SIMD[3]: NEON 内联汇编
前言
汇编作为代码的最底层实现,大概的流程就是加载数据到寄存器,计算,把寄存器的值写回内存。
一般运行瓶颈就在于数据的加载和写出还有指令之间的数据依赖等等,所以怎么更高效的读写数据还有使相邻指令之间的数据依赖最小等等,是做优化经常都会遇到的问题,当然这个很吃经验,但是也总是会有一些套路可寻。
ARMv7与ARMv8对比
寄存器
通用寄存器
ARMv7(或 ARMv8 的AArch32执行状态) 有 16 个 32-bit 通用寄存器,用 R0-R15 表示。
ARMv8(默认指AArch64执行状态) 有 31 个 64-bit 通用寄存器,用 X0-X30 表示。还有一个不同名称(取决于使用它的上下文)的特殊寄存器。和ARMv7不一样的是,这31个寄存器也可以作为 32-bit 寄存器来用,用 W0-W30 表示,其中 Wn 是 Xn 的低32位。
向量寄存器
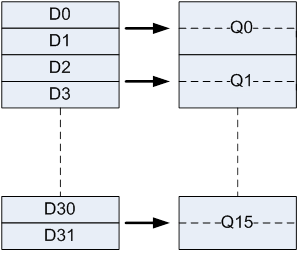
ARMv7 包含 16 个 128-bit 向量寄存器,用 Q0-Q15 表示,其中每个Q寄存器又可以拆分成两个 64-bit 向量寄存器来用,用 D0-D31 来表示,对应关系如下图:
ARMv8(AArch64)具有32 x 128位向量寄存器,用V0-V31表示。用法参见NEON入门。每个V寄存器也可以只使用其低若干位,只使用低64-bit的叫做D(双字)寄存器,只使用低32位的叫做S(单字)寄存器,只使用低16位的叫做H(半字)寄存器。对应关系如下图:

指令格式
ARMv7/AArch32指令语法
ARMv7-A/AArch32 NEON 指令(与 VFP 一样)的所有助记符都以字母V开头。 指令通常能够对不同的数据类型进行操作,这在指令编码中指定。 尺寸用指令的后缀表示。 元素的数量由指定的寄存器大小和操作的数据类型指示。 指令具有以下一般格式:
V{<mod>}<op>{<shape>}{<cond>}{.<dt>}{<dest>}, src1, src2 |
其中:
-
{}表示可选参数 -
<mod>- 意为modifilers,有如下几种取值:Q:指令采用饱和算法,使结果在指定数据类型范围内饱和,如VQABS、VQSHL等;H:指令将结果减半。 它通过右移一位(实际上是除2并截断)来实现,例如VHADD、VHSUB;D:指令将结果加倍,如VQDMULL、VQDMLAL、VQDMLSL和VQ{R}DMULH;R:指令会对结果进行四舍五入,相当于在截断前给结果加0.5,如VRHADD、VRSHR。
-
<op>- 操作名,例如加ADD,减SUB,乘MUL; -
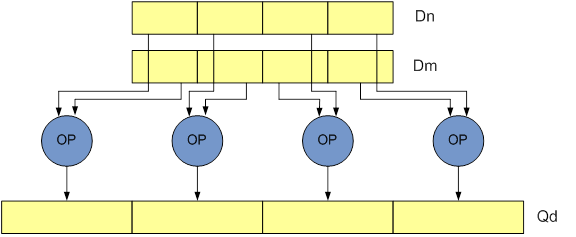
<shape>- 尺寸Long(L):指令对双字向量操作数进行运算并产生四字向量结果。 结果元素是操作数宽度的两倍。加长(lengthening)指令在指令后附加一个 L;
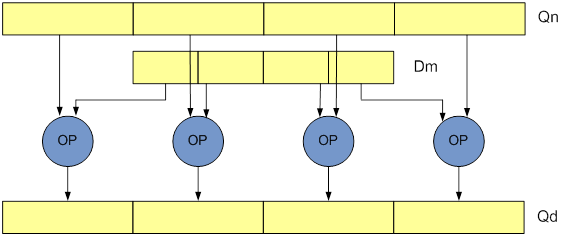
Wide(W):指令对双字向量操作数和四字向量操作数进行运算,产生四字向量结果。 结果和第一个操作数的元素是第二个操作数元素宽度的两倍。加宽(widening)指令在指令后附加了一个W;
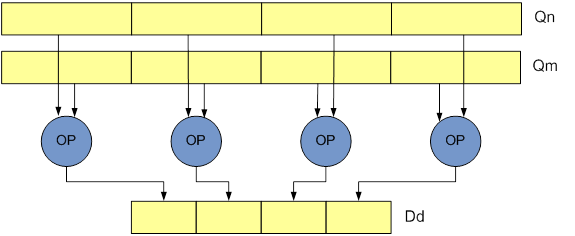
Narrow(N):指令对四字向量操作数进行操作,产生双字向量结果。结果元素是操作数元素宽度的一半。窄化(narrowing)指令是再指令后附加一个N;
-
<cond>- 条件,与 IT 指令一起使用; -
<.dt>- 数据类型,例如 s8、u8、f32 等; -
<dest>- 目标; -
<src1>- 源操作数 1; -
<src2>- 源操作数 2;
AArch64指令语法
{<prefix>}<op>{<suffix>} Vd.<T>, Vn.<T>, Vm.<T> |
其中:
-
<prefix>- 前缀,如使用S/U/F/P来表示有符号/无符号/浮点/布尔数据类型; -
<op>- 操作名,例如ADD、AND等; -
<suffix>- 后缀P:将向量按对操作,例如ADDP;V:跨所有的数据通道操作,例如FMAXV;2:在宽(widening)指令/窄(narrowing)指令中操作数据的高位部分。例如ADDHN2,SADDL2;
-
<T>- 数据类型,通常是8B/16B/4H/8H/2S/4S/2D等。B(字节)代表8位数据类型;H(半字)代表16位数据宽度;S(单字)代表32位数据宽度,可以是32位整数或单精度浮点;D(双字)代表64位数据宽度,可以是64位整数或双精度浮点。
内联汇编的一般格式
asm qualifiers ( |
更为具体的解释可以参见这篇文档,这里简要说明如下:
asm:也可写作__asm__qualifiers:一般用volatile修饰词,实际没有作用,整个汇编块都是隐式的volatile;OutputOperands:在内联汇编中会被修改的变量列表,变量之间用逗号隔开,每个变量的格式是:[asmSymbolicName] "constraint"(cvariablename)cvariablename:表示变量原来的名字;asmSymbolicName:表示变量在内联汇编代码中的别名,一般和cvariablename一样,在汇编代码中就可以通过%[asmSymbolicName]去使用该变量,asmSymbolicName可以省略,此时可以通%0,%1等去使用变量;constraint:用于定义变量的存放位置,一般填=r,具体如下:r表示使用任何可用的寄存器w表示浮点寄存器m表示使用变量的内存地址+可读可写=只写&表示该输出操作数不能使用输入部分使用过的寄存器,只能用+&或=&的方式使用
InputOperands:在内联汇编中用到的输入变量列表,变量之间用逗号隔开,每个变量的格式是:[asmSymbolicName] "constraint"(cexpression)。和输出不一样地方是,首先要按OutputOperands列表的顺序再列一遍,但是constraint用数字代替从0开始(个人理解,再列一遍的原因输出变量列表中将其约束为只写=,若输出变量真的是只写,这里其实不用再列一遍)。然后才是写其他只读变量(输入变量),只读变量constraint填r等。同样asmSymbolicName可以省略,此时可以通%0,%1等去使用变量,按声明顺序,输出变量在前,只读变量在后(注意InputOperands的序号会接着OutputOperands的序号递增,如下);
asm qualifiers ( |
Clobbers:一般是"cc","memory"开头,然后接着填内联汇编中用到的通用寄存器和向量寄存器:"cc"表示内联汇编代码修改了标志寄存器;"memory"表示汇编代码对输入和输出操作数执行内存读取或写入操作(读写参数列表之一的变量指向的内存);
常用汇编符号
[]:方括号表示取地址值,类似于C语言中*ptr,将括号内的值作为地址,获取该地址处的值;!:感叹号用于数据转移指令(LD,ST)中,用于自增/减或者预索引操作:
// 指令末尾的!表示,写完内容后地址会自增 |
//预索引:该指令先令R1=R1+20,把地址R1处的值加载到R0,即先根据寻址规则修改寄存器,然后根据寄存器中的值访问内存 |
%:%[xxx]使用名为xxx的变量;%0使用输出/输入列表中第0个变量;在ARMv8中,可以为变量加上约束,%w[xxx]或者%w0将使用变量的W寄存器(低32-bit),%x[xxx]或%x0将使用变量的X寄存器,与%[xxx]或%0一致;对于表示向量寄存器的也可以为其添加后缀,%0.4S将表示使用128-bit向量寄存器,并且其包含4个32-bit的数据元素。
常用汇编指令
预加载指令
数据预取通过将代码中后续可能使用到的数据提前加载到cache中,减少CPU等待数据从内存中加载的时间,提升cache命中率,进而提升软件的运行效率。预取指令格式通常如下:
PRFM prfop, [Xn|SP{, |
prfop由type<target><policy>三部分组成。
type可选模式如下:PLD:数据预加载;PLI:指令预取;PST:数据预存储;
<target>可选模式如下:L1、L2、L3,分别表示对三个不同的cache层级进行操作。<policy>可选模式如下:KEEP:数据预取使用后保存一定时间,适用于数据多次使用的场景;STRM:流式或非临时预取,数据使用后将淘汰,用于仅使用一次的数据;
Xn|SP通常表示64位通用寄存器或栈指针,使用场景中通常为预取的起始地址。
pimm是以字节为单位的偏移量,代表预取的字节长度,取值为8的整数倍,范围是0~32760,默认为0。预取长度可结合实际业务场景设定,尝试预取不同长度数据,获取最佳预取值。
参考
 wechat
wechat alipay
alipay




![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)