现代硬件算法[1.1]: 现代硬件
现代硬件
20世纪60年代的超级计算机的主要缺点并不是速度慢(相对而言),而是体积巨大、使用复杂,而且价格昂贵,以至于只有世界超级大国的政府才能负担得起。它们的尺寸是它们如此昂贵的原因:它们需要大量的定制组件,这些组件必须由持有电气工程高级学位的人在宏观世界中非常仔细地组装,而这一过程是无法大规模量产的。
转折点是芯片(microchips)(单个的、微小的、完整的电路)的出现和发展:它彻底改变了工业,可能称得上20世纪最重要的发明,没有之一。1965年的一个价值数百万美元的计算机柜,到了1975年可以装进一块4mm×4mm的硅片上,你可以花25美元买到它。在接下来的十年中,这种经济性的显著提高引发了家用电脑革命,Apple II、Atari 2600、Commodore 64和IBM PC等电脑开始走进寻常百姓家。
芯片是如何制造的
芯片是用一种叫做光刻的工艺将电路“印刷”在一片晶体硅上,这包括:
然后在几个月内执行另外40-50个步骤以完成芯片的其余部分。
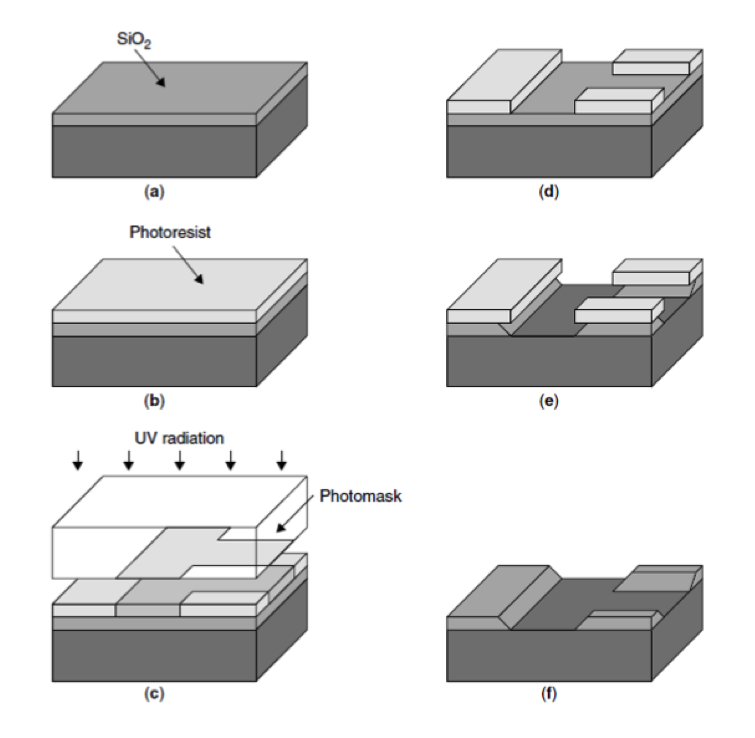
现在考虑“用光子击中”这个部分:为此,我们可以使用一个透镜系统,将图案投射到一个小得多的区域,有效地制造出一个具有所有所需特性的微小电路。通过这种方式,20世纪70年代的光学器件能够在指甲大小上安装几千个晶体管,这为芯片提供了宏观世界计算机所没有的几个关键优势:
- 更高的时钟速率(以前会受光速限制);
- 扩大量产规模的能力;
- 低得多的材料和功耗,也就是说,单位成本低很多;
除了这些直接的好处外,光刻技术还为进一步提高性能提供了一条明确的道路:你只需要将透镜系统做得更强(可以刻蚀更微小的电路),就可以用相对较少的努力制造出更小但功能相同的器件。
Dennard缩放比例定律
想想当我们将芯片做的更小时会发生什么。更小的电路所需的材料更少,更小的晶体管需要更少的时间进行状态切换(以及芯片中的所有其他物理过程),从而降低电压并提高时钟频率。
一个更详细的观察结果,被称为Dennard缩放比例定律(Dennard Scaling),表明晶体管尺寸每减小了30%,则:
- 晶体管密度加倍();
- 时钟速度提高40%();
- 并使总功率密度保持不变;
由于单位制造成本是关于面积的函数,而使用成本主要是电力成本(运行繁忙的服务器2-3年所需的电力成本大致等于芯片本身的成本),因此新一代(晶体管尺寸减少30%)的CPU芯片的总成本应该大致相同,但时钟频率要高出40%,晶体管数量翻倍。这些提升可以用于添加新指令或增加字大小,以跟上存储芯片中同样在发生的小型化趋势。
由于在设计过程中可以在能量和性能之间进行权衡,制造工艺本身的精度,如“180纳米”或“65纳米”,可以直接转化为晶体管的密度,成为CPU性能的标志。
在计算机历史的大部分时间里,光刻精度提升是性能改进的主要驱动力。英特尔前首席执行官戈登·摩尔(Gordon Moore)在1975年预测,微处理器中的晶体管数量将每两年翻一番。他的预言一直持续到今天,并被称为摩尔定律(Moore’s law)。
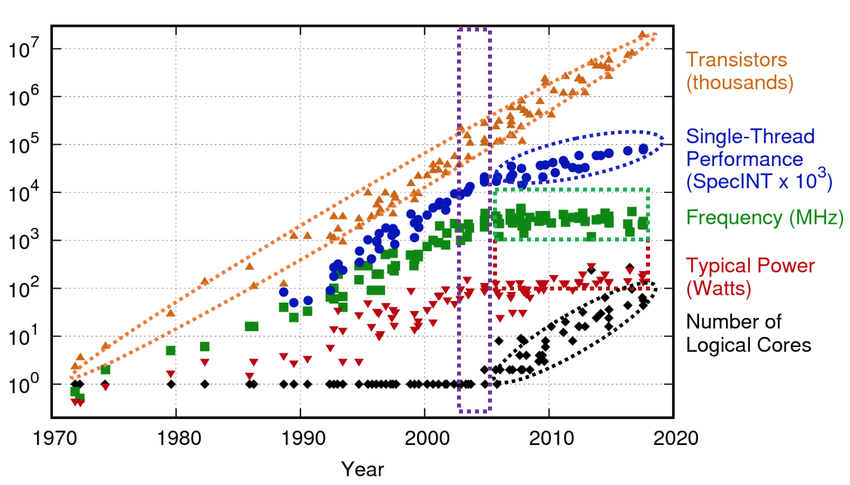
Dennard缩放比例定律和摩尔定律都不是实际的物理定律,而只是精明的工程师观察得到的经验公式。由于基本的物理限制,它们都注定会在某个时刻停止,最终的限制是硅原子的大小。事实上,由于功率问题,Dennard缩放已经触及了边界。
从热力学角度看,计算机只是一种非常高效的将电能转化为热量的设备。这种热量最终需要被去除(散热问题),而毫米级晶体的能量消耗也是有物理限制的。计算机工程师想要最大化性能,本质上只是在总功耗保持不变的前提下,选择最大可能的时钟频率。如果晶体管变小,它们的电容就会变小,这意味着翻转晶体管所需的电压会变小,状态切换会更快,从而增加了时钟频率。
2005–2007年左右,由于泄漏(leakage)效应的出现,这一策略失效了:电路特征变得如此之小,以至于它们的磁场开始使相邻电路中的电子向它们不应该的方向移动,从而导致不必要的发热和偶现的位翻转(bit flipping)。
缓解这种问题的唯一方法是增加电压;但为了平衡功耗,你又需要降低时钟频率,这反过来会使整个过程随着晶体管密度的增加而收益逐渐减少。在某个时刻,时钟频率不再能够通过减小晶体管尺寸来提高,小型化趋势开始放缓。
现代计算机
Dennard缩放比例定律已经失效,但摩尔定律还没有消亡。
时钟频率的提升趋于平缓,但晶体管数量仍在增加,从而允许设计新的并行硬件电路。CPU设计不再追求更快的时钟周期,而是开始专注于在一个周期内完成更多有用的事情。晶体管并没有变小,而是在改变形状。
这导致了越来越复杂的体系结构,每个时钟周期内可以做几十、几百甚至数千种不同的事情。
AMD对Zen CPU内核的拍摄(约14亿个晶体管)如下图所示:
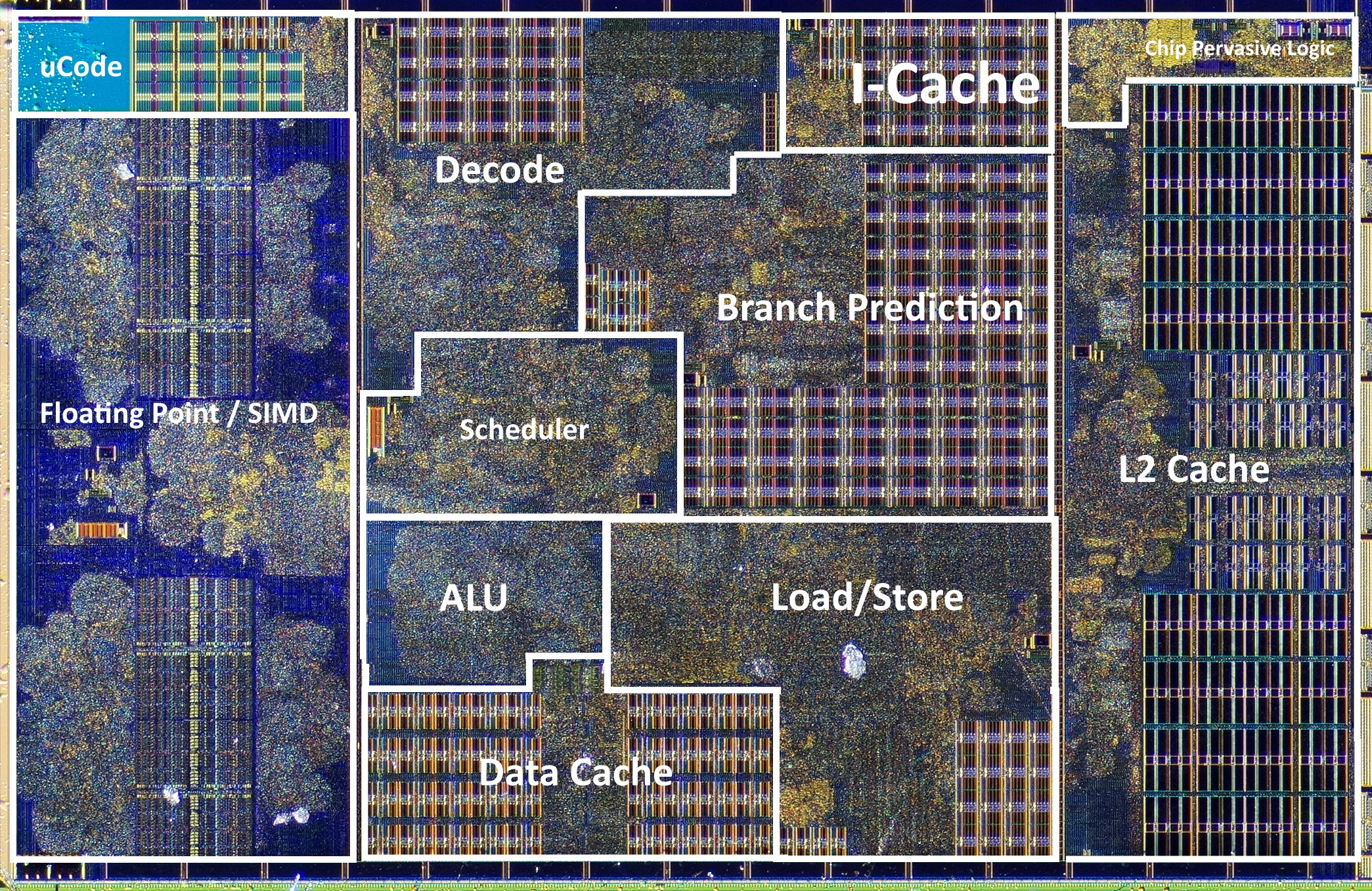
以下是一些核心的CPU性能提升方法,这些方法驱使现代计算机朝更多可用晶体管的方向设计:
- 重叠指令的执行,使CPU的不同部分保持忙碌(流水线);
- 执行下一个操作不必等待前一个操作完成(预测技术和乱序执行);
- 添加多个执行单元以同时处理独立的操作(超标量处理器,即指令多发射);
- 增加机器字(machine word)大小,以增加能够对128、256或512位为一组的数据块执行相同操作的指令(单指令多数据,SIMD);
- 在芯片上添加多级缓存,以加快RAM和外部存储(External Memory)的访问时间(存储器不完全遵循硅缩放定律);
- 在芯片上添加多个相同的核心(并行计算,GPUs);
- 在主板上使用多个芯片,在数据中心使用多台更便宜的计算机(分布式计算);
- 使用定制硬件以提高解决特定问题的芯片利用率(ASICs、FPGAs)。
对于现代计算机来说,“让我们对所有操作进行计数”的方法对预测算法性能而言,不只是有点误差,而且会有几个数量级的偏差。这需要新的计算模型和其他评估算法性能的方法。
 wechat
wechat alipay
alipay





