每个 128 字节,不到 9KB 的空间。比起简单页表的 4MB 来说,只有差不多 1/500。
但是,多级页表虽然节约了页表的存储空间,却多次查表操作带来了时间开销上的增加,是一种时间换空间的策略。原本我们进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是用了 4 级页表,我们就需要访问 4 次内存,才能找到物理页号。内存访问比Cache要慢的多,而内存映射是一个非常高频的动作,此时性能问题又凸显出来了。怎么解决呢?但凡涉及到局部性原理的问题,都可以通过加个缓存的方法来解决。
局部性原理
局部性原理(Principle of Locality)包括时间局部性(temporal locality)和空间局部性(spatial locality),利用原理,可以指定管理和访问数据的策略。
时间局部性:如果一个数据被访问了,那么它在短时间内还会被再次访问。
空间局部性:如果一个数据被访问了,那么和它相邻的数据也很快会被访问。
地址变换高速缓存(TLB)
程序所需要使用的指令,都顺序存放在虚拟内存里面。我们执行的指令,也是一条条顺序执行下去的。这就存在空间局部性和时间局部性。即我们连续执行了5条指令,这5条指令的内存地址是连续的,因此通常是在一个虚拟内存页内,即页号是相同的,那做了内存地址转换后,自然也在同一个物理内存页,是同一个物理页号。那其实不用每条指令都做一次地址转换,而是通过加个缓存的方法,把之前的内存转换地址缓存下来,使得我们不需要反复去访问内存来进行内存地址转换。
CPU 里有一块缓存芯片,称为地址变换高速缓冲(Translation-Lookaside Buffer,TLB)。这块缓存存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,我们可以直接在 TLB 里面查询结果,而不需要多次访问内存来完成一次转换。
TLB 和 CPU 的高速缓存类似,可以分成指令的 TLB(ITLB)和数据的 TLB(DTLB)。同样的,也可以根据大小对它进行分级,变成 L1、L2 这样多层的 TLB。
还有一点和 CPU 里的高速缓存也是一样的,需要用脏标记这样的标记位,来实现“写回”这样缓存管理策略。
出于性能考虑,整个内存转换过程是由硬件来执行的。在 CPU 芯片里面,我们封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换以及对 TLB 的访问和交互。
内存保护(Memory Protection)
可执行空间保护(Executable Space Protection)
对于一个进程使用的内存,只把其中的指令部分设置成“可执行”的,对于其他部分,比如数据部分,不给予“可执行”的权限。
因为无论是指令,还是数据,在我们的 CPU 看来,都是二进制的数据。我们直接把数据部分拿给 CPU,如果这些数据解码后,也能变成一条合理的指令,其实就是可执行的。黑客进行攻击的一种方式就是,在程序的数据区里,放入一些要执行的指令编码后的数据,然后找到一个办法,让 CPU 去把它们当成指令去加载,那 CPU 就能执行黑客想要执行的指令了。这时如果对进程里内存空间的执行权限进行控制,可以使得 CPU 只能执行指令区域的代码。对于数据区域的内容,即使找到了其他漏洞想要加载成指令来执行,也会因为没有权限而被阻挡掉。
地址空间布局随机化(Address Space Layout Randomization)
还有一种攻击方式就是,其他的人、进程、程序,会去修改掉特定进程的指令、数据,然后,让当前进程去执行这些指令和数据,造成破坏。要想修改这些指令和数据,则需要知道这些指令和数据所在的位置才行。
原先我们一个进程的内存布局空间是固定的,所以任何第三方很容易就能知道指令在哪里,程序栈在哪里,数据在哪里,堆又在哪里。这个其实为想要搞破坏的人创造了很大的便利。而地址空间布局随机化这个机制,就是让这些区域的位置不再固定,在内存空间随机去分配这些进程里不同部分所在的内存空间地址,让破坏者猜不出来。猜不出来呢,自然就没法找到想要修改的内容的位置。如果只是随便做点修改,程序只会 crash 掉,而不会去执行计划之外的代码。
总线
在现代的 Intel CPU 的体系结构下,通常有好几条总线。
首先,CPU 和内存以及高速缓存通信的总线通常有两种。这种方式,我们称之为双独立总线(Dual Independent Bus,缩写为 DIB)。一个是高速的本地总线(Local Bus),或者称为后端总线(Back-side Bus),用来与高速缓存通信;以及一个速度相对较慢的前端总线(Front-side Bus),或者称为处理器总线(Processor Bus)、内存总线(Memory Bus),用来和主内存以及输入输出设备通信。
而CPU 里面的北桥芯片,把我们上面说的前端总线,一分为二,变成了三个总线,如下图所示:
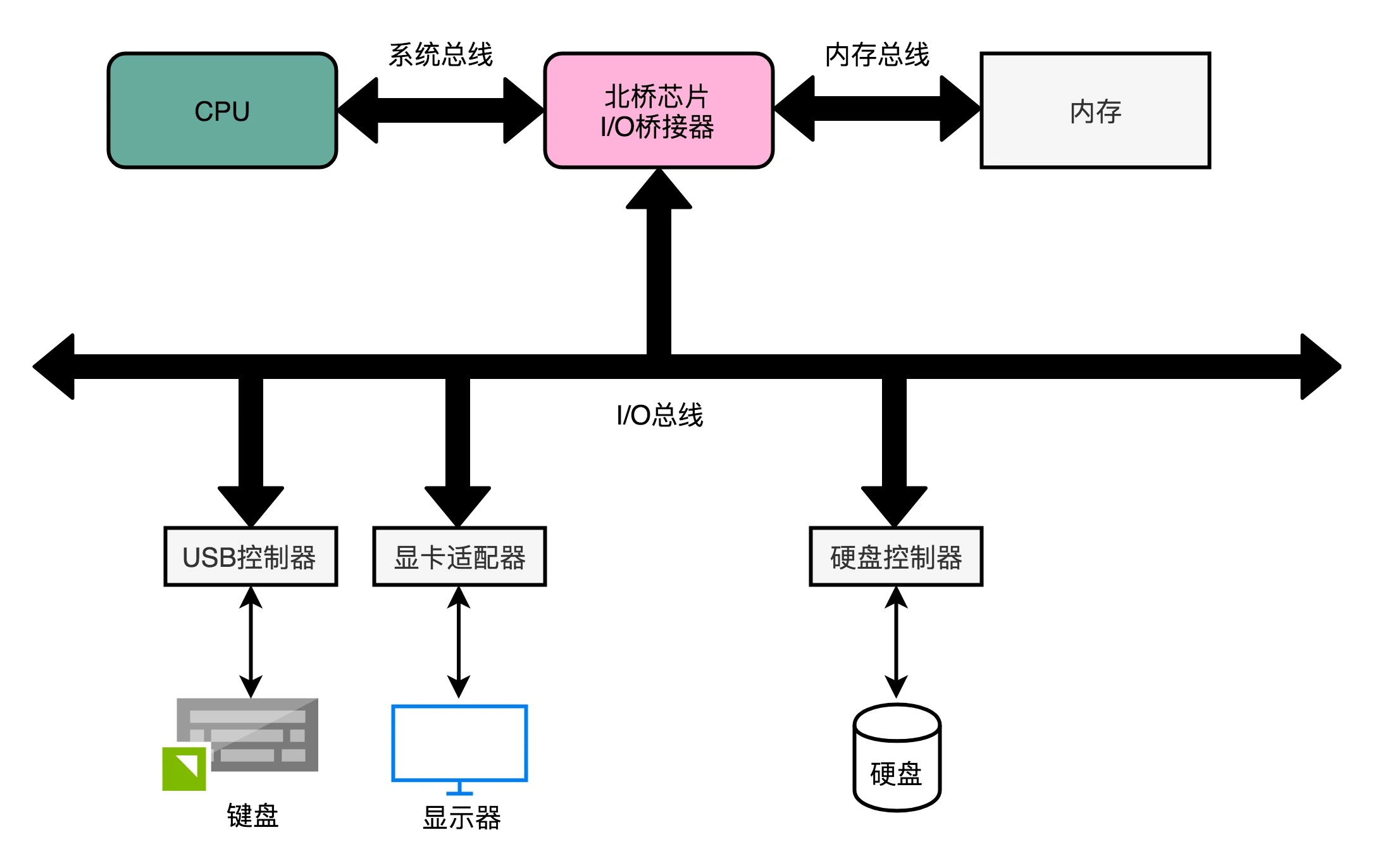
前端总线,其实就是系统总线。CPU 里面的内存接口,直接和系统总线通信,然后系统总线再接入一个 I/O 桥接器(I/O Bridge)。这个 I/O 桥接器,一边接入了内存总线,用于CPU 和内存通信;另一边接入了一个 I/O 总线,用来连接 I/O 设备。
真实的计算机里,I/O总线拆分得更细。根据不同的设备,还会分成独立的 PCI 总线、ISA 总线等。
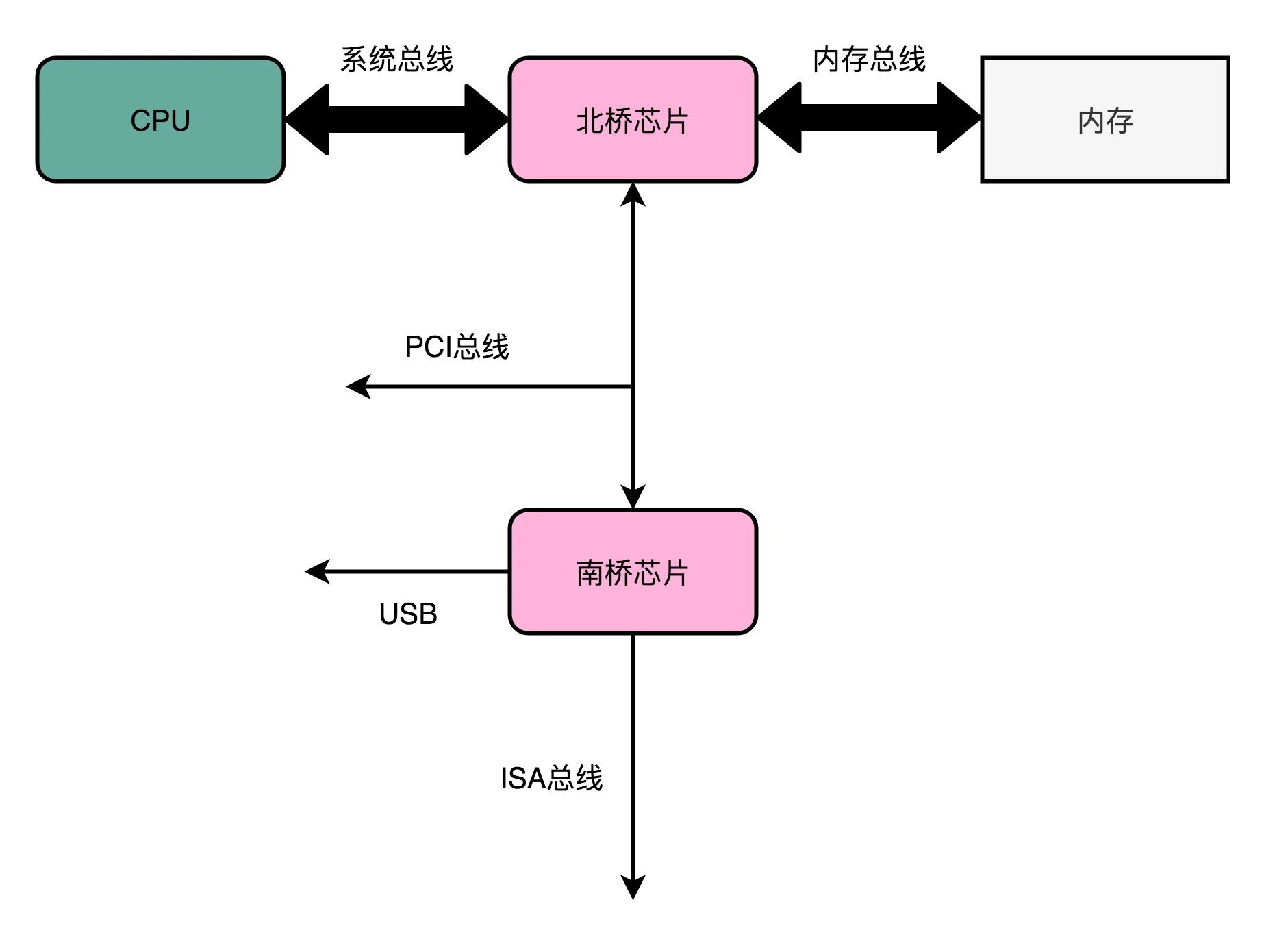
在物理层面,其实我们完全可以把总线看作一组“电线”。这些电线之间也是有分工的,通常有三类:
-
数据线(Data Bus),用来传输实际的数据信息;
-
地址线(Address Bus),用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备;
-
控制线(Control Bus),用来控制对于总线的访问。
尽管总线减少了设备之间的耦合,也降低了系统设计的复杂度,但同时也带来了一个新问题,那就是总线不能同时给多个设备提供通信功能。这时就需要引入总线裁决(Bus Arbitraction)机制。
CPU 如何 与 I/O设备通信呢?
对应没有专门的用于和I/O设备通信的指令的精简指令集而言,访问I/O设备就和访问我们的主内存一样,使用“内存地址”。为了让已经足够复杂的 CPU 尽可能简单,计算机会把 I/O 设备的各个寄存器,以及 I/O 设备内部的内存地址,都映射到主内存地址空间里来。主内存的地址空间里,会给不同的 I/O 设备预留一段一段的内存地址。CPU 想要和这些 I/O 设备通信的时候呢,就往这些地址发送数据。地址信息通过地址总线来发送,而对应的数据信息通过数据总线来发送。
而I/O 设备就会监控地址线,并且在 CPU 往自己地址发送数据的时候,把对应的数据线里面传输过来的数据,接收到设备里面的寄存器和内存里面来。这种方式叫作内存映射IO(Memory-Mapped I/O,简称 MMIO)。
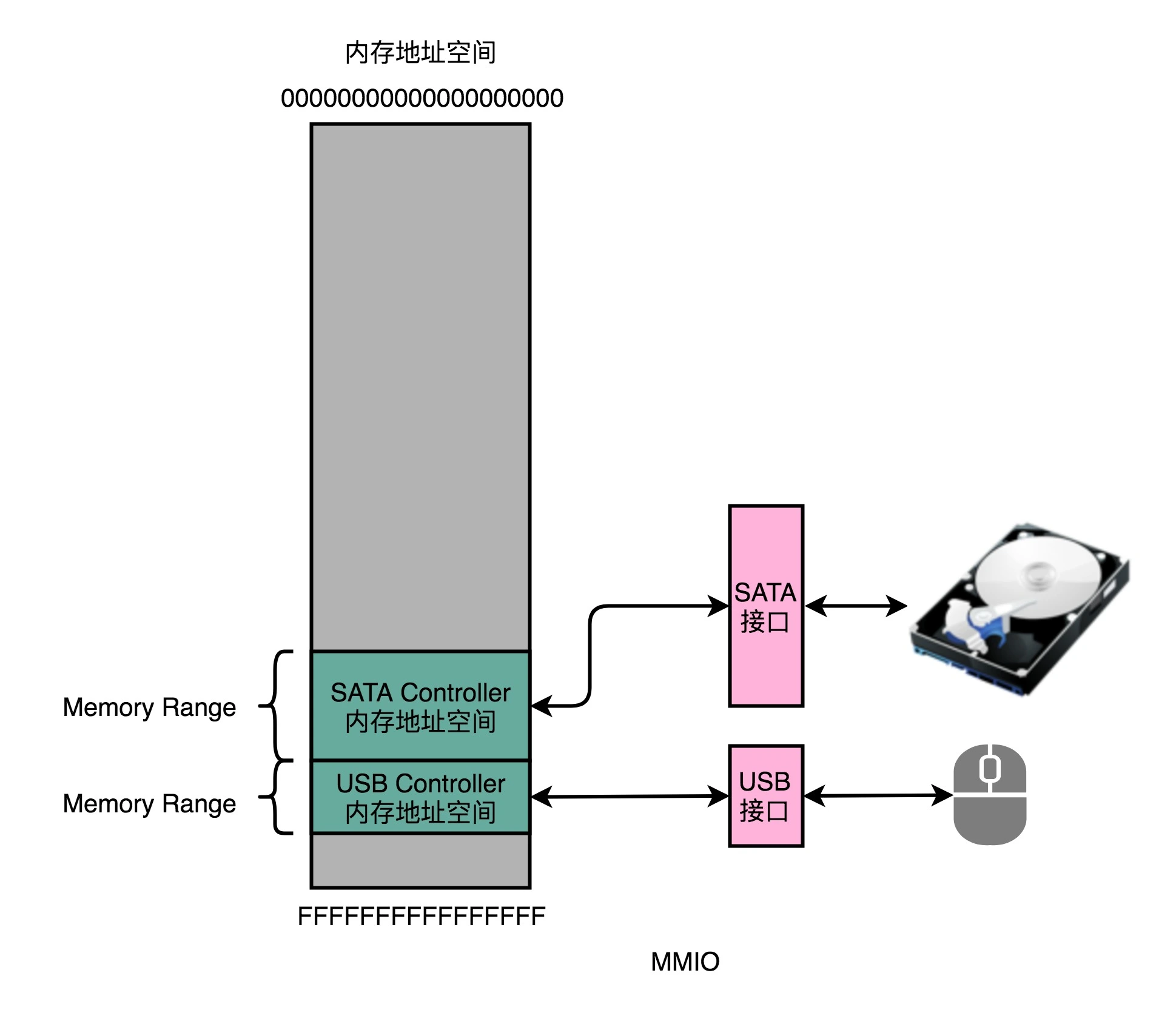
Intel CPU 虽然也支持 MMIO,但有 2000 多个指令的 Intel X86 架构,自然可以设计专门的和 I/O 设备通信的指令(in 和 out 指令)来支持端口映射 I/O(Port-Mapped I/O,简称 PMIO)或者叫独立输入输出(Isolated I/O)。
其实 PMIO 的通信方式和 MMIO 差不多,核心的区别在于,PMIO 里面访问的设备地址,不再是在内存地址空间里面,而是一个专门的端口(Port)。这个端口并不是指一个硬件上的插口,而是和 CPU 通信的一个抽象概念。
无论是 PMIO 还是 MMIO,CPU 都会传送一条二进制的数据,给到 I/O 设备的对应地址。设备自己本身的接口电路,再去解码这个数据。解码之后的数据呢,就会变成设备支持的一条指令,再去通过控制电路去操作实际的硬件设备。对于 CPU 来说,它并不需要关心设备本身能够支持哪些操作。它要做的,只是在总线上传输一条条数据就好了。
下图是我电脑的显卡在设备管理器中的资源信息:
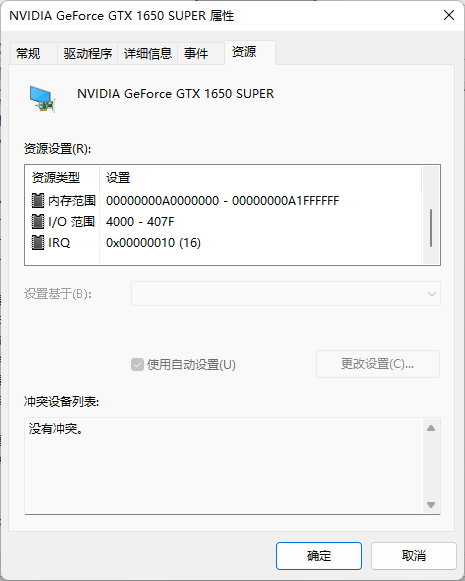
可以看到,里面既有 Memory Range,这个就是设备对应映射到的内存地址,也就是我们上面所说的 MMIO 的访问方式。同样的,里面还有 I/O Range,这个就是我们上面所说的 PMIO,也就是通过端口来访问 I/O 设备的地址。最后,里面还有一个 IRQ,也就是会来自于这个设备的中断信号。
硬盘
HDD(Hard Disk Drive,机械硬盘)
SSD(Solid-state drive 或 Solid-state disk,固态硬盘)
主要的性能指标:
-
响应时间(Response Time):即程序发起一个硬盘的读取/写入请求,直到这个请求返回的时间。
-
数据传输率(Data Transfer Rate):单位时间内传输数据的大小,除硬盘本身的影响外(SSD优于HDD),还受接口的带宽限制,例如SATA3.0带宽为6Gbps,而PCI Express 3.0 x16的带宽为8Gps * 16 = 128Gps;
-
IOPS(Input/output operations per second):每秒输入输出操作次数。在随机读写情况下,SSD的IOPS大概在万次数量级,而HDD的IOPS只有百次数量级。
在顺序读写和随机读写的情况下,硬盘的性能是完全不同的。随机读写的数据传输率是顺序读写情况下的几十分之一。且在随机读取下,接口带宽将不再是硬盘访问速度的瓶颈,SATA 3.0 和 PCIE接口的性能差异将会变小。
参考
[1] 深入浅出计算机组成原理
 wechat
wechat alipay
alipay
![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)