SIMD[1]: NEON入门
简介
ARM CPU 最初只有普通的寄存器,可以进行基本数据类型的基础运算。从 ARMv5 架构开始引入 VFP(vector-floating-point) 指令扩展,可以通过使用短向量指令来加速浮点计算。从 ARMv7 架构开始引入 NEON 技术,NEON 技术同样是依靠向量指令来加速计算。鉴于 NEON 技术提供的向量技术加速效果体验更优秀,从 ARMv7 架构开始 VFP 向量指令加速的模式被弃用,因此 VFP 单元有时也称之为 FPU(Floating Point Unit)单元。
ARM NEON 技术本质上是一种高级的**单指令多数据(SIMD)**架构扩展,这种扩展仅在一些 ARMv7-A 和 ARMv7-R 架构以及 ARMv8 架构上支持。
这里将先以ARMv8中的NEON展开介绍,后续文章再讨论ARMv7和ARMv8的差异。
ARMv8 NEON
ARMv8-A包括32位和64位执行状态,每一种都有自己的指令集:
- AArch64是用来描述ARMv8-A架构64位执行状态的名称。在AArch64状态下,处理器执行A64指令集,其中包含NEON指令(也称为SIMD指令)。GNU和Linux文档有时将AArch64称为ARM64。
- AArch32描述了ARMv8-A架构的32位执行状态,它几乎与ARMv7相同。在AArch32状态下,处理器可以执A32(在该架构的早期版本中称为ARM)或T32 (Thumb)指令集。A32和T32指令集与Armv7向后兼容,包括NEON指令。
ARMv8 NEON 寄存器
NEON寄存器文件是一组**寄存器(Register)**的集合(ARMv8 有32个128bit寄存器),可以作为8位、16位、32位、64位和128位寄存器进行访问。
NEON寄存器包含相同数据类型的元素向量(Vector)。在输入和输出寄存器中相同的元素位置被称为一个通道(lane)。
通常每个NEON指令会导致n个并行操作,其中n是输入向量被划分的通道数。每个操作都包含在通道内。从一个通道到另一个通道不会产生进位或溢出。
矢量中的通道数取决于矢量的大小和矢量中的数据元素(element)的类型。
一个128位的NEON矢量可以包含以下元素大小:
- 16个8位元素(操作数后缀为
.16B,其中B表示字节) - 8个16位元素(操作数后缀
.8H,其中H表示半字) - 4个32位元素(操作数后缀
.4S,其中S表示单字) - 2个64位元素(操作数后缀
.2D,其中D表示双字)
一个64位的NEON向量可以包含以下元素大小(128位寄存器的高64位未使用):
- 8个8位元素(操作数后缀
.8B,其中B表示字节) - 4个16位元素(操作数后缀
.4H,其中H表示半字) - 2个32位元素(操作数后缀
.2S,其中S表示单字) - 1个64位元素(操作数后缀
.1D,其中D表示双字)
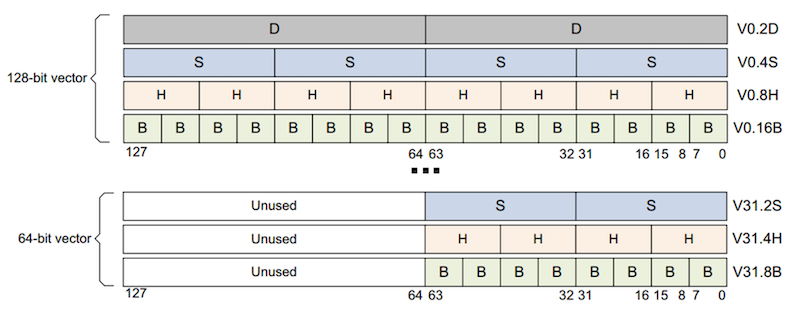
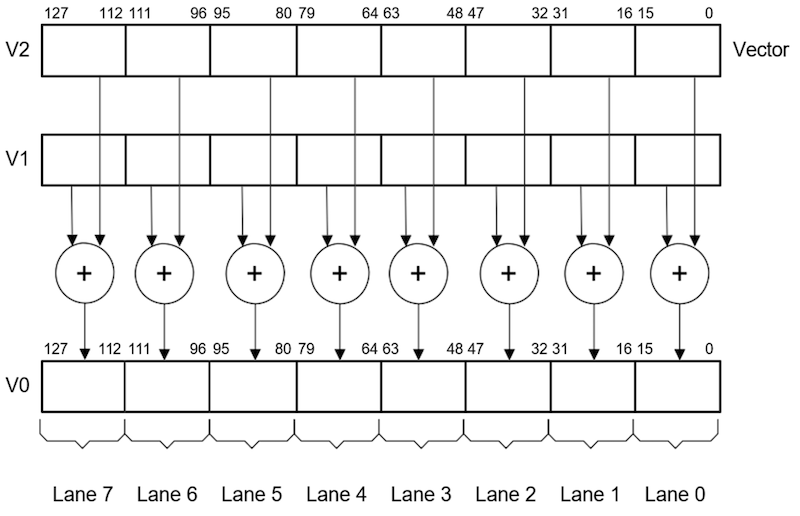
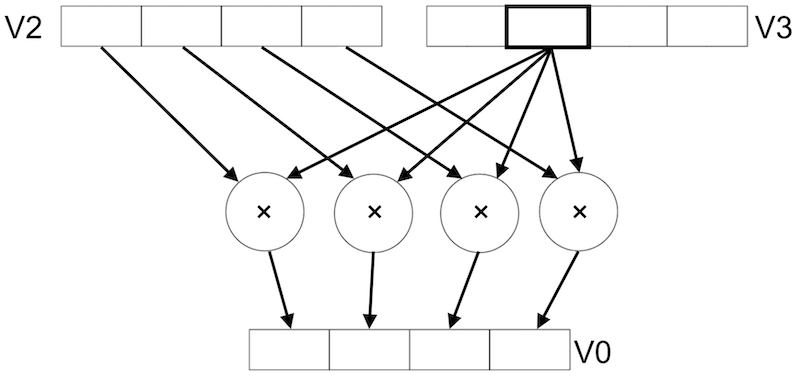
向量中的元素按最低有效位排序。也就是说,元素0使用寄存器的最低有效位。如下是两个向量运算的示例:
ADD V0.8H, V1.8H, V2.8H |
MUL V0.4S, V2.4S, V3.S[2] |
ARMv8 NEON 调用方式
想要使用NEON指令加速代码,可以通过如下几种方式:
- 导入一个使用了NEON的库:如Ne10,Libyuv,Skia,OpenMax DL等;
- 使用支持生成NEON代码的编译器:如the Arm Compilers GCC,在GCC选项中加入向量化表示能有助于C代码生成NEON代码,如
-ftree-vectorize; - 使用 NEON intrinsics:NEON指令的高级封装,类似调用C语言函数的方法调用NEON指令,并由编译器生成最终的二进制代码;
- 手撸 NEON 汇编:内联汇编或汇编文件,直接生成二级制代码;
参考
 wechat
wechat alipay
alipay




![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)