前言
非线性最小二乘法(NLS)是一种优化技术,可用于为包含非线性特征的数据集建立回归(回归即最佳拟合)模型。此类数据集的模型系数是非线性的。
NLS回归理论
在本文中将遵守如下的符号表示的惯例:
“帽子”符号用来表示在数据上拟合回归模型过程中生成的值,如 β^β^ 代表拟合系数的向量;
yobsyobs 代表因变量y的观察值向量;
未加粗表示标量,加粗表示向量或矩阵。如 yobsi 表示向量 yobsyobs 中第 i 个标量;
我们假设回归矩阵 X 的尺寸为 m×n,即它有 m 行 n 列 回归变量。y 矩阵的尺寸为 m×1,系数矩阵的尺寸为n×1 或者 1×n(转置形式)。
下面将看到3个可用MLS训练的非线性模型的例子:
例1
在下面这个模型中,回归系数 β1 和 β2 分别是2次幂和3次幂,所以模型的系数是非线性的:
yobs=β0^+β12^∗x1+β23^∗x2+e
其中,e表示模型残差,即观察值和预测值(β0^+β12^∗x1+β23^∗x2)之间的差值。
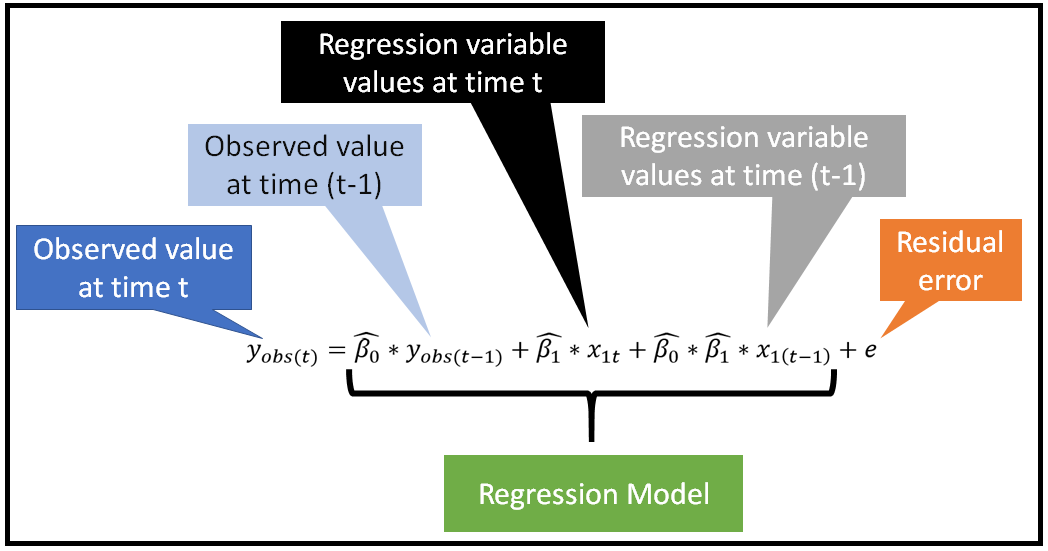
例2
下面这个模型是一个自回归时间序列模型,其中 β0 和 β1 是相乘的关系,所以本质上也是非线性的:
例3
在下面这个模型中,预测值是回归变量 x 的线性组合的指数函数:
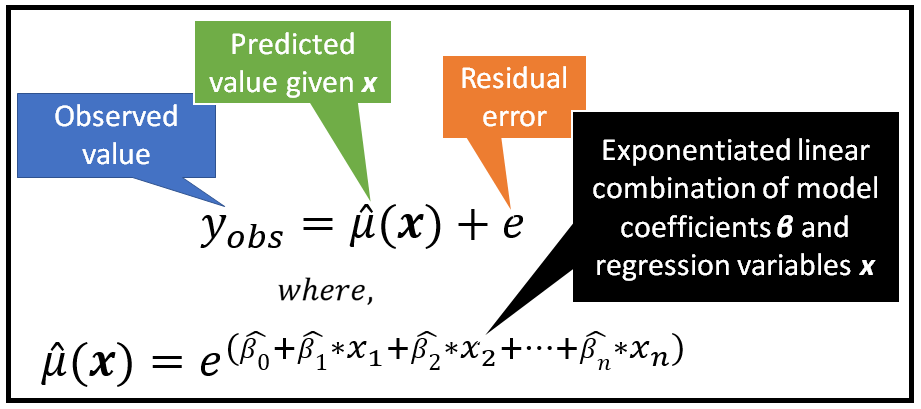
该公式常用于泊松回归模型或其衍化模型,如广义泊松模型或负二项式回归模型。具体来说,拟合均值μ_cap表示为泊松概率分布的条件平均值,如下所示:
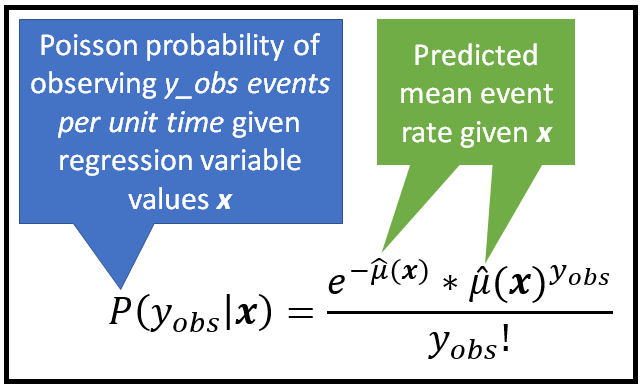
这种泊松回归模型用于拟合基于计数的数据集,如共享单车场景下,每天租用其中一辆自行车的人数。
NLS优化如何工作?
在NLS中,我的目标是寻找能最小化残差平方和(Residual Sum of Squares,RSS)的模型参数向量 ββ,换句话说,我们要减小:
RSS=i∑mri=i∑m(yobsi−μi^)2
其中,μi^是模型对数据集中第 i 行的预测,是模型参数向量 β^β^ 和回归变量 xixi 的函数,如下:
μ^(xixi)=f(β^β^,xixi)
将其替换进上述RSS等式中:
RSS=i∑mri=i∑m(yobsi−f(β^β^,xixi))2
最小化RSS的一种方法就是对 β^β^ 求微分,对微分为0进行求解,即:
∂β^j∂(RSS)=0∀j∈[1,n]
由于 β^β^ 是一个长度为 n 的向量,对应于 n 个回归变量 x1 ,x2 ,… ,xn,需要对每一个分量的偏微分为0进行求解,如下:
∂β^1∂(RSS)=0⟹∂β^1∂i∑m(yobsi−f(β^β^,xixi))2=0⟹−2i∑m(yobsi−f(β^β^,xixi))∗∂β^1∂f(β^β^,xixi)=0
因为有 n 个参数从 β^1 到 β^n,所以就得到了 n 个等式组成的方程组。但是,与普通最小二乘法(Ordinary Least Squares,OLS)估计不同,n 个方程组没有封闭形式的解。因此,需要使用迭代优化技术,在每次迭代中(迭代次数用 k 表示),对参数 β^1 到 β^n 做一个微小的调整,如下所示,并重新评估RSS。
β^jk=β^j(k−1)+δβ^j
目前有几种算法可以用来有效地更新 β^β^向量,直到更新到一组最佳的值,以使得RSS最小化。其中主要是基于信赖域(Trust Region)的方法,如信赖域反射(Trust Region Reflective)算法、Levenberg-Marquardt 算法和Dogbox 算法。SciPy支持这三种算法。
再来回看上面例3中的指数平均模型:
将其代入RSS等式有:
RSS=i∑m(yobsi−exixiβ^β^)2
其中,xixi的尺寸为 1×n,β^β^ 的尺寸为 n×1,两者的矩阵乘结果为 1×1矩阵,即为标量。
上述等式对 β^β^ 求微分,并令微分等于0,可以得到如下方程组(这里以向量形式表示),需要使用上述迭代优化算法之一进行求解:
i∑mxixi(yobsi−exixiβ^β^)∗exiβ^xiβ^=0
使用Python+SciPy实现NLS回归
数据准备
让我们使用非线性最小二乘法将**泊松回归(Poisson regression)**模型拟合到为期两年的自行车租赁日使用量数据集。在这里下载数据,数据的前10行如下:

回归模型
参考
[1] A Guide to Building Nonlinear Least Squares (NLS) Regression Models
 wechat
wechat alipay
alipay![现代硬件算法[8.8]: 时空局部性](/images/pd_09.webp)
![现代硬件算法[8.7]: 缓存遗忘算法](/images/pd_08.webp)
![现代硬件算法[8.6]: 淘汰策略](/images/pd_07.webp)
![现代硬件算法[8.5]: 列表排名](/images/pd_06.webp)
![现代硬件算法[8.4]: 外部排序](/images/pd_05.webp)