PyTorch源码解读 [1]: 编译源码
前言
为了更好的理解,阅读和调试PyTorch后端的C++源码实现,需要从源码开始编译PyTorch。
参考文档:PyTorch官方github的安装指引
Windows编译(已放弃)
已有环境如下:
操作系统:windows11
conda 4.9.2
python3.8
VS studio 2019 16.11.3
CUDA 10.2
cudnn 8.1.1.33
ninja 1.10.2
准备工作
新建conda环境
conda info -e |
安装依赖
激活conda环境,注意不要用PowerShell,不支持Conda虚拟环境。
conda activate PyTorchCompile |
拉取源码仓库
git clone --recursive https://github.com/pytorch/pytorch |
clone中如遇到网络问题,可以尝试使用边车加速工具。即便如此,可能还是有些submodule会clone失败。比如使用Google Git仓库的linux-syscall-support仓库。这里可以尝试修改.gitmodule中的url,用github上的仓库去替换。替换后再次同步并更新。
git submodule sync |
下载安装magma、mkl、sccache
这里准备利用pytorch工程目录下installation-helpers中的脚本进行下载
cd .\.jenkins\pytorch\win-test-helpers\installation-helpers\ |
执行脚本后会在磁盘根目录得到一个压缩包magma_2.5.4_cuda102_debug.7z,将其拷贝并解压到一个位置,如D:\software\magma_2.5.4_cuda102_debug,该目录下有include和lib,后面会用到。
.\install_mkl.bat |
会在根目录下得到mkl.7z,将其拷贝并解压缩。
.\install_sccache.bat |
会在根目录下得到一个bin文件夹,里面有sccache.exe和sccache-cl.exe,可以新建D:\software\sccache文件夹,并将bin移动过去。
配置环境
在源码根目录下新建一个env_set.bat文件,用于设置编译前的各种环境变量,内容如下:
:: Set the environment variables after you have downloaded and upzipped the mkl package, |
主要参考的是官方README和这篇博客中的内容,其中主要包括:
-
设置了
mkl,magma,sccache的路径 -
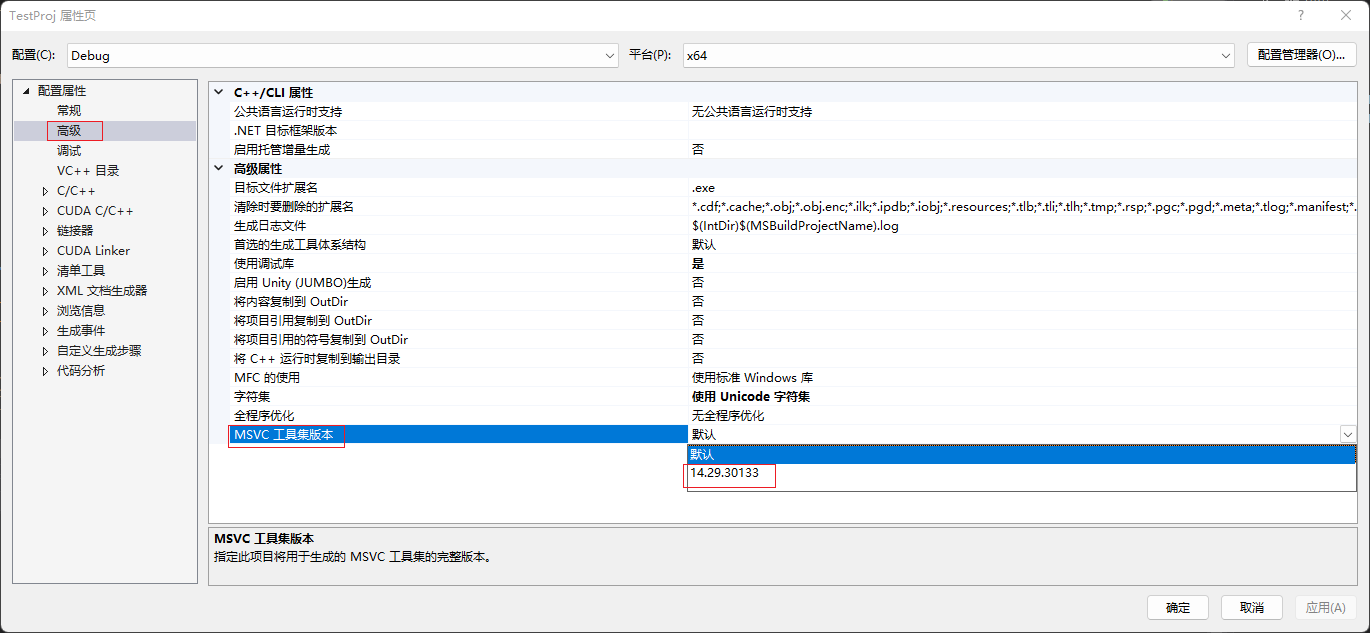
MSVC工具集的版本,不清楚自己VS对应的版本,可以用everything搜索
cl.exe(可能会搜到很多,注意根据自己VS安装的位置去甄别),可以看到D:\software\Microsoft Visual Studio\2019\Professional\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64\cl.exe,其中14.29.30133便是,或者随便打开一个VS工程,查看属性->高级->MSVC工具集版本,如下图:
- 指定使用CUDA,并指定算力,这里我的显卡是Geforce GTX 1650 SUPER,算是20系的阉割版吧。在官网查不到算力,有老哥说是7.5,跟20系保持一致,我信了。
- 复写CUDA host端的编译器为上述搜到的
cl.exe。 - 最后用
vcvarsall.bat来配置一些我们不需要关心的编译器指定操作,老哥说是必须放在最后一行(虽然官方示例中并不是),但我信了。
开始编译
# in cmd |
同上,必须在cmd下执行上述命令,powershell不支持conda虚拟环境。然后就是漫长的等待。
几乎是必然的,编译出错了,报ninja: build stopped: subcommand failed.(其实往上翻多一些,会看到报错的具体信息的)。有老哥说是pytorch的版本过高,ninja版本跟不上,导致编译不了。那就不编master,编个早期release版本总行吧
python setup.py clean |
编译该版本依旧会出错,可能是多进程编译的缘故,出错后,依旧会打印很多正常log才会停,这次我往上翻了好久,才看到具体的Error信息,大致为(magma.lib) error LNK2038: mismatch detected for '_ITERATOR_DEBUG_LEVEL': value '0' doesn't match value '2'这样的。怀疑magma是debug版本,但pytorch却编的是release版本导致的(其实我就是想编debug版本),于是在上面的env_set.bat中添加一行set DEBUG=1,然后重新编译:
python setup.py clean |
还是出错:
FAILED: caffe2/CMakeFiles/torch_cuda.dir/operators/torch_cuda_generated_spatial_batch_norm_op.cu.obj E:/code/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/operators/torch_cuda_generated_spatial_batch_norm_op.cu.obj
cmd.exe /C “cd /D E:\code\pytorch\build\caffe2\CMakeFiles\torch_cuda.dir\operators && D:\software\anaconda3\envs\PyTorchCompile\Library\bin\cmake.exe -E make_directory E:/code/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/operators/. && D:\software\anaconda3\envs\PyTorchCompile\Library\bin\cmake.exe -D verbose:BOOL=OFF -D build_configuration:STRING=Debug -D generated_file:STRING=E:/code/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/operators/./torch_cuda_generated_spatial_batch_norm_op.cu.obj -D generated_cubin_file:STRING=E:/code/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/operators/./torch_cuda_generated_spatial_batch_norm_op.cu.obj.cubin.txt -P E:/code/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/operators/torch_cuda_generated_spatial_batch_norm_op.cu.obj.Debug.cmake”
spatial_batch_norm_op.cu
spatial_batch_norm_op.cu
E:\code\pytorch\third_party\protobuf\src\google/protobuf/stubs/callback.h(236): error C2065: “UnknownType”: 未声明的标识符
E:\code\pytorch\third_party\protobuf\src\google/protobuf/stubs/callback.h(256): note: 查看对正在编译的 类 模板 实例化“google::protobuf::internal::MethodClosure2<Class,Arg1,Arg2>”的引用
CMake Error at torch_cuda_generated_spatial_batch_norm_op.cu.obj.Debug.cmake:281 (message):
Error generating file
E:/code/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/operators/./torch_cuda_generated_spatial_batch_norm_op.cu.obj
并没有找到相关信息,且这时我的耐心已经耗光了。还是编译不包含cuda的版本(本来的目的也是看CPU的后端实现),将env_set.bat中set USE_CUDA=1改为set USE_CUDA=0,然后重新编译:
python setup.py clean |
又报错(焯!):
LINK : fatal error LNK1104: 无法打开文件“python38_d.lib”
这需要安装python debug 版本,我没找到在conda环境下安装python debug的方法,只好将本地的python重装,并选择安装debug 版本库,如下:
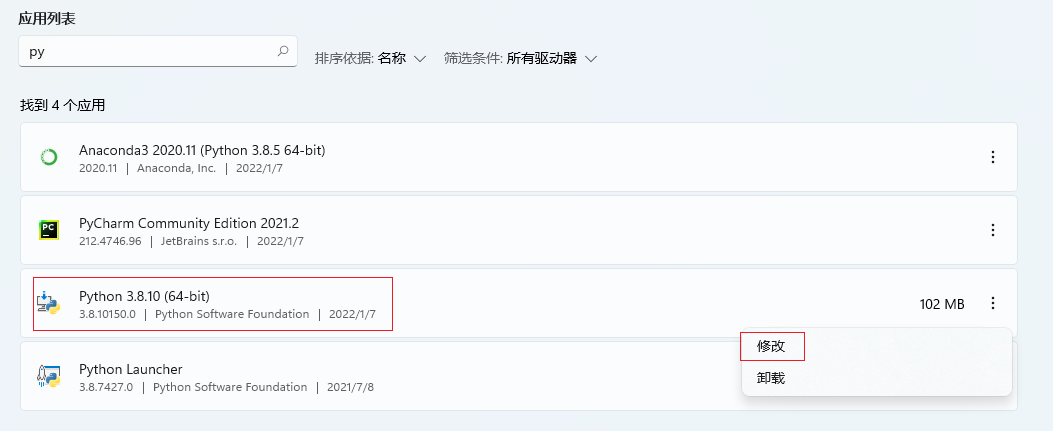
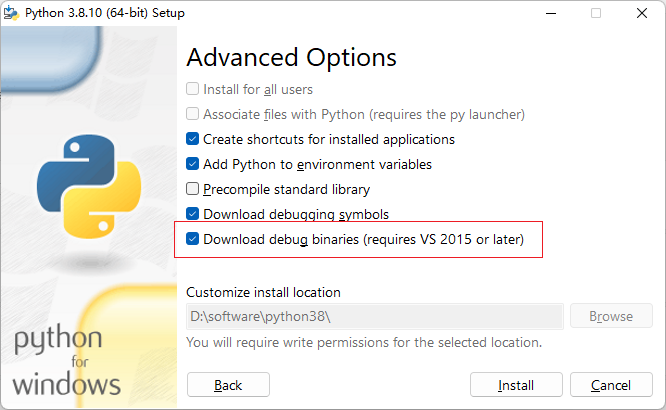
然后将本地python38目录下的python38_d.lib文件拷贝到conda 虚拟环境下的对应目录中(这里小版本不一致,本地是3.8.10,conda环境下是3.8.13,希望不会有事)。
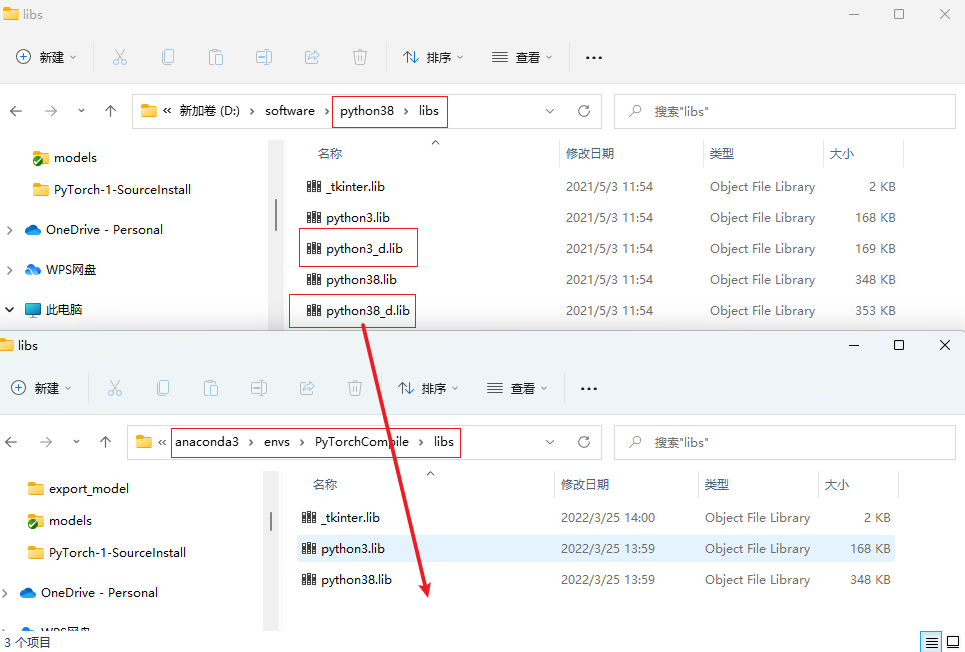
然后重新编译:
python setup.py clean |
然后又报错如下:
LINK : fatal error LNK1104: 无法打开文件“python38.lib”
血压下不来了,放弃!转到linux上编吧。
Linux编译
windows编译碰壁后,转而考虑在linux服务器上进行编译(真香),然后用vscode远程连接进行调试。
准备工作
新建conda环境
conda info -e |
安装依赖
激活conda环境
conda activate PyTorchCompile |
拉取源码仓库
git clone -b v1.10.2-rc1 --recursive https://github.com/pytorch/pytorch |
clone中如遇到网络问题,可以尝试使用边车加速工具。即便如此,可能还是有些submodule会clone失败。比如使用Google Git仓库的linux-syscall-support仓库。这里可以尝试修改.gitmodule中的url,用github上的仓库去替换。替换后再次同步并更新。
git submodule sync |
开始编译
conda activate PyTorchCompile # 切到对应的conda环境下 |
不出意外一路畅通无阻,如果想要torchvision,可以在编译前安装,因为安装torchvision会捆绑安装对应版本的torch。若已经完成了编译(编译会默认执行install操作),可以将捆绑安装的torch卸载,然后再次编译即可。
pip install torchvision |
pip list可以看到安装的情况:
Package Version Editable project location
torch 1.10.0a0+git71f889c /media/sde/aaron-wu/pytorch
简单测试编译安装是否成功:
import torch |
发现torchvision不能用,应该是与torch本身不兼容,查一下torch-1.10.2对应的torchvision版本应该是0.11.3,那就重新安装(为了与编译torch对应,也安装cpu版本):
pip uninstall torchvision |
在import torchvision时会报一个Warning,暂时不清楚影响:
/
/.conda/envs/PyTorchCompile/lib/python3.8/site-packages/torchvision/io/image.py:11: UserWarning: Failed to load image Python extension: / /.conda/envs/PyTorchCompile/lib/python3.8/site-packages/torchvision/image.so: undefined symbol: _ZN3c105ErrorC2ENS_14SourceLocationESs
warn(f"Failed to load image Python extension: {e}")
调试代码
配置launch.json
这里使用vscode远程连接到linux服务器进行调试,可以开两个窗口,一个窗口打开pytorch源码文件夹,一个窗口打开用于测试的python脚本文件夹,如下图:
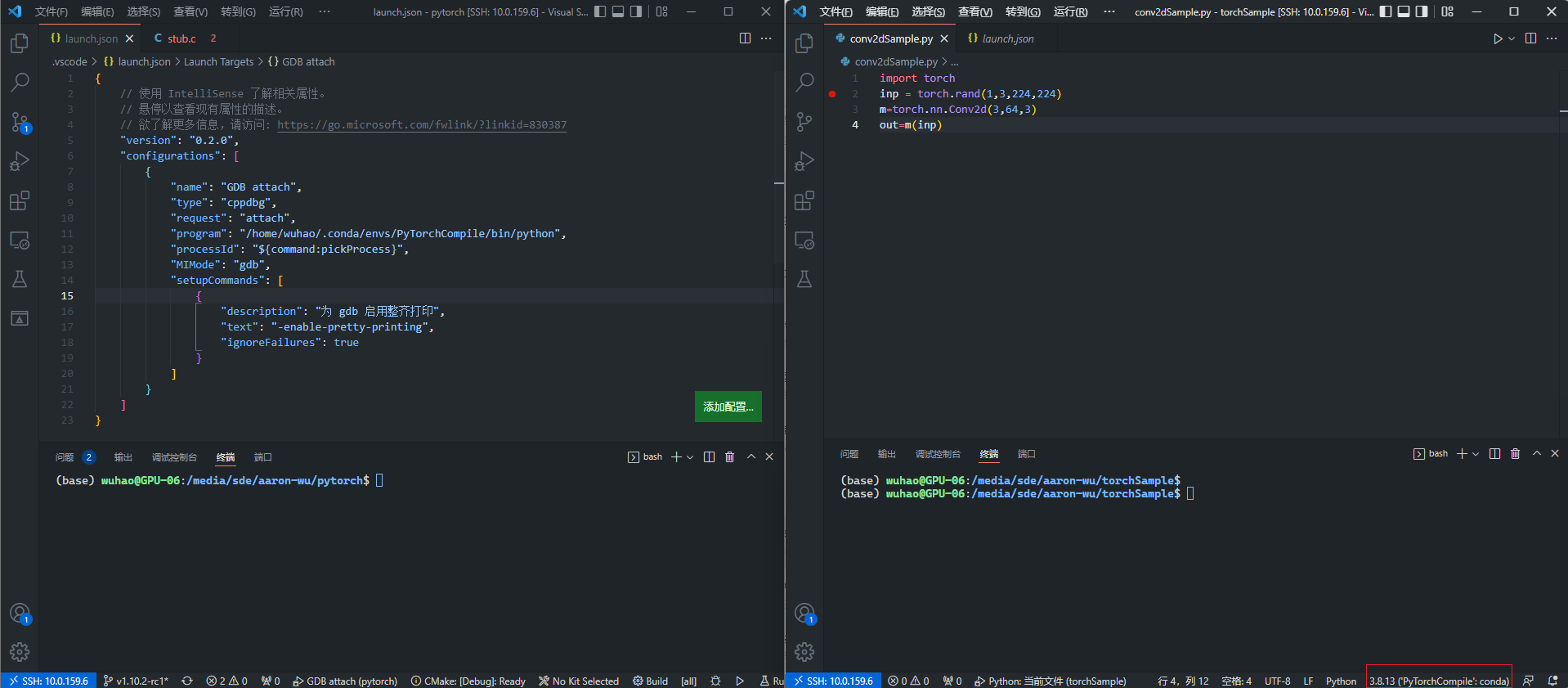
左侧为pytorch源码窗口,右侧python测试代码窗口,注意python窗口可以点击右下角的切换python解释器到我们conda虚拟环境对应的python版本。
为python测试代码配置launch.json文件,在默认生成的配置的基础上,增加"stopOnEntry": true让代码在启动后马上停止。如下:
{ |
为pytorch源码配置launch.json文件,用gdb attach抓取正在执行的python进程,从而能够在执行中在断点处停下。大致的原理可以看这里,摘了一段如下:
PyTorch的代码分为两部分:Python和C++代码。Python代码运行在Python解释器中,而C++代码是以二进制机器码在物理机中执行。不管哪一个,调试器的工作机制都是将执行代码中的代码替换成一个异常处理的代码,让程序的执行跳转到调试器中的处理流程去。我们在调试过程中使用的Breakpoint断点就是往指定的地方更换代码,在C++调试器GDB中更换的是二进制代码,在Python调试器中就是字节码。
我们调试的方式就是用Python调试器启动一个Python程序,此时Python解释器解释执行Python源码,然后到调用PyTorch库的时候,可能会进入PyTorch的部分。而Python的C/C++扩展的原理就是实现一个共享库,然Python解释器去调用。我们让C++调试器,也就是GDB,去attach到这个Python程序上,等它执行到PyTorch中的C++部分时可以在GDB断点暂停。
VS Code使用的Python调试器是微软自家的debugpy,它使用的是服务端/客户端模型,一共开了三个进程,分别为laucher、debugpy、adapter,在调试的时候使用GDB去attach其中的debugpy程序。
{ |
其中"program"为conda虚拟环境对应的python程序的路径,可以在conda环境中用which python查看。
运行程序
首先运行python测试代码,F5(或点击绿色三角按钮)后停在第一行。
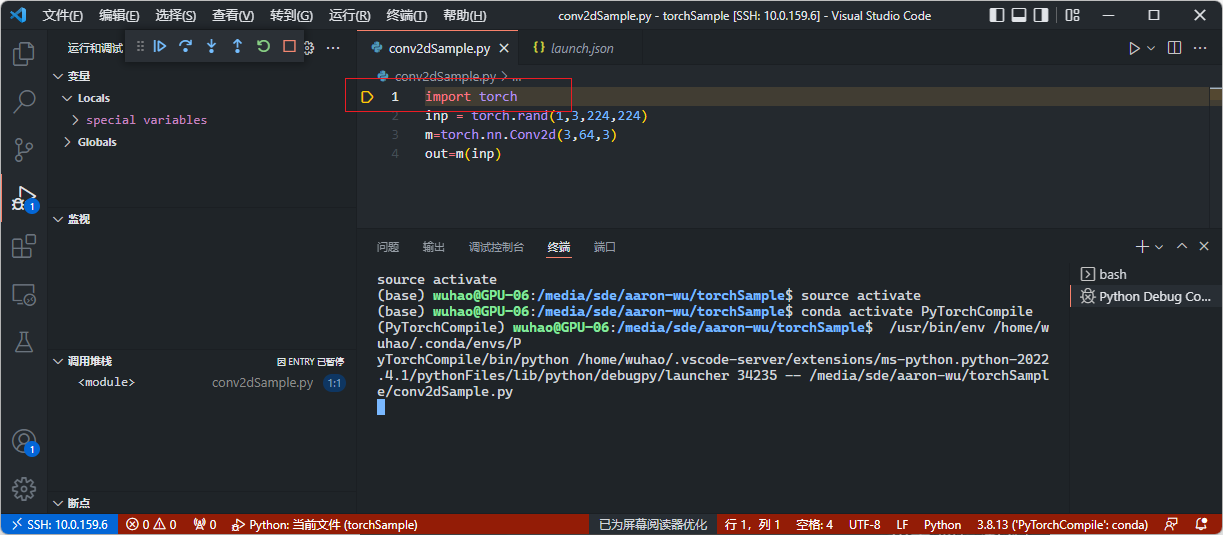
然后运行pytorch源码,F5(或点击绿色三角按钮)后会让你选择要attach的进程:
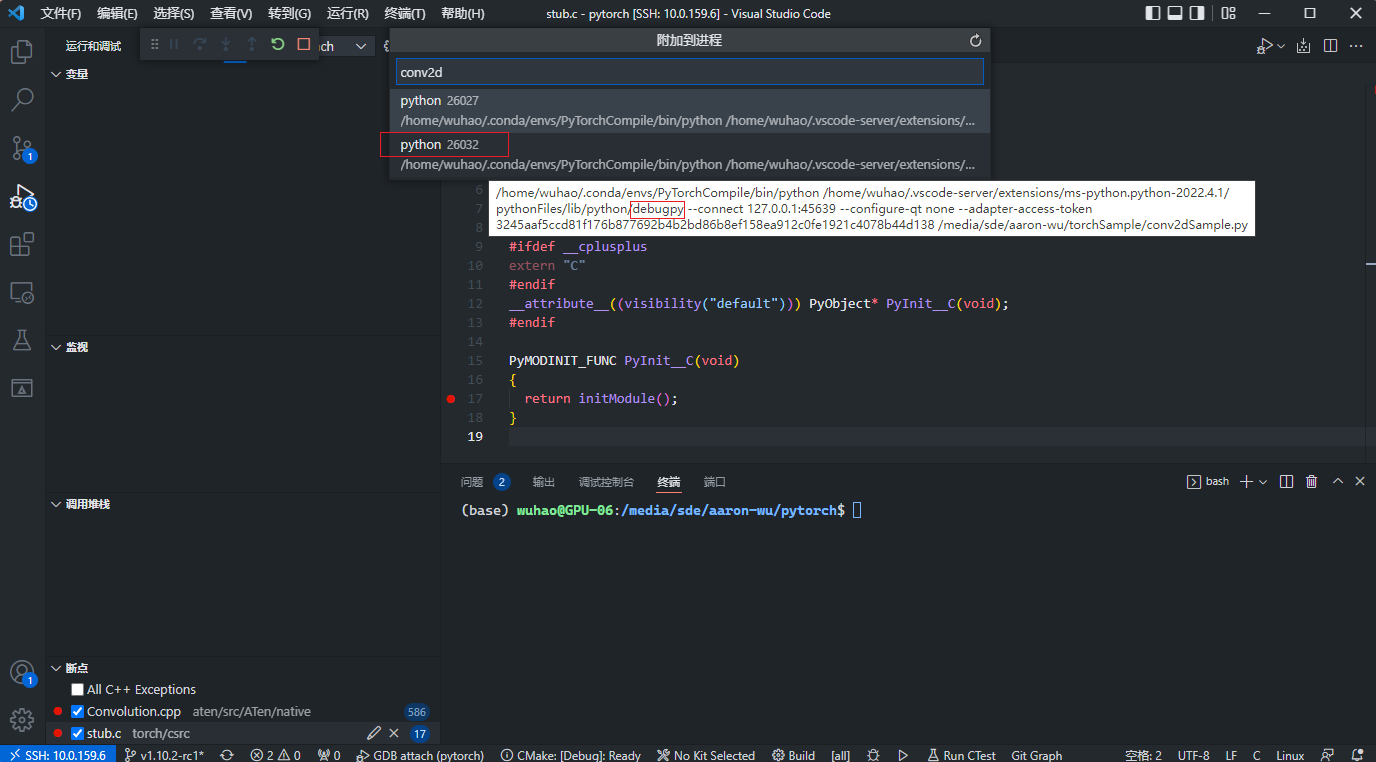
注意这里要选择第二个进程,即debugpy的进程。首次执行时,会遇到su权限问题:

输入y确认后,可能还会弹出类似如下内容:
Authentication is needed to run `/usr/bin/gdb’ as the super user
Multiple identities can be used for authentication:
aaa
bbb
ccc
Choose identity to authenticate as (1-3): [1] + Stopped (tty input) /usr/bin/pkexec “/usr/bin/gdb” --interpreter=mi --tty=${DbgTerm} 0<“/tmp/Microsoft-MIEngine-In-b025qijj.kuu” 1>“/tmp/Microsoft-MIEngine-Out-d0w13ryp.5p1”
You have stopped jobs.
按照这里的解决方法,执行sudo sysctl -w kernel.yama.ptrace_scope=0即可解决。
正常attach后的窗口界面如下图所示:
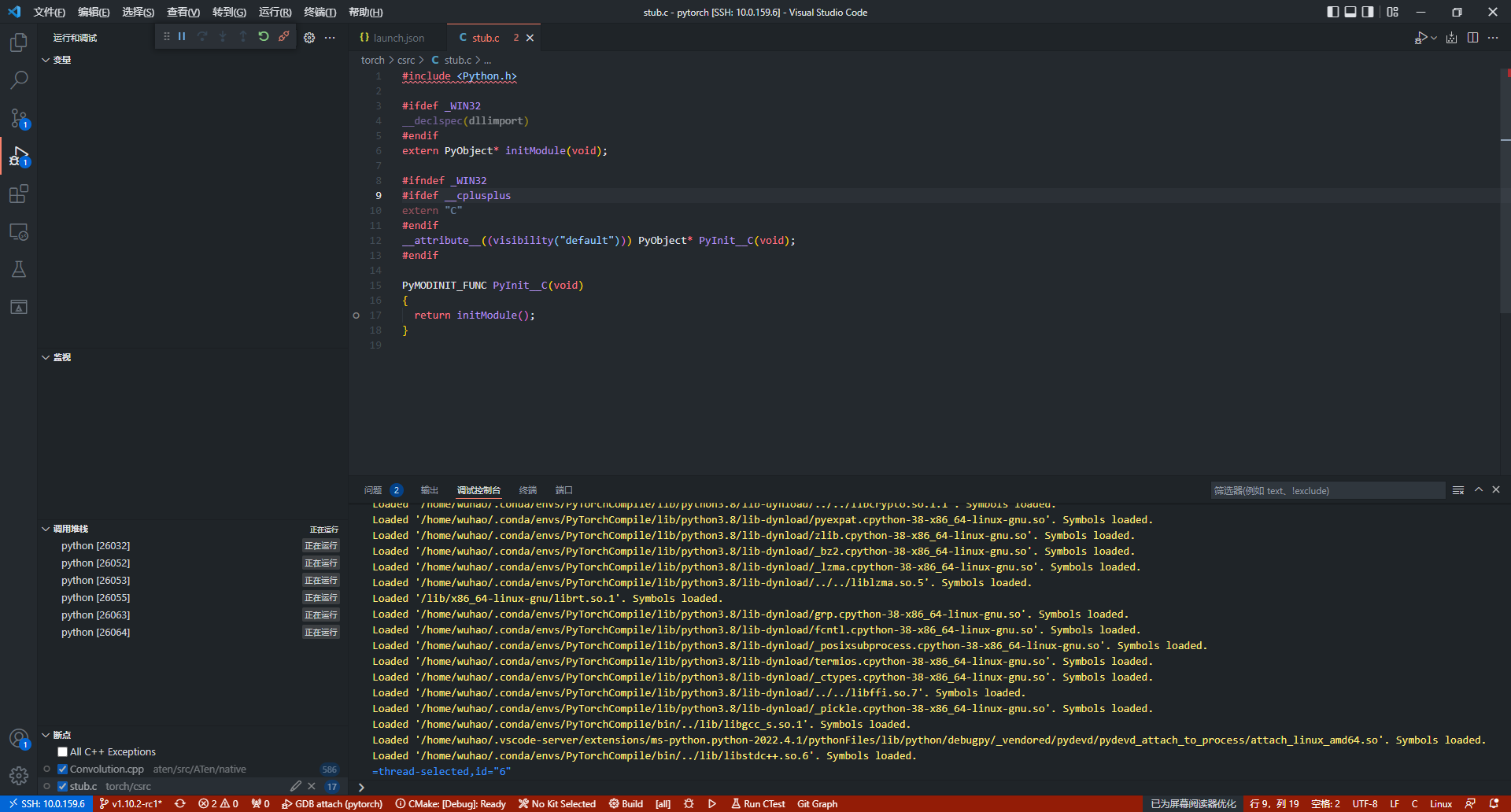
这里在stub.c中的PyInit_C函数(import torch时模块初始化)中打上断点,然后F5继续执行python测试代码,等待一段时间后(可能会比较久,GDB在加载共享库的符号),程序将在断点处停下,Pytorch的执行已经从python前端进入到了c++后端。
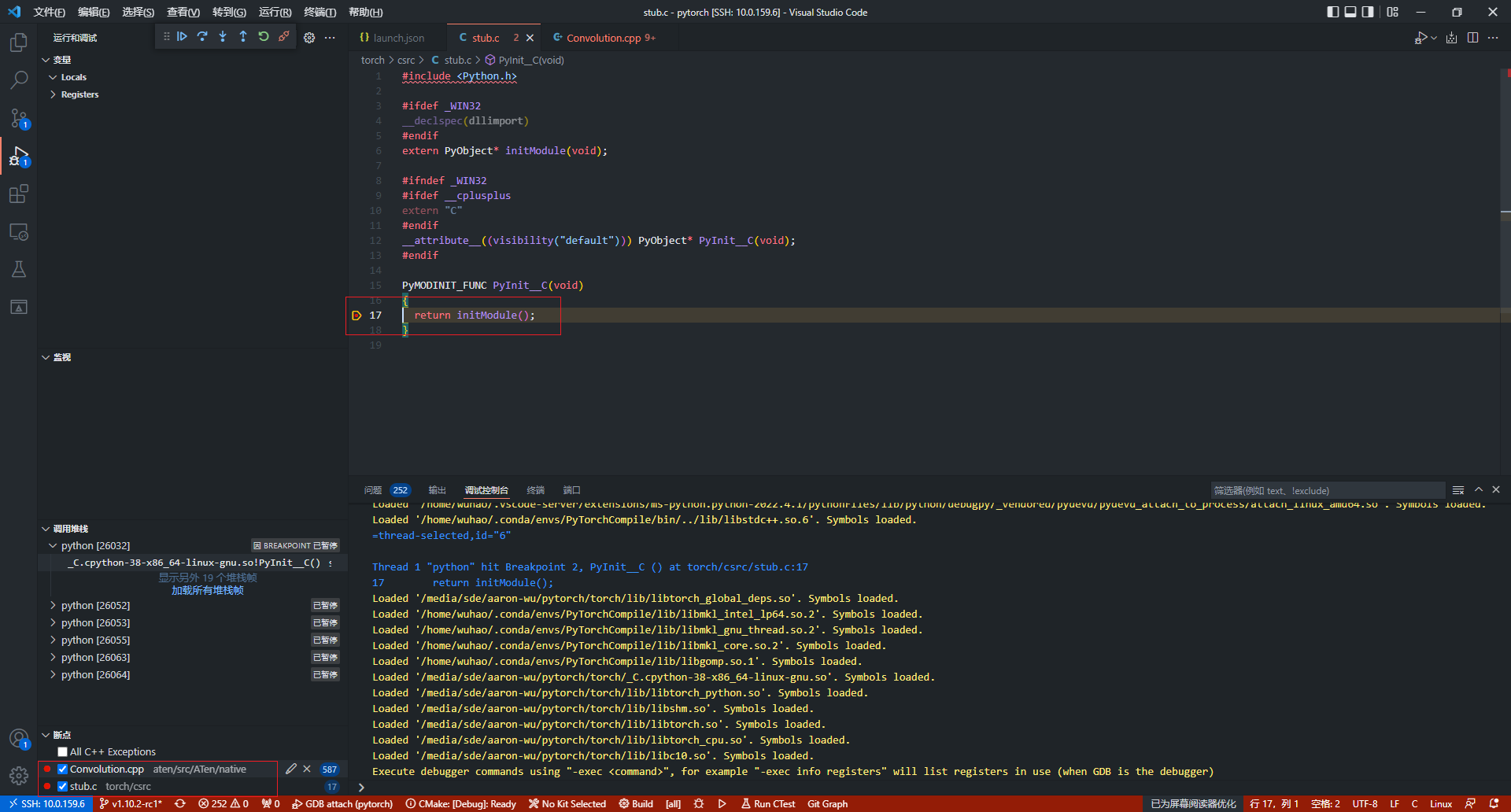
这时打上的断点也从灰变红,说明断点被成功绑定到了代码中,接下来就可以单步调试并理解Pytorch的源码了。
docker编译(未完)
准备工作
尝试在windows下用docker环境中linux编译,首先新建docker 容器:
docker container run -itd --name torchCompile ubuntu:18.04 |
docker下安装conda
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-Linux-x86_64.sh |
参考
[1] 编译、调试PyTorch源码
 wechat
wechat alipay
alipay
![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)